Flask中操作数据库(十)
在Flask的应用程序中会使用到sqlarchemy来管理数据库,orm具有如下的几个优点,分别是:
1、灵活性好,它支持原生的SQL语句,但是使用更多的是高层对象来操作数据库。
2、提升效率,从高层对象转换成SQL会牺牲一部分的性能,但是牺牲的这些性能基本可以忽略
不计,反而它会为程序的操作带来很大的效率提升; 。
3、可移植性好,ORM支持多种DBMS,分别如MySQL等数据库。
在实际的开发工作中,与数据库的交互是最常见的交互,那么本文章主要来总结在Flask
应用程序中连接MySQL数据库的操作。在Flask的应用程序中,如果操作数据库需要单独的安
装sqlalchemy的库,安装的命令为:

安装成功后,需要在本地的环境安装MySQL的数据库,这里不在详细的讲解MySQL的安装和
基本的配置,在MySQL的数据库中创建数据库app,也就是数据库的名称是app。下来在Flask
的程序中连接MySQL的操作。下面看具体的代码:
from sqlalchemy import create_engine,Column,Integer,String from sqlalchemy.ext.declarative import declarative_base def db_url(): HOSTNAME = '127.0.0.1' PORT = '3306' DATABASE = 'app' USERNAME = 'root' PASSWORD = 'server' DB_URL = 'mysql+pymysql://{user}:{passwd}@{host}:{port}/{db}?charset=utf8'.format( user=USERNAME, passwd=PASSWORD, host=HOSTNAME, port=PORT, db=DATABASE) return DB_URL # 创建引擎 engine = create_engine(db_url()) # 绑定数据库 SqlBase = declarative_base(engine) class User(SqlBase): __tablename__='user' id=Column(Integer,primary_key=True) username=Column(String(20)) password=Column(String(12)) def __str__(self): return '<User(username:%s,password:%s)>'%(self.username,self.password) #创建好的数据模型,映射到数据库中 SqlBase.metadata.create_all() if __name__ == '__main__': app.run()
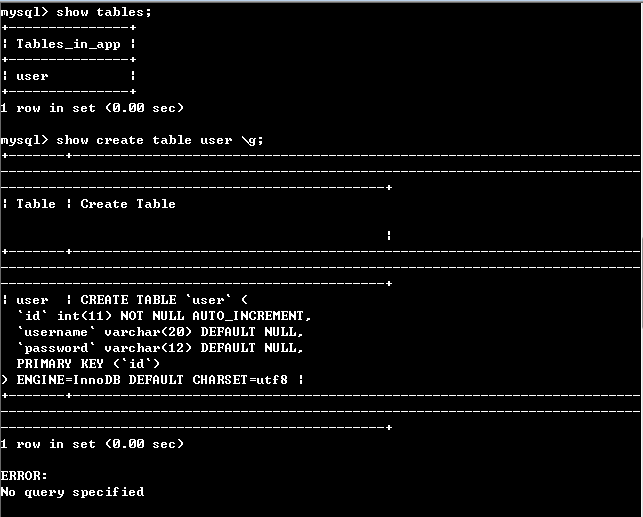
执行如上的代码后,会在MySQL的数据库里面的app数据库中创建user的表,具体见如下的MySQL
的截图:
在Flask中对数据库的操作不能仅仅限于创建数据库中的表,主要是对表的操作,比如插入数据,查询
数据,和修改数据,以及删除数据的操作。下面就实现对MySQL表的增删改查。下面主要对查询的语句进
行总结,在MySQL的查询中,查询使用到的语句是select,在Flask的应用程序中,查询使用到的方法是query,
这里首先对user表里面插入多条数据,依据插入的数据来演示查询结果。 user表插入语句后,显示的结果
如下:

下面写一个函数来对user里面的表的数据进行查询,在查询中,使用到的方法是filter,在filter是过滤条件,
下面依次演示这些,见编写的函数源码:
from flask import Flask,request,render_template,url_for,redirect,jsonify,abort,Response,make_response from flask import make_response app = Flask(__name__) app.config.update({ 'DEBUG': True, 'TEMPLATES_AUTO_RELOAD': True }) from sqlalchemy import create_engine,Column,Integer,String from sqlalchemy.ext.declarative import declarative_base from sqlalchemy.orm import sessionmaker def db_url(): HOSTNAME = '127.0.0.1' PORT = '3306' DATABASE = 'app' USERNAME = 'root' PASSWORD = 'server' DB_URL = 'mysql+pymysql://{user}:{passwd}@{host}:{port}/{db}?charset=utf8'.format( user=USERNAME, passwd=PASSWORD, host=HOSTNAME, port=PORT, db=DATABASE) return DB_URL # 创建引擎 engine = create_engine(db_url()) # 绑定数据库 SqlBase = declarative_base(engine) session=sessionmaker(engine)() class User(SqlBase): __tablename__='user' id=Column(Integer,primary_key=True) username=Column(String(20)) password=Column(String(12)) def __str__(self): return '<User(username:%s,password:%s)>'%(self.username,self.password) #创建好的数据模型,映射到数据库中 SqlBase.metadata.create_all() def dbSearch(): '''数据的查询''' result=session.query(User) print(result) dbSearch()
执行dbSearch函数后,会打印出在MySQL中查询的依据,见如下截图:
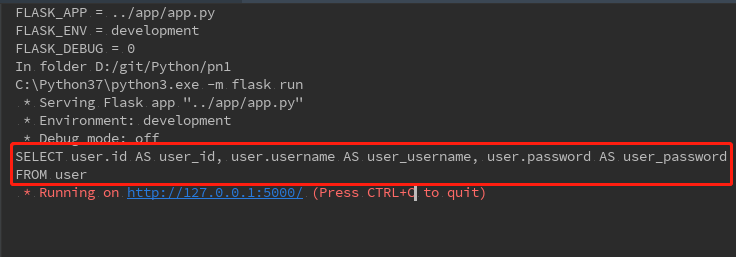
在query查询的时候,后面不加all(),会直接打印出sql的语句,这里是查询所有的数据,加all()后,见打印的输出内容:
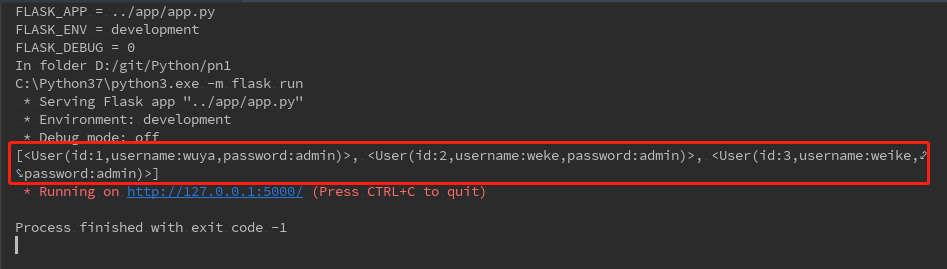
def dbSearch(): '''数据的查询''' result=session.query(User).all() print(result) dbSearch()
执行后,见打印输出的内容:
下面加入一些查询条件,如查询username是wuya的用户,那么这里会使用到filter的函数,完善后的函数为:
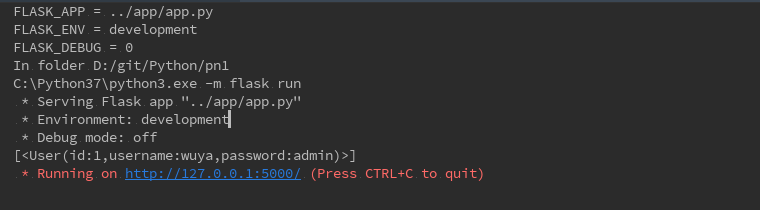
def dbSearch(): '''数据的查询''' result=session.query(User).filter(User.username=='wuya').all() print(result) dbSearch()
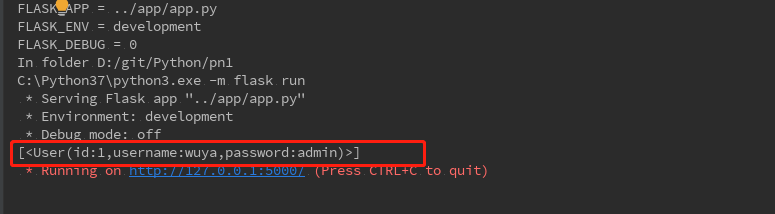
执行后会查询出username为wuya的值的数据,如果下图所示:
继续看查询的条件,在查询中经常会遇到多个条件成立时查询出结果,会使用到and,这里结合案例来看下,见完善后的代码:
def dbSearch(): '''数据的查询''' result=session.query(User).filter(User.username=='wuya',User.password=='admin').all() print(result) dbSearch()
执行后,会查询到username是wuya同时password是admin,如下图所示:
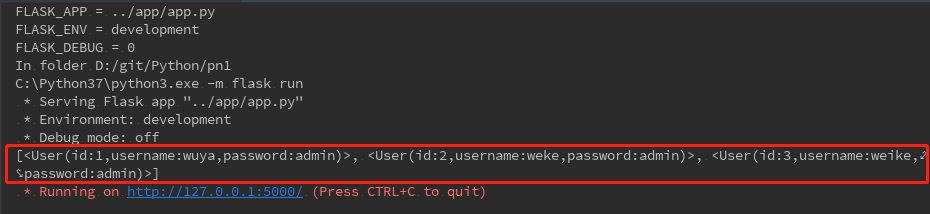
这里再来看下or的条件,就是多个条件中只有满足一个条件就可以了,使用or的时候需要导入,具体见如下的源码:
def dbSearch(): '''数据的查询''' result=session.query(User).filter(or_(User.username=='wuya',User.password=='admin')).all() print(result) dbSearch()
执行后,见查询的结果:
下来结合具体的案例来讲解query查询函数的应用,也就是ORM在实际操作中对表的查询操作,创建表book,并且对该表插入响应的数据,具体见源码:
from sqlalchemy import create_engine,Column,Integer,String,Float from sqlalchemy.ext.declarative import declarative_base from sqlalchemy.orm import sessionmaker def db_url(): HOSTNAME = '127.0.0.1' PORT = '3306' DATABASE = 'app' USERNAME = 'root' PASSWORD = 'server' DB_URL = 'mysql+pymysql://{user}:{passwd}@{host}:{port}/{db}?charset=utf8'.format( user=USERNAME, passwd=PASSWORD, host=HOSTNAME, port=PORT, db=DATABASE) return DB_URL def Base(): # 创建引擎 engine = create_engine(db_url()) # 绑定数据库 SqlBase = declarative_base(engine) return SqlBase def sqlSession(): engine = create_engine(db_url()) session = sessionmaker(engine)() return session class Book(Base()): __tablename__='book' id=Column(Integer,primary_key=True,autoincrement=True) name=Column(String(50),nullable=True) price=Column(Float,nullable=True) author=Column(String(20),nullable=True) #创建好的数据模型,映射到数据库中 Base().metadata.drop_all() Base().metadata.create_all() def add_books(): book1=Book(name='Flask',price=90,author='wuya') book2 = Book(name='Django', price=56, author='wuya') book3 = Book(name='Tornado', price=78, author='wuya') sqlSession().add_all([book1,book2,book3]) sqlSession().commit()
下面主要依据如上添加的数据,来讲解limit,offset的应用,前者是对返回的数据做限制,后者是对查找的数据做过滤,
比如从第几条开始查询数据。
def query_limit(): '''对返回的数据做限制:limit的应用''' book=sqlSession().query(Book).limit(2).all() print(book) def query_offset(): '''对返回的数据做限制:limit的应用''' book=sqlSession().query(Book).offset(1).limit(2).all() print(book)
见执行后返回的结果信息:

再来看切片的操作,使用到的方法是slice的方法,它有点像列表当中的切片一样,总的来说,使用它可以得到获取一定范围内
想要的数据,见案例源码:
def query_slice(): '''slice切片的应用''' book=sqlSession().query(Book).slice(0,2).all() print(book)
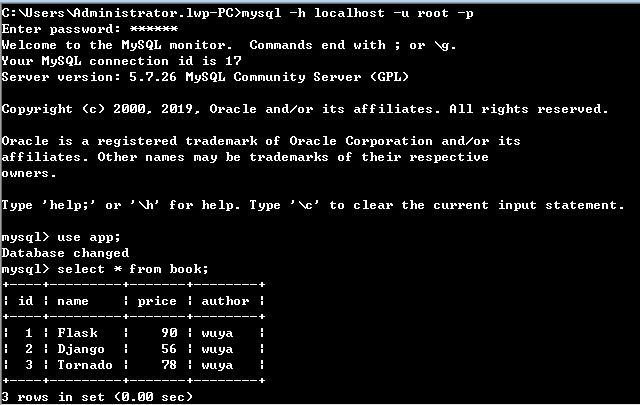
接着来看query中的排序,排序在原生的SQL中使用到的方法是order_by,和desc以及asc来进行的,依然已book的数据
为案例,以价格的高低来进行排序,见该表中的本身数据,如下图所示:
在sqlalchemy中,排序主要分为三类,第一种就是order_by来进行排序,第二种是在创建的表中就指定按那个字段来
进行排序,这里先看第一中的情况,见该函数的源码:
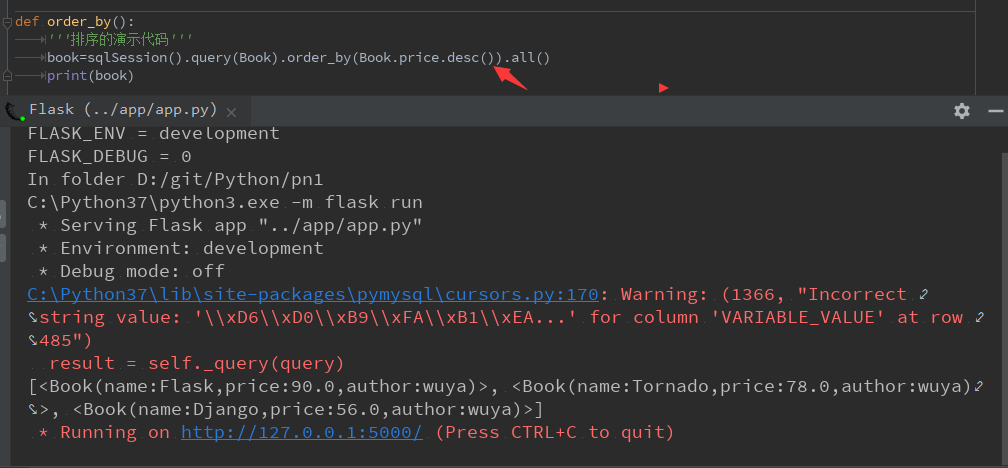
def order_by(): '''排序的演示代码''' book=sqlSession().query(Book).order_by('price').all() print(book)
默认是升序,也就是从小到达,见执行的数据排序:

对程序的代码做以修改,实现倒叙,也就是从大到小,只需要加desc()的函数就可以了,见修改后的代码:
接着来看在创建的表中指定排序的字段,这里就会使用到函数的类属性,以价格作为排序,见实现的源码:
class Book(Base()): __tablename__='book' id=Column(Integer,primary_key=True,autoincrement=True) name=Column(String(50),nullable=True) price=Column(Float,nullable=True) author=Column(String(20),nullable=True) __mapper_args__={ 'order_by':price.desc() } def __repr__(self): return '<Book(name:%s,price:%s,author:%s)>'%(self.name,self.price,self.author)
这样查询出的数据,就会以价格的方式,倒叙的方式进行排序。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号