Azure Synapse Analysis 开箱 Blog - 肆 -- Synapse Analysis SQL Pool CDC Data ETL
前一篇 Blog 中我们完成了通过 Azure Function 完了从上游 Cosmos DB ChangeFeed 数据的抽取并转存至 Azure Data Lake 中。回顾一下整个演示方案架构,后续我们需要在 Azure Data Warehouse 中拉入增量数据 CDC(Change Data Capture)。并对 Azure Data Warehouse 现有的数据进行更新。
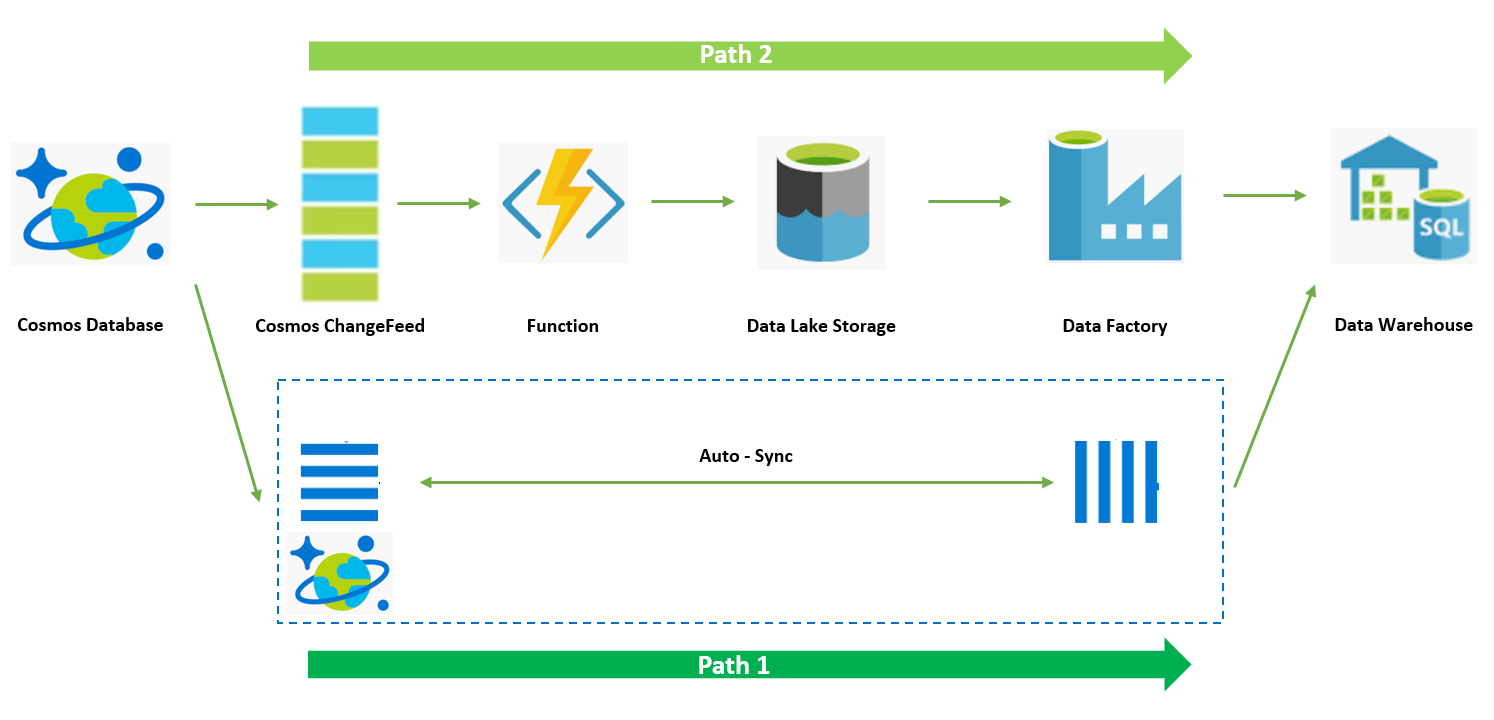
在上述架构中,Data Lake 的下一跳是 Data Factory 服务,Data Factory 服务扮演数据水线工具可以自动完成整个 CDC 数据 ETL 并 Update 到 Data Warehouse 中的数据。整个方案中 ETL 和 Update 都借助 DW 的算力来实现,即 Data Warehouse 的 ELT 架构,先将 CDC Raw 导入到 Data Warehouse 然后在 DW 中进行 Transform 和 Update 操作。本片 Blog 先为大家演示整个过程在 Data Warehouse 中手动触发 T-SQL 执行实现的方式,下一篇 Blog 再为大家介绍如何将整个过程通过 Data Factory 实现数据处理水线的自动化。
操作步骤如下:
1. 创建 Azure Synapse Analysis 资源
参考:https://docs.microsoft.com/en-us/azure/synapse-analytics/quickstart-create-workspace
2. 创建 Azure Synapse Analysis SQL Pool
参考:https://docs.microsoft.com/en-us/azure/synapse-analytics/quickstart-create-sql-pool-portal
3. 通过 Azure Synapse Studio 创建 T-SQL Script
参考:https://docs.microsoft.com/en-us/azure/synapse-analytics/quickstart-synapse-studio
4. 创建数据表格,创建 DW 表格,演示中使用 demotable 命名
CREATE TABLE [dbo].[demotable] ( [ID] VARCHAR(50) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL, [PRICE] INT NOT NULL, [QUANTITY] INT NOT NULL ) WITH ( DISTRIBUTION = HASH(ID), CLUSTERED COLUMNSTORE INDEX );
5. 通过 COPY 命令初始化表格数据,替换 datalakestorageaccountname, filestoragename, filename 为前述 Function 转存的 Data Lake 存储对应的信息
COPY INTO dbo.demotable FROM 'https://<datalakestorageaccountname>.dfs.core.windows.net/<filestoragename>/<filename>.csv' WITH ( FILE_TYPE = 'CSV', FIRSTROW = 2 );
6. 通过 Select 语句查看当前 DW 表格中数据
SELECT TOP 10 * FROM [dbo].[demotable];
7. 通过 Staging Table 加载 CDC 数据并处理更新 DW 表格中数据
CREATE TABLE [dbo].[stg_demotable] ( [ID] VARCHAR(50) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL, [PRICE] INT NOT NULL, [QUANTITY] INT NOT NULL ) WITH ( DISTRIBUTION = ROUND_ROBIN, CLUSTERED COLUMNSTORE INDEX ); COPY INTO dbo.[stg_demotable] FROM 'https://cosmossynapsedemo.dfs.core.windows.net/demofs/2020-07-08*.csv' WITH ( FILE_TYPE = 'CSV', FIRSTROW = 2 ); -- SELECT TOP 10 * FROM [dbo].[stg_demotable]; -- UPSERT CDC DATA -- CREATE TABLE dbo.[demotable_upsert] WITH ( DISTRIBUTION = HASH(ID) , CLUSTERED COLUMNSTORE INDEX ) AS -- New rows and new versions of rows SELECT s.[ID] , s.[PRICE] , s.[QUANTITY] FROM dbo.[stg_demotable] AS s UNION ALL -- Keep rows that are not being touched SELECT p.[ID] , p.[PRICE] , p.[QUANTITY] FROM dbo.[demotable] AS p WHERE NOT EXISTS ( SELECT * FROM [dbo].[stg_demotable] s WHERE s.[ID] = p.[ID] ) ; RENAME OBJECT dbo.[demotable] TO [demotable_old]; RENAME OBJECT dbo.[demotable_upsert] TO [demotable]; DROP TABLE [dbo].[demotable_old]; DROP TABLE [dbo].[stg_demotable];
8. 在 Cosmos DB 侧模拟更改数据条目,在 DW 手工执行上述 T-SQL 脚本,并通过 Select 语句查新 DW 数据是否已经完成更新。
SELECT TOP 10 * FROM [dbo].[demotable];
到此为止,我们已经可以手工方式在 Data Warehouse ELT + Update 的数据处理流程跑通,下面一篇 Blog 将为大家介绍如何通过 Data Factory 工具将整个数据水线自动话。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号