网络爬虫之数据存储CSV实战(二)
数据存储也是网络爬虫的一部分,获取到的数据可以存储到本地的文件如CSV,EXCEL,TXT等文件,当然也是可以存储到
mongodb,MySQL等数据库。存储的目的是为了获取数据后,对数据进行分析,和依据数据的基础上得出一个结论或者得到一个信
息。真实的世界充满了太多的不确定性,如何能够让自己的决策能够更加准确,就需要数据来参考。本文章中主要介绍CSV文件的
处理。在Python中对CSV文件的处理已经有了标准库csv,直接倒入就可以使用了。不需要单独额外的安装。
读取CSV文件从两个维度,一个是以字典的方式读取数据,另外一个是以字典的方式读取数据,下面还是以具体的案例来说明
这部分的案例应用。首先创建一个CSV的文件,文件的内容如下

如上内容是自己“Python接口自动化测试实战”课程在各个平台的数据情况,当然关注在并不这里,刚才说到,读取CSV文件可以使用
列表或者字典的方式读取。先来看列表方式的读取,见如下的案例代码:
#!/usr/bin/python3 #coding:utf-8 import csv def readCsvList(): with open('blog.csv','r',encoding='gbk') as f: reader=csv.reader(f) next(reader) for item in reader: #对列表里面的数据再次进行循环 for i in item: print(i) if __name__ == '__main__': readCsvList()
读取文件的时候特别要注意,对编码要进行处理,要不就会出现编码的问题,这地方是gbk编码处理的,如果是utf-8就是不可以的,
见编码错误信息:
Traceback (most recent call last): File "/Applications/code/stack/webCrawler/dataStorage/csvFile/blogCSV.py", line 18, in <module> readCsvList() File "/Applications/code/stack/webCrawler/dataStorage/csvFile/blogCSV.py", line 11, in readCsvList next(reader) File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/codecs.py", line 322, in decode (result, consumed) = self._buffer_decode(data, self.errors, final) UnicodeDecodeError: 'utf-8' codec can't decode byte 0xbf in position 6: invalid start byte Process finished with exit code 1
那么到底按哪个编码来读取文件的内容了,一般是utf-8或者是gbk,也有可能是gb2312,这地方是gbk,要特别的注意,下面来看读取的
文件内容,见代码执行后,返回的结果内容:

下面再来看字典的读取方式,字典的读取方式是专门有个方法,该方法为DictResader,具体见如下的案例代码:
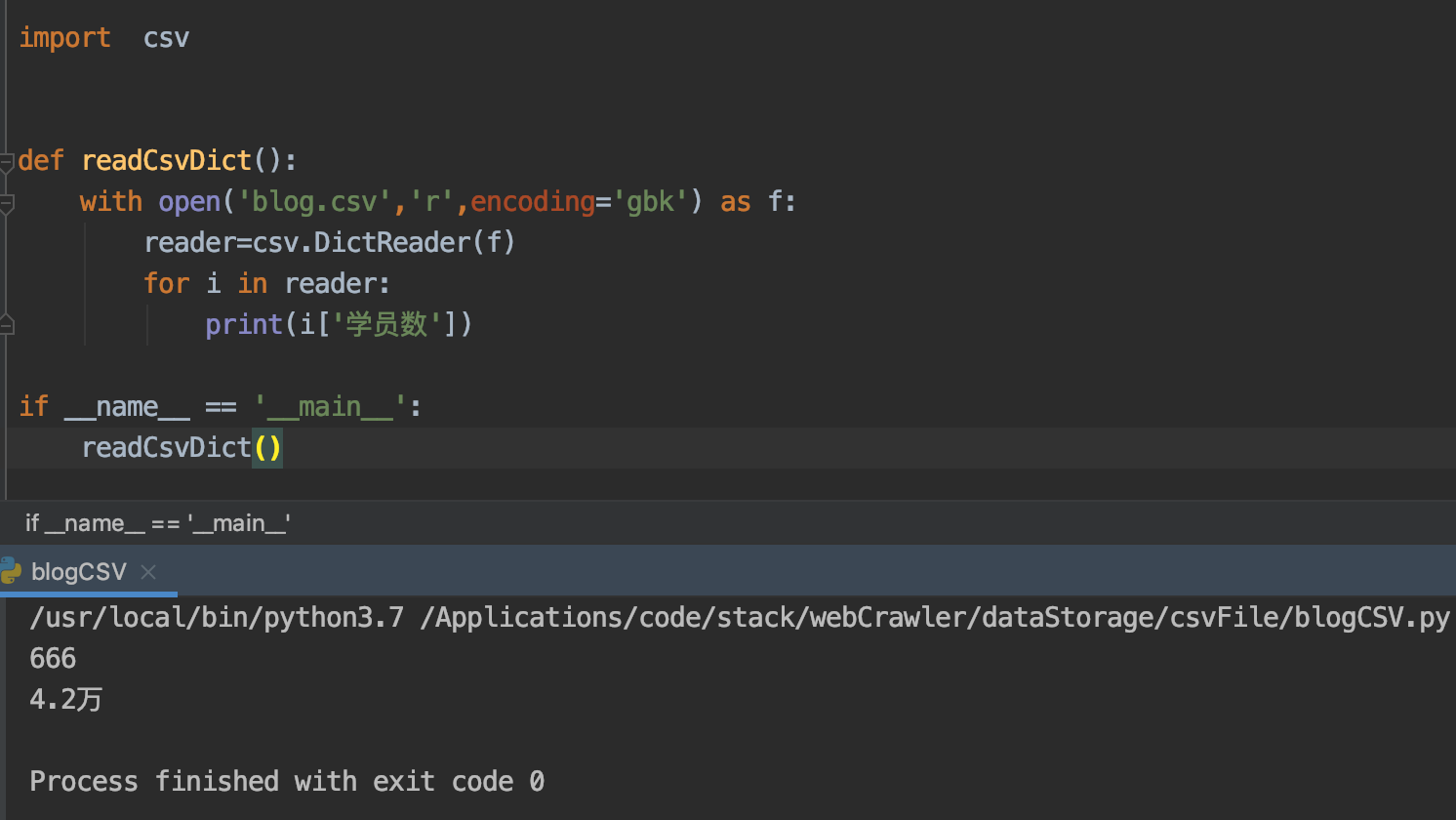
#!/usr/bin/python3 #coding:utf-8 import csv def readCsvDict(): with open('blog.csv','r',encoding='gbk') as f: reader=csv.DictReader(f) for item in reader: print(item) if __name__ == '__main__': readCsvList()
见执行如上的代码后,输出的结果信息:
OrderedDict([('平台', '网易云课堂'), ('课程名称', '接口测试实战'), ('学员数', '666'), ('备注', '购买人数')]) OrderedDict([('平台', '51CTO'), ('课程名称', '接口测试实战'), ('学员数', '4.2万'), ('备注', '包含了购买人数和非购买人数')])
这个结果可能让很多人感觉到模糊,不要着急,假设要取出学员数, 那么只需要在item['学员数'],其他的也是如此,修改
后的代码为:
CSV数据的存储也可以从两个维度进行,分别以列表的形式存储和字典的形式存储,下面就依据案例分别编写这两点,首先
以列表的方式存储数据,实现的代码如下:
#!/usr/bin/python3 #coding:utf-8 import csv def csvWriteList(): '''列表的方式写文件''' # 头部信息,也就是文件的每一栏的标题 headers = ['姓名', '年龄', '地址'] # 要写入的数据 values = [ ('无涯', '18', '西安市'), ('学海', '20', '兰州市'), ('无涯课堂', '25', '天水市') ] with open('csvWrite.csv','w',encoding='utf-8',newline='') as f: writer=csv.writer(f) #写入文件的标题 writer.writerow(headers) #一行一行的写入文件 for i in values: writer.writerow(i) # #一次性写入所有的文件 # writer.writerows(values)
但是写入文件需要考虑性能的问题,也就是一次性批量写入还是一行一行写入,各自都有好处,但是假设是10万数据,
使用批量的写入方法不是很明智的方法。要考虑性能,和占用资源的情况。下面演示按字典的方式写入数据,案例代码
如下:
#!/usr/bin/python3 #coding:utf-8 import csv def csvWriterDict(): '''通过字典的方式写入文件''' # 头部信息,也就是文件的每一栏的标题 headers = ['姓名', '年龄', '地址'] # 字典存储的数据 dictValues = [ {'姓名': '无涯', '年龄': 18, '地址': '西安市'}, {'姓名': 'weike', '年龄': 18, '地址': '兰州市'}, {'姓名': '李鹏举', '年龄': 20, '地址': '西安市'} ] with open('csvWrite.csv','w',encoding='utf-8',newline='') as f: w=csv.DictWriter(f,headers) #写入表头数据 w.writeheader() # #批量写入进去 # w.writerows(dictValues) # 一行一行写入进去 for item in dictValues: w.writerow(item)
执行代码后,就会写入到文件中。下面还是来一个真实的案例,获取拉勾网平台的招聘数据,写入到CSV的文件中,实现的思路是:
1、对拉勾网的职位进行搜索,搜索的关键字是“自动化测试工程师”
2、搜索请求参数中pn是页数,可以设置为参数
3、获取搜索后的结果,然后取出职位数的ID,存储到一个文件中
4、然后对职位详情页进行请求并获取数据,地址是根据每个职位ID拼接处理
5、获取数据后,写入到文件中
#!/usr/bin/python3 #coding:utf-8 import requests import json import time as t from lxml import etree import csv def getJobheaders(): '''搜索职位的请求头''' headers={ 'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.36', 'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8', 'Origin':'https: // www.lagou.com', 'Referer':'https://www.lagou.com/jobs/list_%E8%87%AA%E5%8A%A8%E5%8C%96%E6%B5%8B%E8%AF%95%E5%B7%A5%E7%A8%8B%E5%B8%88?city=%E5%85%A8%E5%9B%BD&cl=false&fromSearch=true&labelWords=&suginput=', 'Cookie':'_ga=GA1.2.1192073820.1565486994; user_trace_token=20190811092953-851f62ea-bbd7-11e9-8906-525400f775ce; LGUID=20190811092953-851f65d0-bbd7-11e9-8906-525400f775ce; index_location_city=%E5%85%A8%E5%9B%BD; JSESSIONID=ABAAABAAAGGABCB35FA864886DD2BAEEFDB94595BC2DB5A; WEBTJ-ID=20190830205208-16ce29543e6199-0ecc63db49e95a-3c375c0f-1049088-16ce29543e7433; _gid=GA1.2.1058121822.1567169529; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1565620074,1566093141,1566829327,1567169529; LGSID=20190830205211-fb88e64d-cb24-11e9-a507-5254005c3644; TG-TRACK-CODE=search_code; X_MIDDLE_TOKEN=93daa38912eef026a719c606c8f48874; LG_LOGIN_USER_ID=81c825d19f1d590973e2acc67ec2324294ac102b1d91fc82; LG_HAS_LOGIN=1; _putrc=0057C29638877881; login=true; unick=%E6%9D%8E%E6%97%BA%E5%B9%B3; showExpriedIndex=1; showExpriedCompanyHome=1; showExpriedMyPublish=1; hasDeliver=23; gate_login_token=7ad3d7167400b40b956fb0e4050d1b61fd4a35d9831de958; privacyPolicyPopup=false; _gat=1; SEARCH_ID=07fa8207c04341b29a45f1470e653ba1; X_HTTP_TOKEN=c83880c5c002968c3106717651cf8ec4c2f46da814; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1567176013; LGRID=20190830224014-13c7f49a-cb34-11e9-8dd4-525400f775ce' } return headers def data(page=1): '''请求参数''' dict1={ 'first':False, 'pn':page,'kd':'自动化测试工程师', 'sid':'2688435b6e5b41f4b4d03f02345b7e52'} return dict1 def get_so_laGou_list(): positionIds=[] for i in range(1,30): r=requests.post( url='https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false', data=data(page=i),headers=getJobheaders()) t.sleep(10) for item in range(15): positionid=r.json()['content']['positionResult']['result'][item]['positionId'] positionIds.append(positionid) print(positionIds) json.dump(positionIds, open('positionID.json', 'w')) def getJobDetailHeader(): headers={ 'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.36', 'Cookie':'_ga=GA1.2.1192073820.1565486994; user_trace_token=20190811092953-851f62ea-bbd7-11e9-8906-525400f775ce; LGUID=20190811092953-851f65d0-bbd7-11e9-8906-525400f775ce; index_location_city=%E5%85%A8%E5%9B%BD; JSESSIONID=ABAAABAAAGGABCB35FA864886DD2BAEEFDB94595BC2DB5A; WEBTJ-ID=20190830205208-16ce29543e6199-0ecc63db49e95a-3c375c0f-1049088-16ce29543e7433; _gid=GA1.2.1058121822.1567169529; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1565620074,1566093141,1566829327,1567169529; LGSID=20190830205211-fb88e64d-cb24-11e9-a507-5254005c3644; TG-TRACK-CODE=search_code; X_MIDDLE_TOKEN=93daa38912eef026a719c606c8f48874; LG_LOGIN_USER_ID=81c825d19f1d590973e2acc67ec2324294ac102b1d91fc82; LG_HAS_LOGIN=1; _putrc=0057C29638877881; login=true; unick=%E6%9D%8E%E6%97%BA%E5%B9%B3; showExpriedIndex=1; showExpriedCompanyHome=1; showExpriedMyPublish=1; hasDeliver=23; gate_login_token=7ad3d7167400b40b956fb0e4050d1b61fd4a35d9831de958; privacyPolicyPopup=false; _gat=1; SEARCH_ID=fe3e56266ef54783a3c04b8844a8267f; X_HTTP_TOKEN=c83880c5c002968c6256717651cf8ec4c2f46da814; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1567176526; LGRID=20190830224846-44fd9886-cb35-11e9-a507-5254005c3644' } return headers def get_job_laGou_detail(): '''获取详情页的招聘数据''' positionsList=[] positions=json.loads(open('positionID.json','r').read()) for i in positions: r=requests.get(url='https://www.lagou.com/jobs/{0}.html'.format(i),headers=getJobDetailHeader()) html=r.content.decode('utf-8') html=etree.HTML(html,parser=etree.HTMLParser(encoding='utf-8')) titles=html.xpath('//h2[@class="name"]/text()')[0] salary=html.xpath('//span[@class="salary"]/text()')[0] jobRequestLists=html.xpath('//dd[@class="job_request"]/h3/span/text()') address=str(jobRequestLists[1]).replace('/','').strip() experience = str(jobRequestLists[2]).replace('/', '').strip() degree=str(jobRequestLists[3]).replace('/','').strip() company=html.xpath('//em[@class="fl-cn"]/text()')[0] company=str(company).strip() descriptions=html.xpath('//dd[@class="job_bt"]/div[@class="job-detail"]/p/text()') jobDescription='' for i in descriptions: jobDescription+=i position={ '职位':titles, '薪资':salary, '地区':address, '工作经验':experience, '学历':degree, '公司':company, '岗位要求':jobDescription } positionsList.append(position) t.sleep(3) #写入到CSV的文件中 csvHeader=['职位','薪资','地区','工作经验','学历','公司','岗位要求'] with open('laGou.csv','w',encoding='gbk',newline='') as f: w=csv.DictWriter(f,csvHeader) w.writeheader(positionsList) w.writerows() # #一行一行的写文件 # for item in positionsList: # w.writerow(item) if __name__ == '__main__': get_job_laGou_detail()
代码并非最终版,中间有很多的异常需要处理的,后续再修改和完善。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号