Python之协程(二十九)
线程是CPU分配的最小单位,而进程是线程分配的最小单位,只要在线程里面的代码,才会被
CPU所执行。由于在Python的语言中,不管启动多少个线程,只能轮流被一个CPU所调度和执行,
不能像其他语言一样启动多个线程被N个CPU执行,这就是Python线程的缺陷,基于这个缺陷,也
就有了协程,在Python的语言中,线程的切换是由CPU来完成,而协程的切换是由Python代码来
切换的,这样比起线程来说,协程消耗的资源会非常小,它的控制层面完全是在用户层面控制的,
所以更加灵活。在协程中任务切换的原则是一旦遇到任务堵塞,就立刻切换,毫不犹豫,这样保证
任务一直能够执行的,除非假设一种情况就是所有的任务都堵塞,无法执行,这种情况也是存在,
但是基本出现的少。在Python中,使用协程的库分别是gevent,asyncio,下面就结合具体的案例来
说明这部分的应用。
在gevent的库里面,切换任务使用的是switch,它的优点是规避IO的操作,这样就结合访问一个
网站系统,来看协程的案例应用,假设一个网站可以访问,另外一个不可以访问,来看应用,案例
代码如下:
#!/usr/bin/env python # -*-coding:utf-8 -*- import gevent import time as t from gevent import monkey monkey.patch_all() import requests def get_wuya(): print('开始访问无涯课堂') r=requests.get('http://www.wuya.com') print(r.status_code) print('访问无涯课堂结束') def get_baidu(): print('开始访问百度') t.sleep(2) r=requests.get('http://www.baidu.com') print(r.status_code) print('访问百度结束') g1=gevent.spawn(get_wuya) g2=gevent.spawn(get_baidu) g1.join() g2.join()
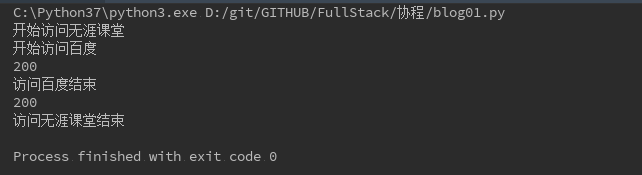
在上面的案例代码中,先执行访问无涯课堂的代码,后执行访问百度的代码,而且在访问百度代码的时候,刻意
加了等待2秒的时间,但是很遗憾的是访问无涯课堂的时候,网址不存在,导致堵塞,任务就立刻切换到访问百度,
执行完访问百度后,再任务切换到执行访问无涯课堂,以及任务结束。代码gevent.spawn()是创建一个协程任务,
遇到任务堵塞就切换,g1.join()是直到g1任务执行完成为止,见执行上面代码后,协程的任务切换,见执行结果截图:
当然有一种更加简单的方式来处理join,也就是说可以使用列表的方式来进行处理,修改代码的代码:
#!/usr/bin/env python # -*-coding:utf-8 -*- import gevent import time as t from gevent import monkey monkey.patch_all() import requests def get_wuya(): print('开始访问无涯课堂') r=requests.get('http://www.wuya.com') print(r.status_code) print('访问无涯课堂结束') def get_baidu(): print('开始访问百度') t.sleep(2) r=requests.get('http://www.baidu.com') print(r.status_code) print('访问百度结束') g1=gevent.spawn(get_wuya) g2=gevent.spawn(get_baidu) gevent.joinall([g1,g2])
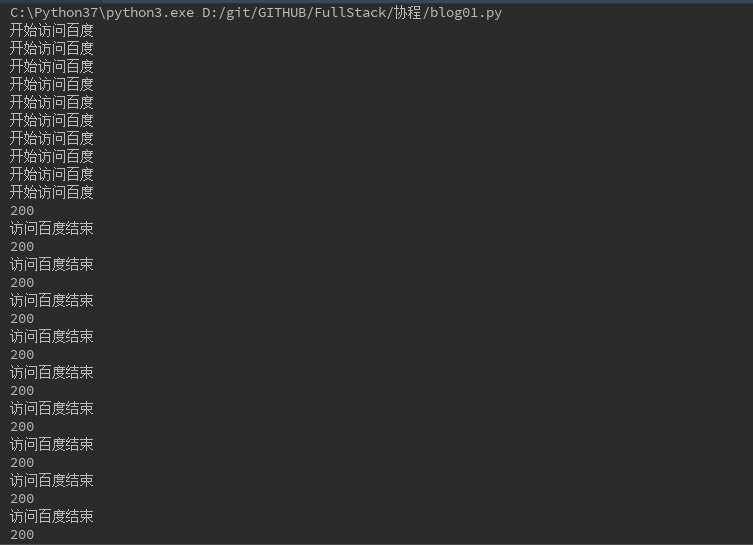
如果想在协程中实现对百度请求的并发请求,那么实现的源码为:
#!/usr/bin/env python # -*-coding:utf-8 -*- import gevent import time as t from gevent import monkey monkey.patch_all() import requests def get_baidu(): print('开始访问百度') r=requests.get('http://www.baidu.com') print(r.status_code) print('访问百度结束') gevent_tasks=[] for i in range(10): g1=gevent.spawn(get_baidu) gevent_tasks.append(g1) gevent.joinall(gevent_tasks)
见执行代码后,执行的结果截图:
实现协程的思想来请求两个页面,一个堵塞了(可能是超时,可能是未知原因),就立刻切换到另外一个任务中执行,见实现的案例
代码:
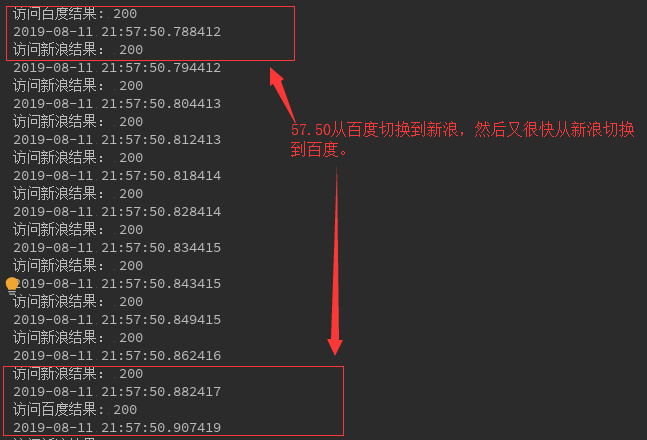
#!/usr/bin/env python # -*-coding:utf-8 -*- import gevent import time as t from gevent import monkey monkey.patch_all() import requests def get_sina(): r=requests.get('http://www.sina.com') print('访问新浪结果:',r.status_code) def get_baidu(): r=requests.get('http://www.baidu.com') print('访问百度结果:',r.status_code) gevent_tasks=[] for i in range(100): g1=gevent.spawn(get_baidu) g2=gevent.spawn(get_sina) gevent_tasks.append(g1) gevent_tasks.append(g2) gevent.joinall(gevent_tasks)
思想就是:最先访问百度,当访问百度堵塞,就立刻切换到访问新浪,如果访问新浪堵塞,也就立刻切换到访问百度,直到
任务执行结束,见执行过程的部分切换结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号