Django学习笔记之分页(三)
在django学习笔记之模板学习中获取了大量的数据,那么下来实现对这些数据进行分页的实现,
对数据的分页,虽然django内部提供了,但是不是很友好,当然本人这里分享的分页组件,也不是
本人写的(这点特别强调,是wuSir写的,在这里只是应用)。首先来写分页的组件,分页的单独写
一个模块,该模块的名称就是pager.py,它的源码为:
#!/usr/bin/env python #coding:utf-8 #Author:WuYa '''自定义分页的组件''' class PagerPagination: def __init__(self,totalCount,currentPage,perPageItemNum=15,maxPageNum=7): ''' :param totalCount: 数据总个数 :param currentPage: 当前页 :param perPageNum: 每页显示的条数 :param maxPageNum:最多显示页码 ''' self.total_count=totalCount try: self.current_page = int(currentPage) except Exception as e: self.current_page=1 self.per_page_item_num=perPageItemNum self.max_page_num=maxPageNum def start(self): '''页数的开始''' return (self.current_page-1)*self.per_page_item_num def end(self): '''页数的结束''' return self.current_page*self.per_page_item_num @property def num_pages(self): '''得到总页数''' a,b=divmod(self.total_count,self.per_page_item_num) if b==0: return a return a+1 def pager_num_range(self): # #当前页 # self.current_page # #最多显示的页码数量 # self.per_pager_num # #总页数 # self.num_pages if self.num_pages < self.max_page_num: return range(1, self.num_pages + 1) # 总页数特别多 5 part = int(self.max_page_num / 2) if self.current_page <= part: return range(1, self.max_page_num + 1) if (self.current_page + part) > self.num_pages: return range(self.num_pages - self.max_page_num + 1, self.num_pages + 1) return range(self.current_page - part, self.current_page + part + 1) def page_str(self): page_list = [] first = "<li><a href='/login/lagou/?p=1'>首页</a></li>" page_list.append(first) if self.current_page == 1: prev = "<li><a href='#'>上一页</a></li>" else: prev = "<li><a href='/login/lagou/?p=%s'>上一页</a></li>" % (self.current_page - 1,) page_list.append(prev) for i in self.pager_num_range(): if i == self.current_page: temp = "<li class='active'><a href='/login/lagou/?p=%s'>%s</a></li>" % (i, i) else: temp = "<li><a href='/login/lagou/?p=%s'>%s</a></li>" % (i, i) page_list.append(temp) if self.current_page == self.num_pages: nex = "<li><a href='#'>下一页</a></li>" else: nex = "<li><a href='/login/lagou/?p=%s'>下一页</a></li>" % (self.current_page + 1,) page_list.append(nex) last = "<li><a href='/login/lagou/?p=%s'>尾页</a></li>" % (self.num_pages,) page_list.append(last) return ''.join(page_list)
由于该源码非本人写,所以这里就不做详细的解释了,类PagerPagination实例化的时候,第一个参数是最大数,第二个参数是
自定义的页数,其它的代码中都有注释的,这里就不做详细的解释了。
下来对之前的views.py的源码再次进行修改,总的思路是获取翻页的参数进行了循环,这样可以获取很多页的数据,
然后把这些数据按照分页的方式处理,见实现的源码:
from django.shortcuts import render,redirect from django.http import HttpResponse # Create your views here. import requests def index(request): return HttpResponse('Hello World') def getHeaders(): headers={ 'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8', 'Referer':'https://www.lagou.com/jobs/list_%E8%87%AA%E5%8A%A8%E5%8C%96%E6%B5%8B%E8%AF%95%E5%B7%A5%E7%A8%8B%E5%B8%88?labelWords=&fromSearch=true&suginput=', 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36', 'Cookie':'_ga=GA1.2.186012464.1544195085; user_trace_token=20181207230439-6b58f932-fa31-11e8-8ce7-5254005c3644; LGUID=20181207230439-6b58fd66-fa31-11e8-8ce7-5254005c3644; index_location_city=%E5%85%A8%E5%9B%BD; _gid=GA1.2.1553638128.1545207856; JSESSIONID=ABAAABAAAGFABEFDA17A850FC896FFEA4FD0408D8D48FE7; PRE_UTM=; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2F; TG-TRACK-CODE=index_search; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%22167c6f1e2843ee-03f91923647488-5d1f3b1c-1049088-167c6f1e2852e8%22%2C%22%24device_id%22%3A%22167c6f1e2843ee-03f91923647488-5d1f3b1c-1049088-167c6f1e2852e8%22%7D; sajssdk_2015_cross_new_user=1; _gat=1; LGSID=20181219225013-64077f08-039d-11e9-ab57-525400f775ce; PRE_HOST=www.bing.com; PRE_SITE=https%3A%2F%2Fwww.bing.com%2F; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1544357580,1545207857,1545230956,1545231023; X_HTTP_TOKEN=e7159997603abc22a96c9d0230a58ad6; LG_LOGIN_USER_ID=029d880fdaa25ab1429acea6baed547394834a2c4d8a7ba1; _putrc=0057C29638877881; login=true; unick=%E6%9D%8E%E6%97%BA%E5%B9%B3; showExpriedIndex=1; showExpriedCompanyHome=1; showExpriedMyPublish=1; hasDeliver=22; gate_login_token=4d1f9337decf3879c11e2ef74d509d33bbe644355091f623; SEARCH_ID=1d55be7683cf433a97361a420b6051f1; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1545231073; LGRID=20181219225104-82681c06-039d-11e9-94bc-5254005c3644'} return headers from django.core.paginator import Paginator from .pager import PagerPagination def laGou(request): positions = [] for item in range(1,10): r = requests.post( url='https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false', data={'first': False, 'pn': item, 'kd': '自动化测试'}, headers=getHeaders()) print(r.text) for i in range(15): company = r.json()['content']['positionResult']['result'][i]['companyFullName'] positionName = r.json()['content']['positionResult']['result'][i]['positionName'] workYear = r.json()['content']['positionResult']['result'][i]['workYear'] salary = r.json()['content']['positionResult']['result'][i]['salary'] education = r.json()['content']['positionResult']['result'][i]['education'] city = r.json()['content']['positionResult']['result'][i]['city'] positions.append({ 'city': city, 'company': company, 'positionName': positionName, 'salary': salary, 'education': education, 'workYear': workYear }) current_page=request.GET.get('p',None) page_obj=PagerPagination(20,current_page) data_list=positions[page_obj.start():page_obj.end()] return render(request,'login/lagou.html',locals())
下来需要对模板文件lagou.html文件做一个修改,在该文件中需要加上分页的处理,见修改后的源码:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <link rel="stylesheet" href="/static/plugins/bootstrap/css/bootstrap.min.css"> <title>拉钩网平台招聘信息</title> </head> <body> <div class="container"> <table class="table table-hover"> <thead> <tr> <td>城市</td> <td>公司</td> <td>职位名称</td> <td>薪资</td> <td>学历</td> <td>工作年限</td> </tr> </thead> <tbody> {% for position in data_list %} <tr> <td>{{ position.city }}</td> <td>{{ position.company }}</td> <td>{{ position.positionName }}</td> <td>{{ position.salary }}</td> <td>{{ position.education }}</td> <td>{{ position.workYear }}</td> </tr> {% endfor %} </tbody> </table> <ul class="pagination pagination-sm"> {{ page_obj.page_str|safe }} </ul> <div style="height: 300px;"></div> </div> </body> </html>
再次启动服务,在浏览器中访问http://localhost:8000/login/lagou/,就可以显示出如下的信息,可以进行翻页,见截图:
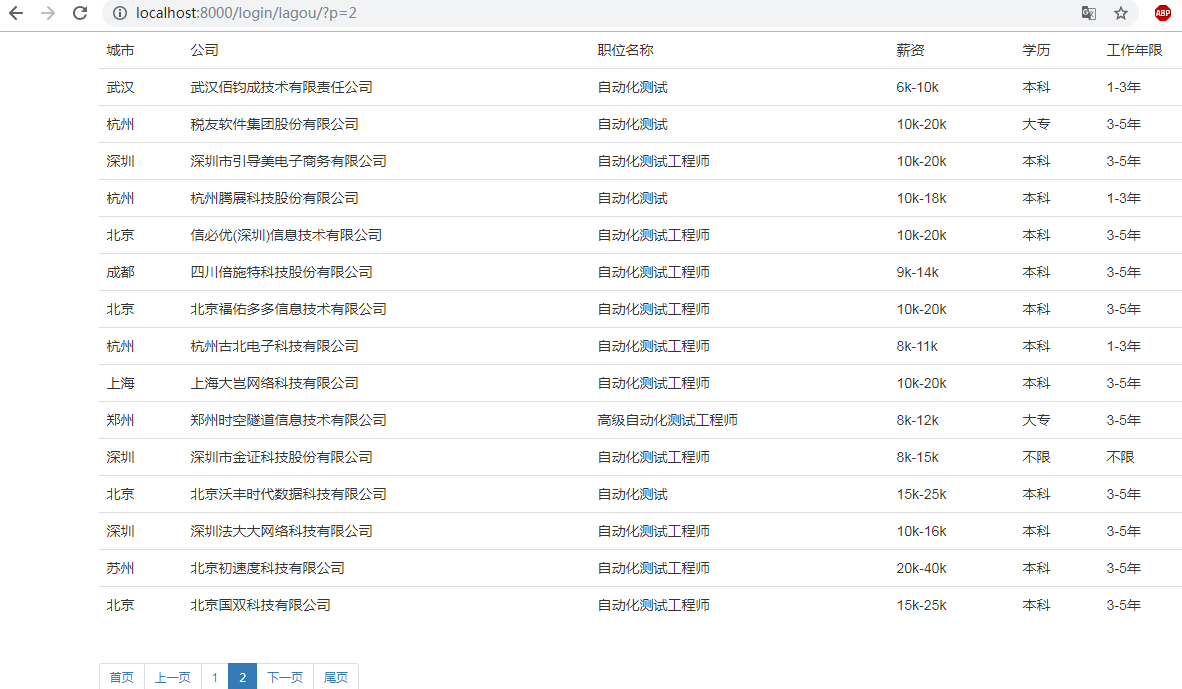
如上,就可以实现多数据的分页,自定义分页相对来说,是比较麻烦的,里面涉及很多的计算,数学学的不好,感觉计算的累的。
欢迎关注微信公众号“Python自动化测试”

 浙公网安备 33010602011771号
浙公网安备 33010602011771号