Golang中的channel分析
一、channel
1、实现
使用ch := make(chan int, 5)创建一个有缓冲的channel之后,ch变成函数栈帧上的一个指针,指向堆上的实际hcann数据结构。

channel往往用于协程间的并发访问,所以要有一把锁锁住整个数据结构。
对于上述有缓冲channel需要知道的信息有:
1、已经存储的元素
2、最多存储的元素
3、每个元素占多大空间
所以channel缓冲区用一个数组实现。并且有缓冲区支持交替读写数据,因此需要两个值记录读写下标的位置。

当读和写不能立即完成。要让当前channel的协程等待,待到可以读写的时候,要能立即唤醒等待的协程。所以要有两个等待队列,分别对应读写操作,也就是发送和接受队列。

另外channel还有记录channel本身是否关闭的状态。因此channel底层的数据结构hchan结构体应该包括:类型信息,元素占用空间,元素大小,容量,发送和接受的下标值,两个等待队列,锁以及关闭状态等信息。
2、发送数据
创建ch := make(chan int, 5)则会创建一个大小为5的缓冲区。协程g1持续向缓冲区写入数据比如:
ch <- 1
ch <- 2
ch <- 3
ch <- 4
ch <- 5
ch <- 6
过程如图:
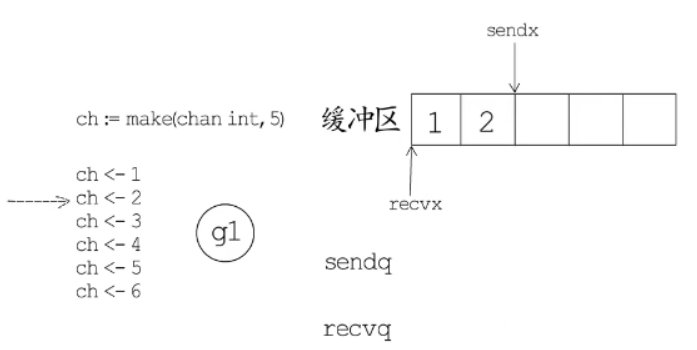
最后发送到6次数据,但是缓冲区容量只有5,缓冲区的写下标sendx会回到缓冲区首部读下标recvx的位置0,第六个元素就无处可放。发送数的协程g1就会进入ch的发送等待队列sendq中。如下图
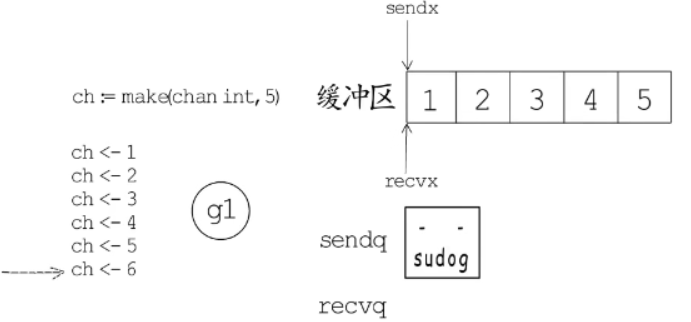
队列是基于链表实现,生成链表节点sudogo加入链表,节点信息包括:哪个协程在等待,等待的是哪个channel,等待发送的数据在哪等信息。
当有新的协程从缓冲区读取数据,读下标会前移,空出了新的缓冲区就会唤醒加入等待队列的协程g1,g1退出队列执行ch <- 6操作,把数据写入缓冲区0号位置,所以其实channel的缓冲区是一个环形缓冲区。
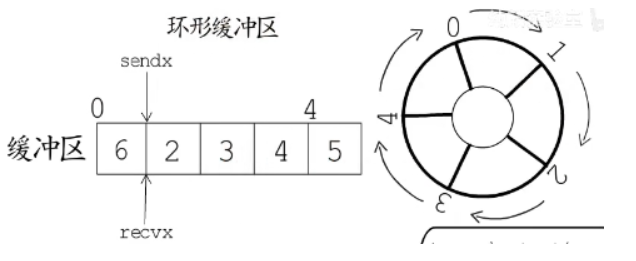
所以对于写操作时候发送数据的协程不阻塞情况有:
1、缓冲区还有空闲位置
2、有协程在等待从缓冲区接收数据
对于写操作时候发送数据的协程阻塞情况有:
1、channel为nil
2、无缓冲区且没有协程等待接收数据
3、有缓冲区,但是已用尽
为了不阻塞可以使用select机制,代码如下:
select {
case ch <- 10;
...
default:
...
}
进入select,如果检测到channel可以发送数据,执行case分支,如果不能发送数据会产生阻塞,则会进入default分支。
3、接收数据
接收数据的写法更多
1、<- ch:会将读出的结果丢弃
2、 v := <- ch:结果赋值为变量v
3、v, ok := <- ch: ok为false时候,表示ch关闭,v为channel元素类型的0值
只有在缓冲区有数据和有协程往缓冲区发送数据才不会阻塞。如果出现以下情况则会读协程发生阻塞:
1、ch为nil
2、无缓冲也无发送协程
3、有缓冲,缓冲区无数据
为了不阻塞也可以使用select机制。
二、多路select
1、select实现
以上读写操作中的select中,只有一个case分支,只针对一个channel。多路select指的就是存在两个及以上的case分支。每个分支可以使一个channel的发送或者接受操作。比如
var a, b int
b = 10
select {
case a = <- ch1;
case ch2 <- b;
default;
}
把执行上述多路select的协程称为g1,编译器会将多路select转换为对底层runtime.selectgo函数的调用,函数调用中有很多参数,比如数组cas0, 数组order0以及其他参数。
- 数组cas0:数组中存放select中的所有case分支,send在前,recv在后。
- order0数组:指向uint16类型的数组,数组容量为cas0的两倍,被用作两个数组。用来保存对case内channel轮训的顺以及加锁的顺序。轮训需要乱序保证公平性,确定加锁顺序避免死锁。
- 其他参数:包括发送分支数目nsends以及接受分支数目nrecvs,以及记录select是否需要阻塞的值block,如果有default则不会被阻塞,没有则会被阻塞。
- 函数返回值:另外函数调用也有返回值,第一个返回值为int类型对哪一个case分支被执行,如果执行default分支,则返回-1。第二个返回值为bool类型用于执行channel分支的操作时候,表示分支channel返回真实数据还是channel关闭。
2、多路select处理逻辑
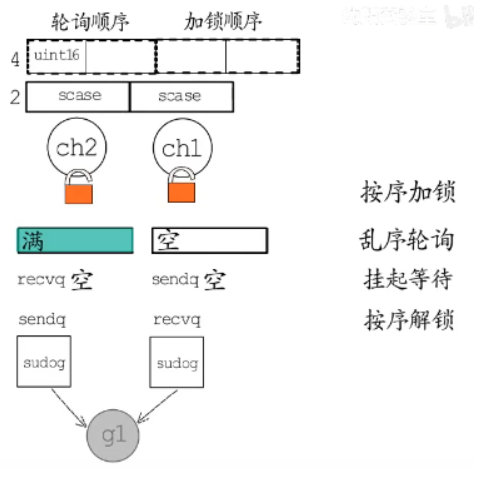
按序加锁+乱序轮训:
多路select需要进行轮训确定哪个case分支可以操作,轮训前需要先按照顺序对case中的所有channel有序加锁。然后按照乱序的轮询顺序检查channel的等待队列和缓冲区。

挂起等待+ 按序解锁:
假如检查到ch1,如果ch1中的缓冲区有数据可读,则进入对应case分支,当前协程g1拷贝数据开始执行。
假如所有channel都无法执行,就把当前协程加入到select中所有case中channel的对应发送或者接受队列中,阻塞等待。然后g1会挂起,按序解锁所有channel对应的锁。
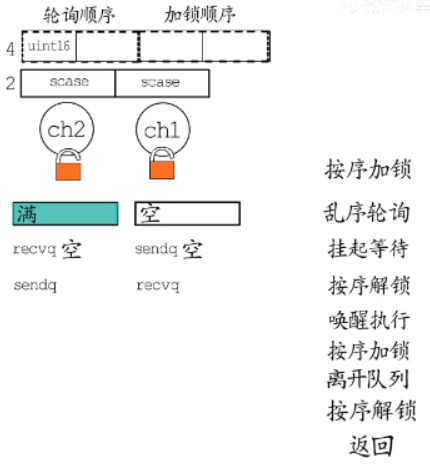
按序加锁+离开队列+上锁+返回:
假如接下来有数据可用,g1的就会被唤醒执行对应分支。执行之后,将自己再次按序加锁,接着从对应的队列中将自己移除,再次对channel上锁后返回。
三、应用及问题
1、生产者消费者模型
channel可以用来作为两个协程通信,常用的应用比如生产者消费者模型,上游的生产者生产数据写入缓冲区,下游的消费者从缓冲区中读取数据,这个缓冲区可以用channel实现。从而解决了并发,解耦和缓存等问题。
比如实际应用中,同时访问同一个公共区域,同时进行不同的操作。都可以划分为生产者消费者模型,比如订单系统。很多用户的订单下达之后,放入缓冲区或者队列中,然后系统从缓冲区中去读来真正处理。系统不必开辟多个线程来对应处理多个用户的订单,减少系统并发的负担。通过生产者消费者模式,将订单系统与仓库管理系统隔离开,且用户可以随时下单(生产数据)。如果订单系统直接调用仓库系统,那么用户单击下订单按钮后,要等到仓库系统的结果返回。这样速度会很慢。
也就是:用户变成了生产者,处理订单管理系统变成了消费者。
相关链接:生产者消费者模型及go实现
2、内存泄漏
在一.2,一.3中的对缓冲读写操作都需要协程执行,但是如果协程创建之后,因为缓冲区空或者死锁等情况,协程阻塞持续不释放,go很难判断这些阻塞是人为的还是出现故障,也难判断这些协程的阻塞是暂时的还是永久的,所以不会主动去释放阻塞的协程而造成永久阻塞,而程序还在不断创建新的协程,就会造成内存持续泄漏,严重的话最终程序崩溃。
四、总结
主要介绍了如下:
- channel的底层数据结构对应哪些信息
- channel中缓冲区其实是环状缓冲区以及等待队列
- 读写下的阻塞和非阻塞操作
- 多路select的用法和处理逻辑
注:以上仅作为幼麟实验室Golang学习笔记,总结有错误谅解。视频链接
posted on 2022-02-25 14:11 weilanhanf 阅读(688) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号