面试题之分布式锁相关
腾讯云后台开发 暑期实习一面
一、问题
大概题目:
一个系统,多个分布于全国的子系统,一个前端点击从各个子系统拉取数据到主系统,可能会碰到什么问题?
如果一个请求未结束,另外一个又发起,如何解决?
如果主系统前端请求,后台又有定时任务执行相同的代码逻辑,怎么处理?
交流上出了一点问题,虽然面试官一直有引导,自己还是没回答到点子上。
应该是考查分布式系统里的多个任务调度,用分布式锁来进行同步。
最后面试官说:你可以考虑用分布式锁来解决。
注:能力有限,以下是针对分布式锁的一些不太完整的总结
二、分布式锁
1、应用场景
在分布式系统里,有时执行定时任务,或者处理某些并发请求,涉及到多个进程之间的同步,需要确保多点系统里同时只有一个执行线程进行处理。分布式锁就是在分布式系统里互斥访问资源的解决方案。
2、单机锁和分布式锁的区别
单机上锁可以用一个变量表示,0表示没有线程获取锁,而1表示有线程获取锁了。加锁需要判断变量的值,如果为0,将其设置为1,释放锁需要将变量的值设置为0。分布式下,锁变量也可以用一个变量表示,不过需要用一个共享存储系统来维护变量。
所以分布式锁就有了如下要求:
- 分布式锁的加锁和释放设计多个操作,需要保证操作的原子性。
- 共享存储系统保存了锁变量,因此如果系统故障,要避免客户端无法加锁,也要保证系统的可靠性。
分布式锁的实现方案有多种,主要介绍,基于redis和mysql实现的方案。
三、基于redis实现
redis因为可以组成redis集群,所以针对redis的分布式锁可以通过添加到单个redis节点也可以添加到多个redis节点。
1、基于单个redis节点的分布式锁
用一个变量和锁变量的值分别作为键值对的键和值。
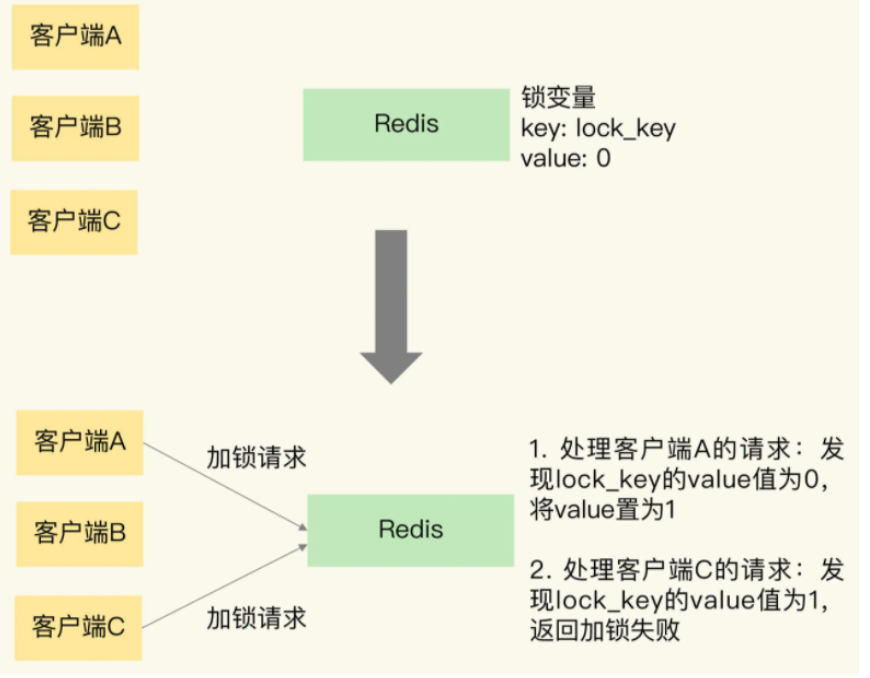
因为redis是单线程处理请求,所以即使客户端A和C的加锁请求同时发送给Redis,redis也会串行处理他们的请求。
加锁要涉及到三个操作
- 读取锁变量
- 判断锁变量的值
- 将锁变量的值设置位1
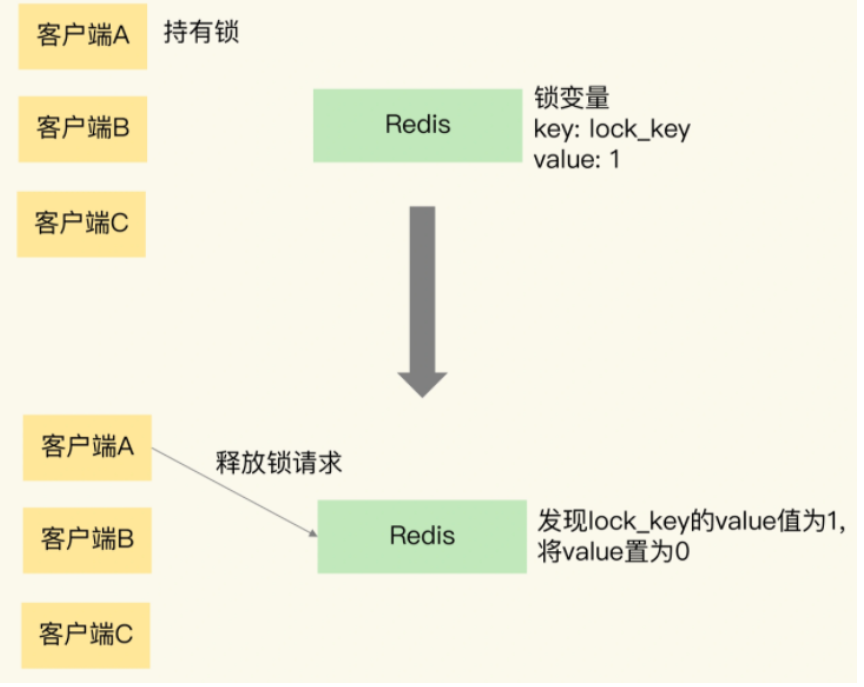
redis提供单命令SETNX要将加锁这三个操作保证原子性执行。同样DEL对应删除锁。
使用SETNX和DEL问题
- 如果加锁之后,持续占用锁,就会造成其他客户端无法获取锁因而无法访问共享数据,所以要给锁设置一个过期时间,过期即自动释放
- 比如A加锁,但是C错误发送DEL命令导致锁被错误释放。所以要使用参数区分来自不同客户端的加锁操作。
使用SET命令加参数作为加锁命令,同时参数位失效时间,客户端字符串唯一标识符。
对于释放锁使用Lua脚本,Lua脚本传入客户端标识符参数获取锁,然后释放锁。Lua脚本也保证操作原子性。
但是如果用一个redis实例保存锁,如果这个redis故障,锁变量就没了,客户端无法获取锁而阻塞业务暂停。
2、基于多个节点的高可靠redis分布式锁
按照一定的规则步骤加锁解锁。分布式锁算法。
基本思路,就是让客户端和多个独立的reids依次请求加锁,如果半数以上实例都能成功加锁,就认为可以获取分布式锁,否则失败。这样如果单个redis故障,锁变量在其他实例也有后保存,客户端仍旧可以正常锁操作。
步骤
1、客户端获取当前时间
2、客户端顺序向N个redis实例发送set命令执行加锁操作,给单个客户端发送加锁,可能加锁超时,就会和下一个redis实例请求加锁,加锁时间远远小于锁的有效时间
3、客户端和所有的redis完成加锁,就计算加锁的总耗时。
- 当从半数以上的redis都获取锁
- 获取锁的耗时小于锁的有效时间
满足以上两个条件才认为加锁成功,然后开始计算剩余有效时间,如果有效时间来不及完成操作,就释放锁,避免操作还未完成锁就过期了。释放锁同样使用lua脚本。
四、基于mysql实现
1、基于唯一索引insert实现
建立一个表,然后主键是锁的名字,获取锁就是根据锁的名字往表里插入数据。如果想往表中重复插入相同的记录,也就是重复获锁,就会因为主键冲突而报错,导致获取锁失败。
实现方式
- 获取锁时在数据库中insert一条数据,包括id、方法名(唯一索引)、线程名(用于重入)、重入计数等字段
- 获取锁如果成功则返回true
- 获取锁的动作放在while循环中,周期性尝试获取锁直到结束或者可以定义方法来限定时间内获取锁
- 释放锁的时候,delete对应的数据
优点:实现简单,容易理解。
缺点:
- 没有线程唤醒并且是非阻塞,insert插入失败表示锁获取失败,一般不会再去主动重复获取锁。
- 没有超时保护,解锁操作失败,可能导致锁记录一直在数据库中,其他线程无法再获得到锁。
- 这把锁强依赖数据库的可用性,数据库是一个单点,一旦数据库挂掉,会导致业务系统不可用。
- 这把锁是非公平锁,所有等待锁的线程凭运气去争夺锁。
2、乐观锁实现
之所以称为乐观,是基于先默认没有加锁,先去拿数据,当把修改的数据往数据库写的时候,再做判断,相当于延迟获取锁。这个过程称为CAS过程,一般是通过为数据库表添加一个 version 字段来实现读取出数据时,将此版本号一同读出之后更新时,对此版本号加1,在更新过程中,会对版本号进行比较,如果是一致的,则说明数据没有被其他线程更改,则会成功执行本次操作;如果版本号不一致,则会更新失败,放弃操作。
优点:实现也比较简单,容易理解
缺点:
- 本来只用更新数据,现在还要维护一个额外的版本号字段,对其进行比较和修改,增加了数据库额外的操作。
- 数据库有多张表,多个资源,就需要对数据都建立基于数据表的乐观锁,也就是每个资源都要有一张资源表,对数据库的开销较大。
- 多线程如果都是用乐观锁的过程中,会导致数据库中存在许多脏数据。
3、基于mysql实现的分布式锁总结
基于MySQL实现的分布式锁方案,性能上肯定是不如Redis。所以,基于Mysql实现分布式锁,适用于对性能要求不高,并且不希望因为要使用分布式锁而引入新组件。并且使用mysql分布式锁,必须保证多个服务节点使用的是同一个mysql库。
优点
- 直接借助DB简单快捷,基本每个服务都会直接连接数据库,而不是额外是用中间件,如redis。
- 如果一个客户端断线了会自动释放锁,不会造成锁一直被占用
缺点
- 加锁直接打到数据库,增加了数据库的压力;
- 锁的可用性和数据库强关联,一旦数据库挂了,则整个分布式锁不可用;可使用主从备份模式
- 直接使用DB虽然简单,但是有性能瓶颈,超时问题等
posted on 2022-05-27 22:36 weilanhanf 阅读(609) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号