可用性质量属性设计之系统设计
您可参考右侧导航栏了解博文涉及内容。
一、故障,错误,BUG的区别
在了解一个系统的可用性可以从了解系统故障开始。但是什么是故障,错误,bug?
故障与错误是经常容易被混淆的两个概念,故障、错误、BUG之间是有区别的。
- 软件代码由于人为因素写错了或者考虑不周全,成为了错误。
- 有错误的软件存在一定缺陷,该缺陷在某种情况下可以转化为故障。
- 产生了故障,人们就认为系统出 BUG了。
错误是最原始的驱动力,一个错误不一定导致故障,因此错误不见得被人们察觉。但是,一旦错误变为故障,人们是可以通过软件的外在表现而察觉。故障是系统出错后导致系统不正常工作的结果,故障从某种意义上来说属于现象。即通过故障这种现象,人们可以知道软件存在BUG,最终找到相关错误点,并对错误代码进行修复。BUG 是被激发出来的错误,是故障的总称,因此一个系统实际存在的错误数比BUG 数要多,因为只有被激发出来的错误才能成为BUG。
那么如果要设计一个可靠性非常高的系统,或者系统中的一个可用性非常高的模块或者子系统该怎么设计呢?围绕以下以下几个问题
- 如何检测故障:系统出现故障时,可以通过系统故障的外在可见性了解到系统出现BUG,也就是检测系统的是否处于故障状态;
- 故障发生会有什么情况:系统故障发生后,会对系统产生什么样的影响。怎么让故障被系统管理员所知道;
- 如何应对故障:系统故障后,能够自动化地改变策略,故障处理,维持系统的可用性。
二、故障检测
要提升系统的可用性,就要先检验系统是否处于故障状态。
1、ping与echo战术
ping与echo战术是错误检测的常用方法。这里的ping可以对应着window或者linux的ping命令理解,检查网络是否连通,可以很好地帮助我们分析和判定网络故障。在错误检测中,使用ping和echo就是外部模块,向需要的模块发送请求即ping消息,然后被检测的模块返回相应的状态信息echo信息。通过信息了解到被检测的模块状态。如果被监测方在预期的时间内无法返回相应的消息,则在进行几次ping消息发送(能尽量避免因网络问题误判的情况),如果仍无法返回信息,即可确认为出错。
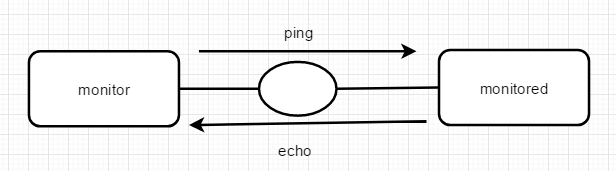
ping和echo示意图
monitor向monitored组件发送ping命令,然后monitored返回echo信息(或无法返回,直接认定monitored端所在的系统错误),monitor根据echo信息判断monitored的系统是否正常运行。monitor与monitored不仅可以在不同系统,也可以属于同一系统的不同模块。
2、Heartbeat战术
在使用ping和echo作为错误检测战术的系统中,总是由需要两端即客户端发送ping,服务端发送echo发送消息保障系统错误检测的正常执行,那么能否一端发送信息呢?那就是心跳战术Heartbeats。
Heartbeat的发起者是被检测者自身,定期发送Heartbeat消息向外界表示其本身正在处于正常运行的状态。由于信息的发送是每隔一段时间发送一次,类似人的心跳,所以被称为心跳战术。
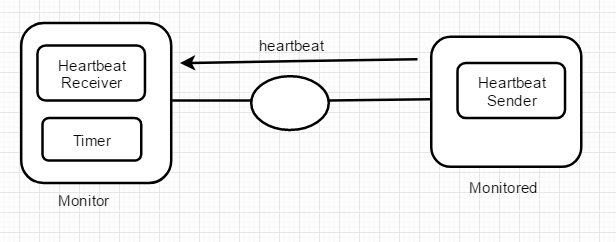
Heartbeat示意图
需要注意的是:Timer的作用是记录消息是否超时,所以在每一次接受Heartbeat消息之后,都需要立即停止一个定时器的工作,同时开启新的计时器。如果Timer超过规定时间,则进行诊断。
右侧Monitored向左侧Monitor发送心跳信息,如果左端Timer即使测发现消息超时,甚至无法收到消息则判定Monitored端故障。仅仅使用Heartbeat很可能会造成误判,也就是heartbeat因为某种传输原因,没能到达Monitor端,那么Monitor就直接认定被检测的系统是故障的吗?显然不合适,所以使用ping和heartbeat组合。
补充:除了ping和heartbeat常用的故障检测还有在多数语言中都存在的异常捕获——异常处理机制,异常出错后,会上报信息,那么异常处理程序会根据具体的出错信息对其进行相应的处理,一般同属于一个进程或一个线程。
常见如Python:
try:
语句
except:
出错处理
3、ping与heartbeat组合使用
Heartbeat与Ping经常配合使用能提升错误检测的效果。 在正常情况下,通过Heartbeat 消息监测系统的状态,当 Heartbeat 消息消失后,可利用 Ping消息做二次确认,若Ping消息也没有得到反馈,此时可判定相关模块出现故障。
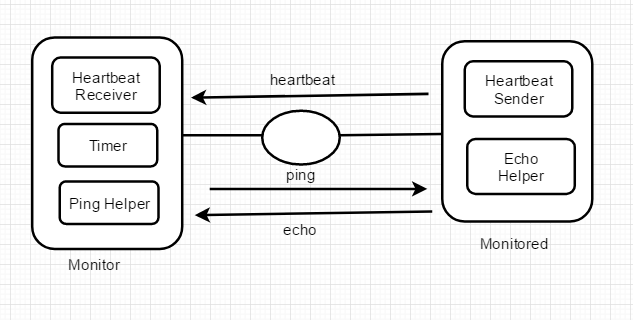
HeartBeat与ping的混合使用示意图
图中增加了相应的 Ping和Echo 的支持模块,这此模Heartbeat 消息超时时被调用,即当计时器超时,左侧模块将发送 Ping 消息,同时启动新的计时器等待 Echo 的到来。若在超时前接收到了 Echo消息,则说明右侧模块并没有失效,反之则判断右侧模块失效。
流程图:
Heartbeat发送端流程图
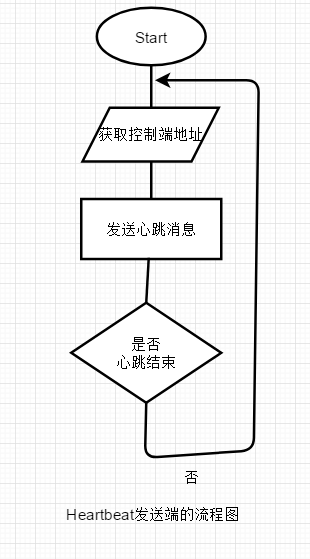
Heartbeat接收端流程图(监控端)

由于系统可能是分布式的,或者监控和被监控的系统分属于不同的系统,所以在流程图中,可以看到在消息的发送端,还需要获取相应的IP地址和端口号。
三、如何处理网络对消息的影响
无论是ping还是heartbeat战术都无法避免一个问题:如何确认echo或者heartbeat消息是因为真正的系统故障还是因为网络传输过程中失效。即如何避免误判系统故障或者降低误判的几率。
如果被检测的系统没有故障,而在向监测端发送消息的时候,由于网络故障问题,监测端没有接受到信息,那么监测端误认为系统故障,就会采取相应的故障处理策略,这种处理本来是没有必要的,是消耗资源的。
网络存在着一定的延时或其他问题,并不是所有的 Heartbeat消息都能准时、周期性的到达,实际系统不能简单地以一个Heartbeat 消息超时或未到达为依据做出系统失效的判断。因此可以采取两种 Heartbeat 消息的判定方法。
1、设置超时时间和最大超时次数
第一种判定方法。设定一个超时时间 TIME OUT 与最大超时次数 MAX TIME OUT,建议MAX_TIME OUT=3.
判定系失效方法:
- 在发送消息之后的3次超时计数过程中,只要接收到回应,就判定系统未失效。
- 如果在发送消息之后的3次超时计数过程中监听组件都没有收到回应,判定系统失效。
2、超时消息重传
第二种判定方法参考TCP 的超时重传机制,让监听组件具有发送ACK消息的功能,ACK 消息带有序号,监听组件发送ACK消息之后,响应组件接收到 ACK 消息后才发回 Heartbeat消 息,Heartbeat 消息也带有序号,且应与对应的 ACK 消息的序号相同。另外设定一个超时时间TIME OUT和一个最大无响应次数 MAX NO RESPONSE,建议 MAX NO RESPONSE=3.
判定系统未失效方法:
- 连续3次发送ACK消息之后至少有1次得到相同序号的 Heartbeat消息响应,判定系统未失效。
判定系统失效方法:
- 连续3 次发送 ACK 消息之后在 TIME OUT 时间内无相同序号的 Heartbeat消息响应,判定系统失效。
** 注**:这里并不能完全解决系统故障误判的问题,只是利用现有手段最大程度解决这一问题。
四、系统设计
解决了网络对消息传输的作用对系统故障的影响,那么如何使用Heartbeat与ping结合设计一个主备份的系统呢?更进一步即确认故障之后如何处理呢?
下面给出主从备份系统的示意图

备份复件需要检测主复件的状态信息,所以主复件问备份复件定时发送 Heartbeat 消息用于告知备份复件相关状态信息。备份复件在收到每个Heartbeat 消息之后,启动新的计时器,若计时器超时仍未收到下一个 Heartbeat 消息,则备份附件进人确认阶段。备份复件发送 Ping 消息,并且启动新的计时器,若在新的计时器超时仍未收到明主复件故障,然后备份复件代替主复件接管所有工作,所有的客户主复件的 Echo 信息,则付与原来的备件复件进行通信,此时 需要通知管理人员主备切换的消息,便于管理人员设置新的备件,以保障未来的正常切换。
因此以上分析知道,在确认被检测系统出错之后,为保证系统的持续可用性(这也是本博重点讨论的问题),接下来的处理是找到备份系统接管当前系统或模块的所有工作,并自动化通知相关管理人员做进一步操作。
具体实现可以使用主动冗余这一错误恢复战术。
五、主动冗余
1、原理
主动冗余中所有冗余组件在启动的时候同步,以并行的方式对时间作出响应,因而它们都处 在相同的状态。通常,作出响应的第一个组件的结果被采用,其他响应被丢弃。 组件间的同步是通过将传递给被冗余组件的全部消息发送给所有冗余组件。发生错误时,使用该战术的系统停机时间通常是几毫秒。恢复时间就是组件间的切换时间,因为冗余组件间状态一致,各组件接收到的都是最新的消息,并且拥有之前的所有状态。此处的冗余组件一般是指模块,但实际还可能包括通信链路。 在可用性要求非常高的分布式系统中,如通信核心网,冗余组 件包括通信路径。这一极度契合了为高可用系统设计的要求。
2、代价
主动冗余是一种高可靠性的设计,由原理可知,冗余中所有组件都处于并行运行状态下,所以一般应用对系统可靠性要求非常高的情况,且其工作代价也比较高。
从硬件成本上来看,需要双份系统的硬件要求,从软件上看,需要一套高效的心跳监测和倒换机制,以及状态同步的机制。
3、示意图
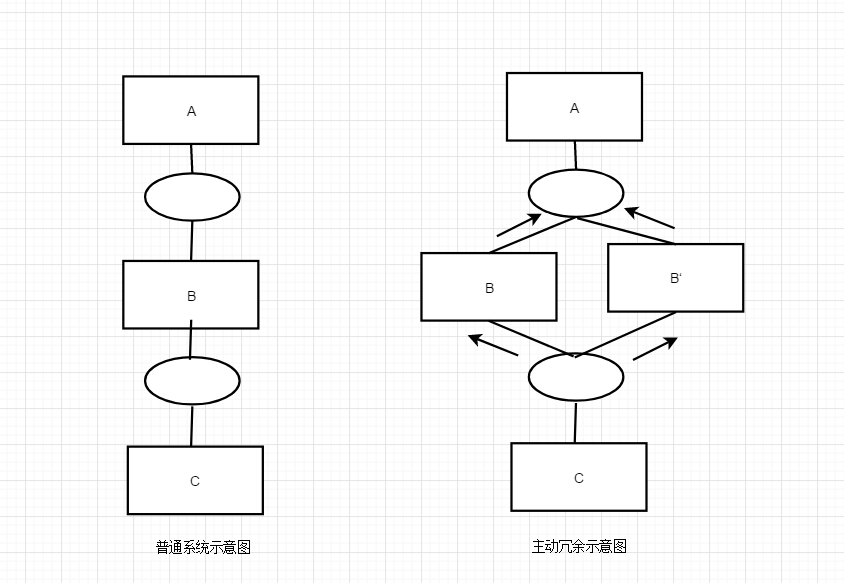
B与B'同时接收C的请求并且进行同样的操作, 但是,只有B向A发送处理完的结果。相当于B'的处理结果在平常状态下将被丢弃。此时, 若B出现故障,则B'将直接接替B的工作。由于B'的运行状况与B几乎一致,B'可快速接替B的工作。B和B'的这种工作模式就是一种主动冗余的方式。
因此可以看出:主动冗余的优点是切换时间非常短,数据和计算都是热备份的。所以一旦系统出现错误,就可以立刻切换,基本不会影响系统的正常运行。但缺点也十分明显,所有的冗余模块都处于激活状态,并指向相同的任务,即使在主系统没有故障的情况下仍需要对请求做同样的处理,从而保障所有模块的运行结果一致性。就造成了资源的成倍增加。
4、比较
主动冗余,和被动冗余和备份是不同的存在,被动冗余不像主动冗余一样一直进行计算,实现也更简单,因而也对系统的可用性保证更低。而备份则是更为低级别的错误恢复方式。
- 实现容易程度:备份>被动冗余>主动冗余
- 资源消耗程度:主动冗余>被动冗余>备份
- 可用性保证程度:主动冗余>被动冗余>备份
具体怎么选择策略还需要具体情况具体分析。
posted on 2019-07-08 22:16 weilanhanf 阅读(2412) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号