pandas-2023-07-20
1、用pandas读取文件,如果是字符串类型会被当做object类型。

2、用head可以传入要输出显示的行数,但是指定行数不包括表头(并且观察到表头行不作为索引值0),另外,如果不传入参数时会默认输出表头加5行表格内容,weather.csv文件引用自以下博客https://blog.csdn.net/tianlei_/article/details/130674019。

3、tail表示从后往前输出表格内容。

4、基本函数使用。

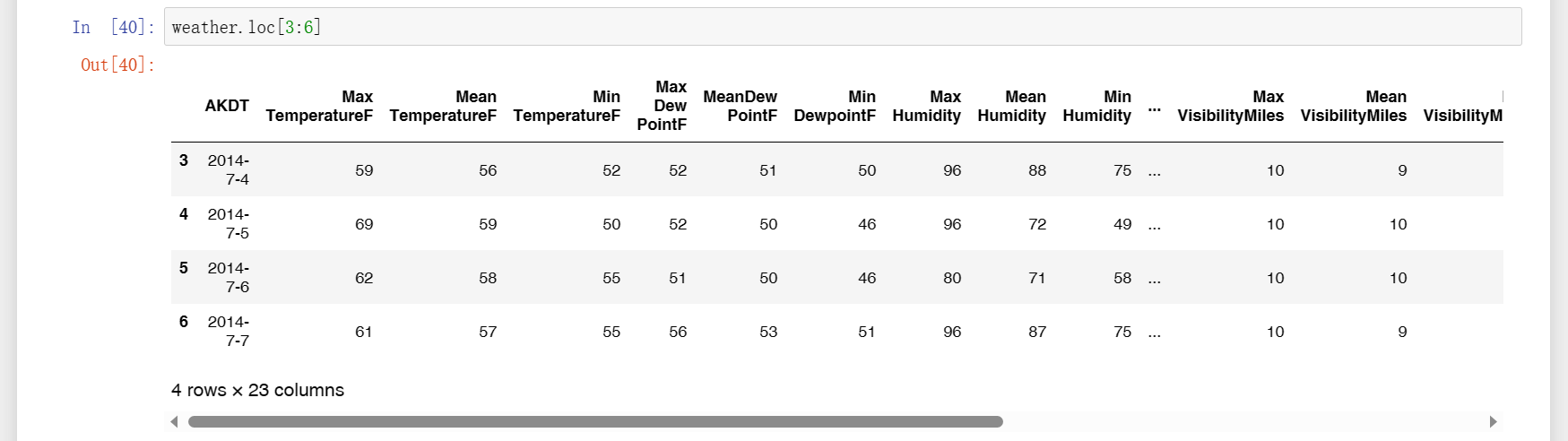
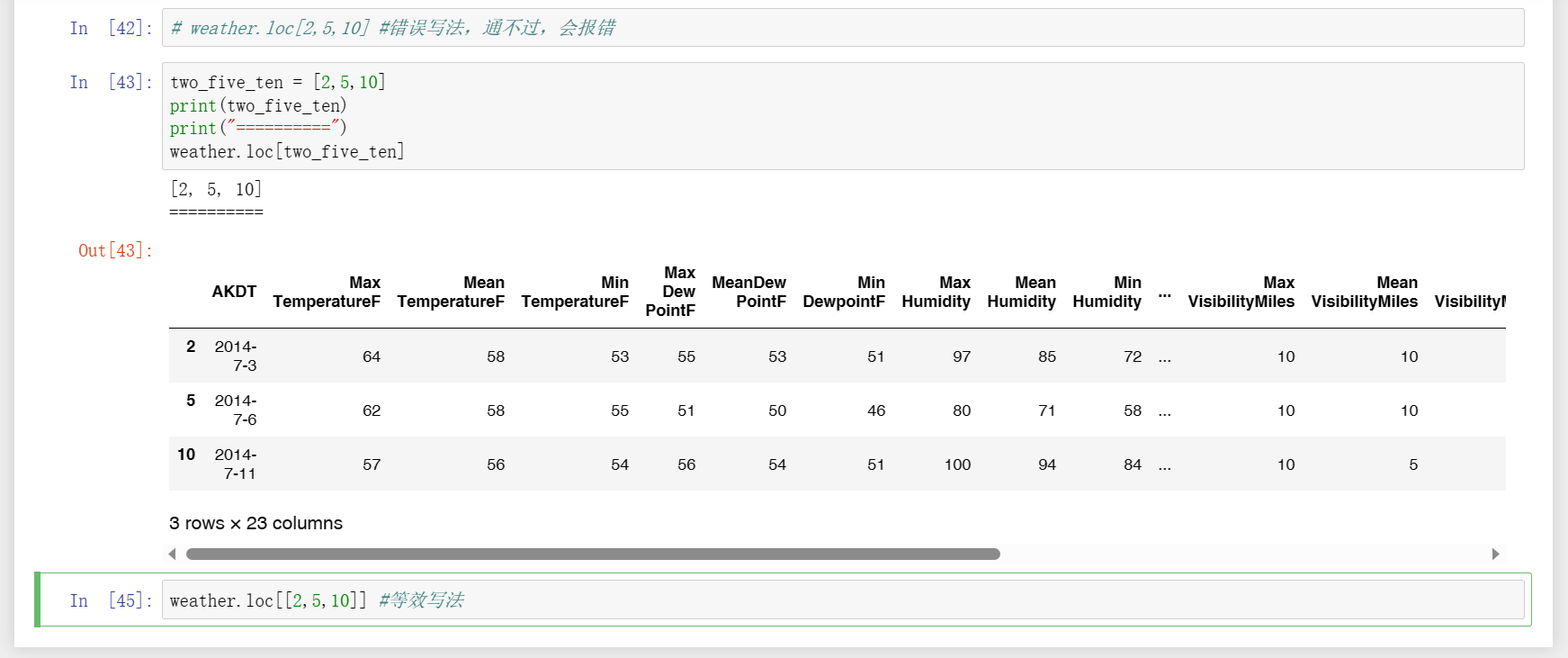
5、输出行样本,用loc显示连续几行,如下图一,想要显示指定的某几行,如图二。
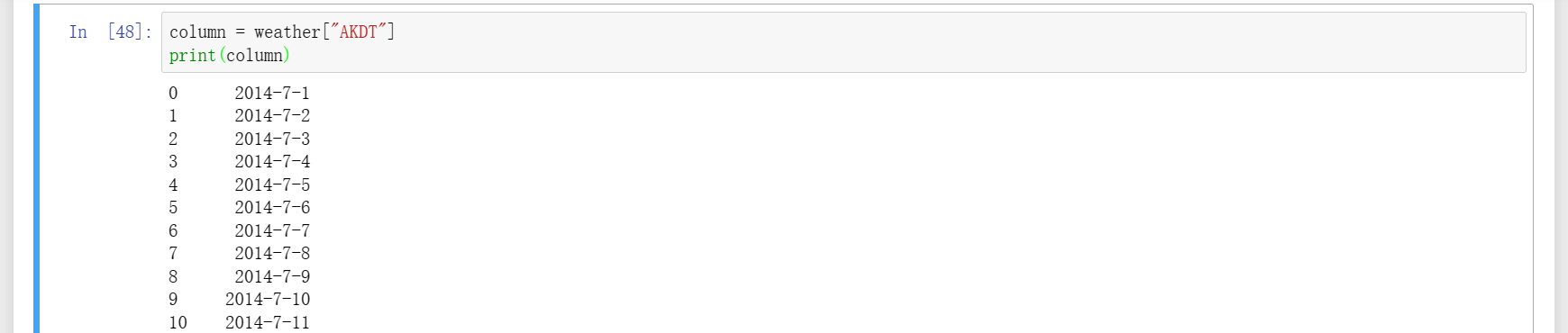
6、输出列内容,想输出某一列内容,直接传入对应列的名称,如图一,想输出某几列内容,如图二。

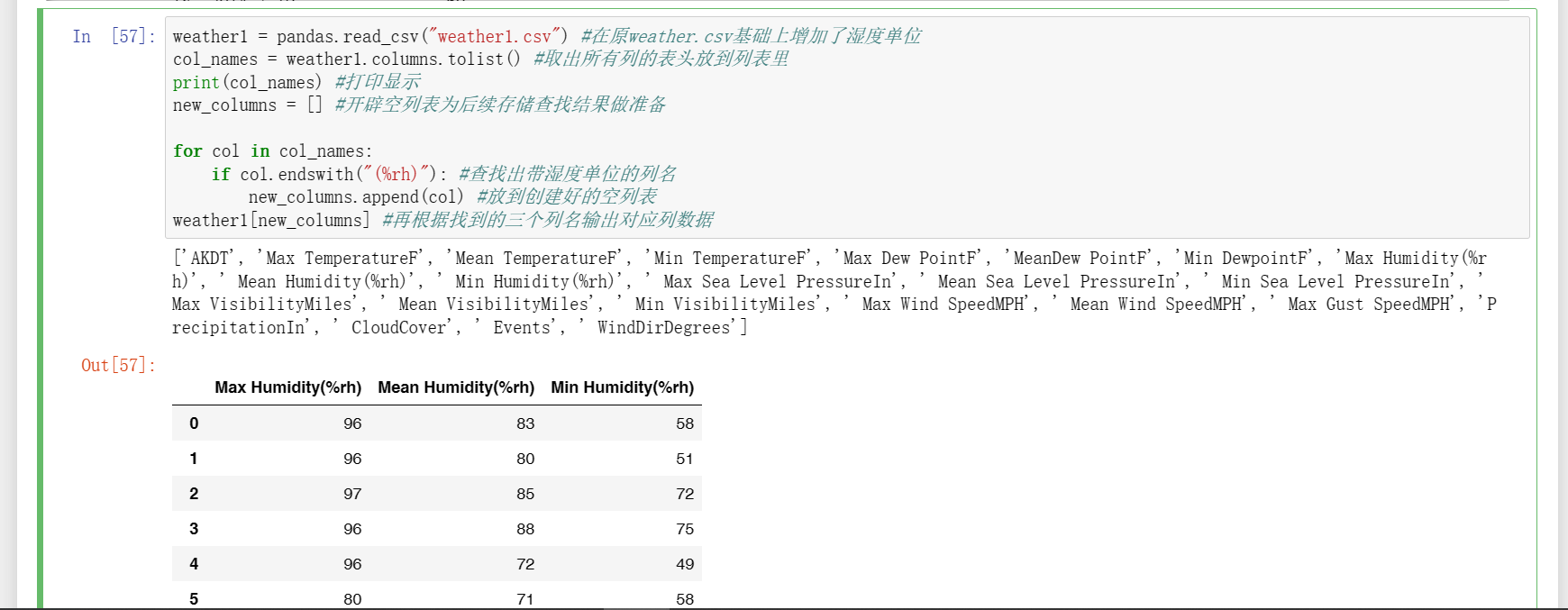
7、根据指定字符串反查表格内容并输出数据。
8、对某一列内容进行除运算,测试时是准备对最后一列内容进行的,但是根据最后一列的列名输出该列信息时编译报错,后来经过仔细对比,发现是最后列的列名传入有错,少了空格,回想起来出错的列名是直接通过打开表格用鼠标双击单元格直接获取然后复制过去的,这样在双击时是不会把列名中的空格也选上的,所以造成了错误,查找错误过程是对比了前面已经输出的表头内容的,这也提醒了筛查原因时可以把表头信息打印出来作为对比。

9、sort_values传入列名即可对某一列进行排序,inplace=True时表示按已排序完的形式显示,inplace=Flase表示虽排序完但不按排序后的形式显示(所以显示时还是显示的原表格形式),如果想要查看是否真的排序了,可以取消掉第四行的屏蔽语句打印出来对比看一下;无论inplace是True还是Flase,打开看一下原表格其实会发现并不会真的去修改源数据的顺序(也就是原表格是什么样子还依旧保持什么样子),这里要说的是测试时尽量要做到重新读取表格,否则看到的都是已排序完的表格形式而无法对比查看两种取值的不同显示效果。


10、调用sort_values后默认是按升序排列,如果传入ascending并令其为False则可以按降序排列;但是这次测试时添加ascending参数不小心写了个中文逗号,但是后面参数又及时使用了英文,因为这种错误比较隐蔽,导致报错之后排查还是折腾了一会。


11、注册kaggle,参考:https://blog.csdn.net/Vincci_Lin/article/details/128008719;然后获取泰坦尼克号训练数据train.csv:https://www.kaggle.com/c/titanic/data,为了避免日后文件多起来不好区分,这里将train.csv放到项目代码路径之后顺便更改了一下文件名为titanic_train.csv。

12、通过loc指定显示Age列的第0行到第10行,再通过isnull可以看到有缺失值的所在行其判断结果为True,根据numpy时所学特性可知(而pandas是基于numpy的更高一级封装),这些判断结果可以作为索引值使用,传回原来的Age列就可以筛选出所有缺失值数据,筛选出来之后就可以进行基本的统计及其它运算。
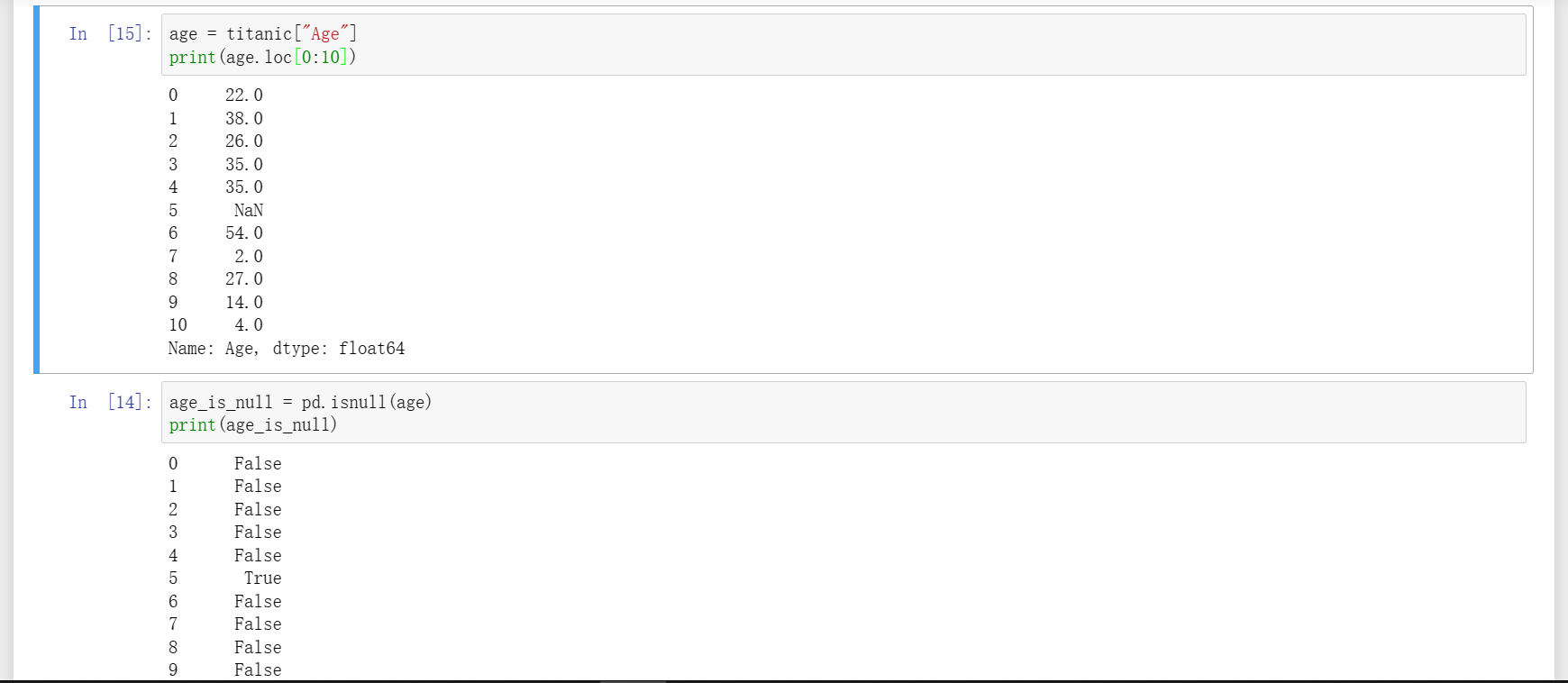
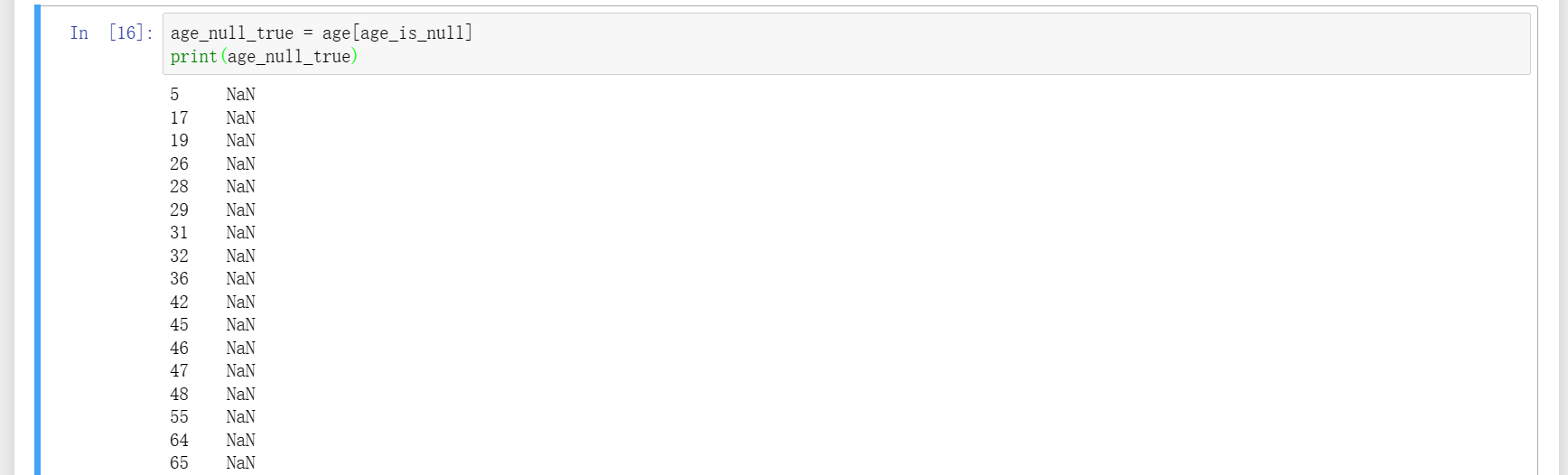

13、如果直接对Age列进行求平均,会发现无法求得因而显示nan,因为Age列包含有缺失值,所以下面附加条件将非空值都找出来,然后再求得正确的均值,但是也可以直接调用mean方法由pandas自行过滤缺失值后再求得均值。



14、根据表格大概已知船舱等级只有1,2,3这三类,为了统计1,2,3这三类等级船舱各自的平均票价,需要创建一个字典存储结果(因为三个类别明显一一对应有各自的平均票价,即构成键值对,所以要用字典),在for循环中,会进行三次循环,第一次循环,先找出三个类别中其中一个类别的所有数据(经过这一步数据中还是包含有“Name”、“Sex”等等无关数据,不过好在都是同一等级船舱乘客的),再传入“Fare”得到该类别所有的“Fare”(譬如3等级船舱的乘客假设有100个,那么经过这一步就筛选出了100个3等级船舱的票价),接下来调用.mean()方法求得均值并存入字典,然后是第二次循环、第三次循环直至结束。

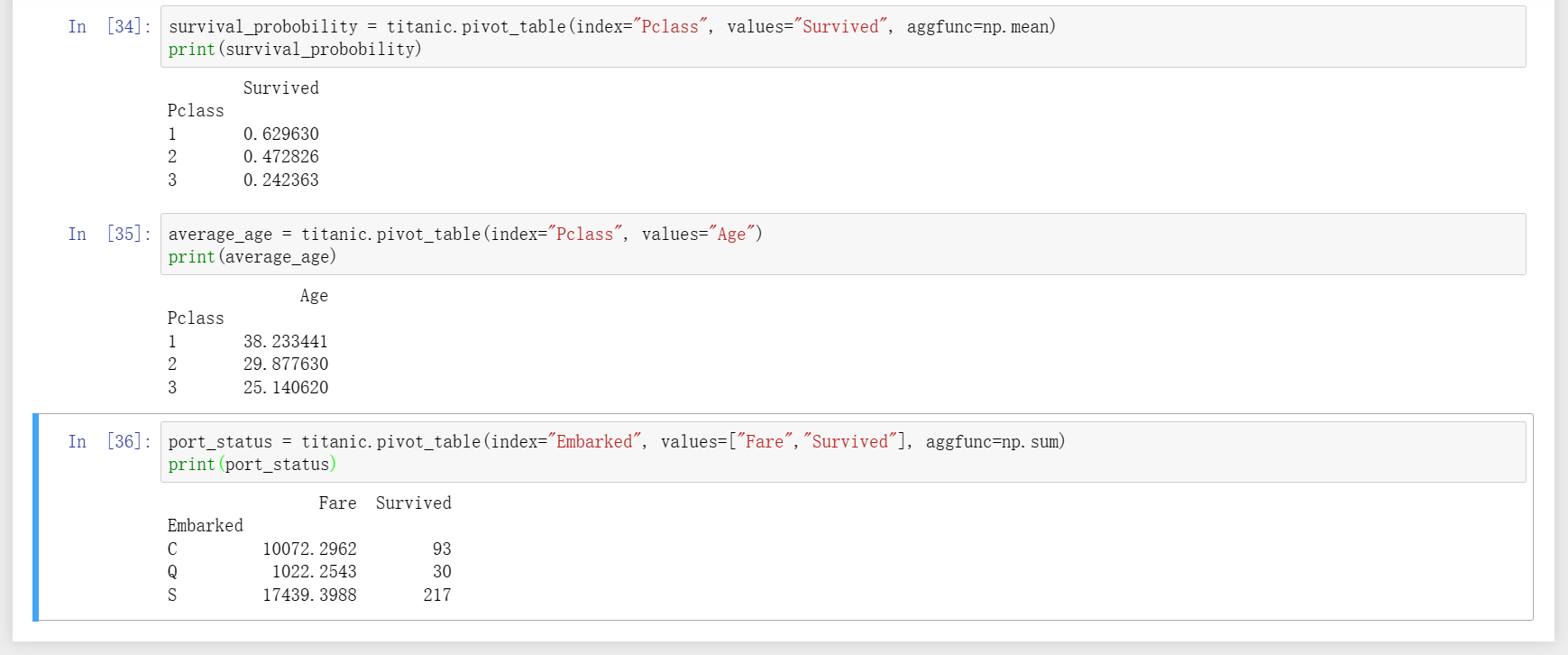
15、数据透视表pivot_table(以谁为基准,统计什么东西,按照什么方法统计),如果第三个参数缺省时则默认按平均值方法统计,另外统计内容也可以不限于单一因素(例如以"Embarked"登船地为标准进行统计时就传入了两个统计内容“Fare”、“Survived”)。
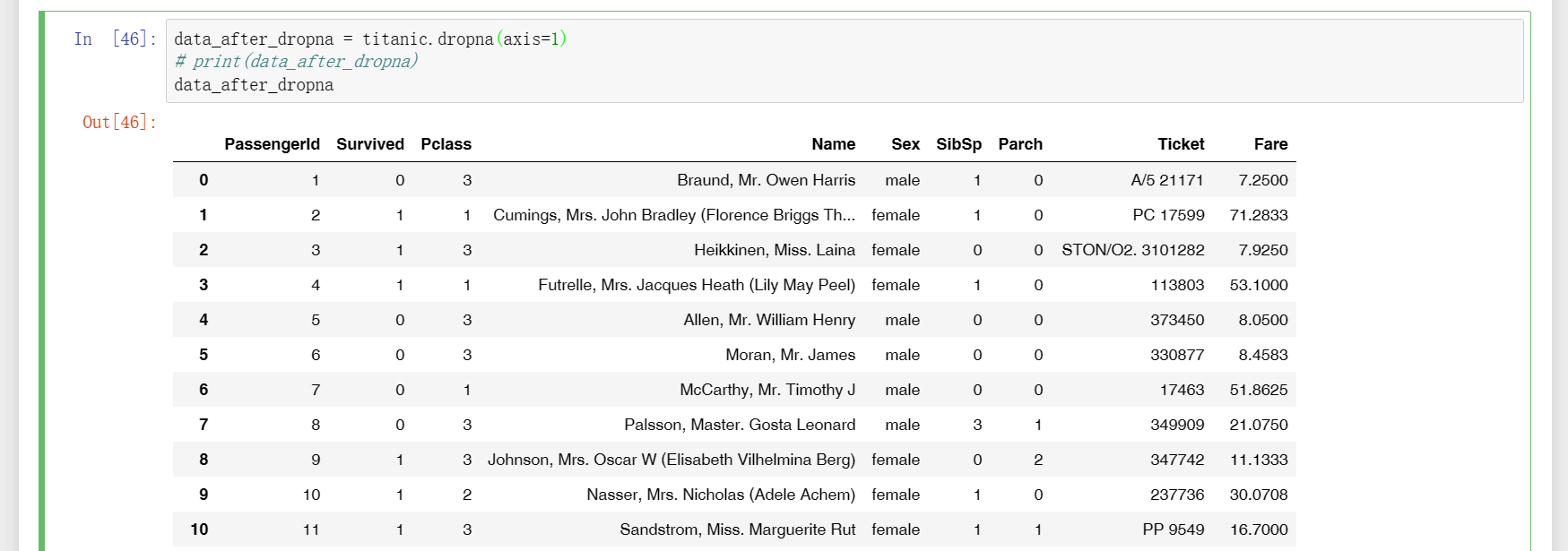
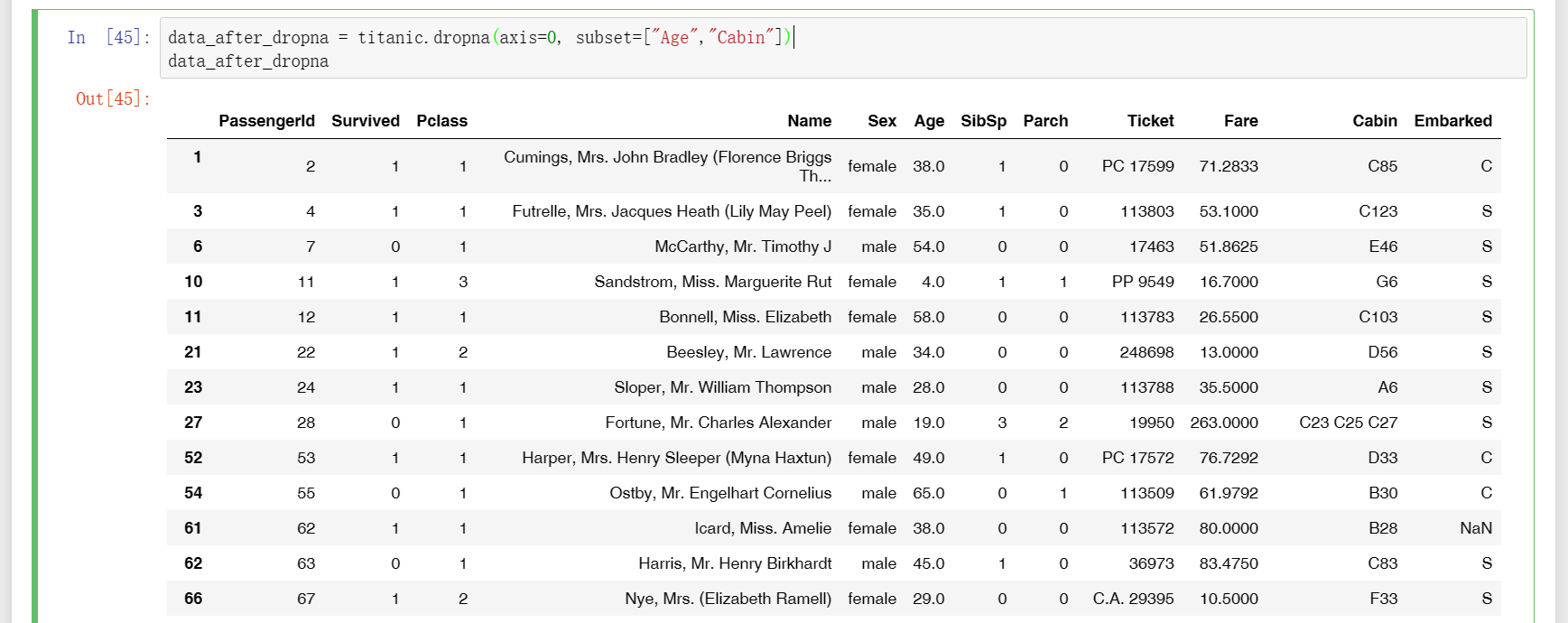
16、dropna用于删除存在缺省值的行或列,下面测试时传入axis=0说明要删除行,由于Cabin有许多行都存在缺省值,所以这些行被删除是肯定的,现在要确认的一个信息是,Cabin和Age都有缺省值,那么是两者都存在缺省值时才删除对应的行,还是只要任一者某行有缺省值时就删除?经过比对测试结果和原表格发现,系统会执行“只要任一者某行有缺省值时就删除”(观察原表格“PassengerId”的32行"Spencer, Mrs. William Augustus (Marie Eugenie)"就知道,该男性“Age”缺失但“Cabin”有值,但在测试输出的表格上已经被删除);如果传入axis=1说明要删除列,通过下图二可以看到只要存在缺省值的列都被删除,也就是删除了“Age”和"Cabin"两列;下图三和图一的效果一样,都是删除行,但是图三是用subnet明确指定了根据哪些列的缺省值来删除行;另外说明的是,由于使用print()时系统会将一屏显示不下的表格内容分屏显示,所以这里不再使用prin()而是直接由系统输出结果。

17、使用loc定位并输出上面提到的第32行样本指定信息。

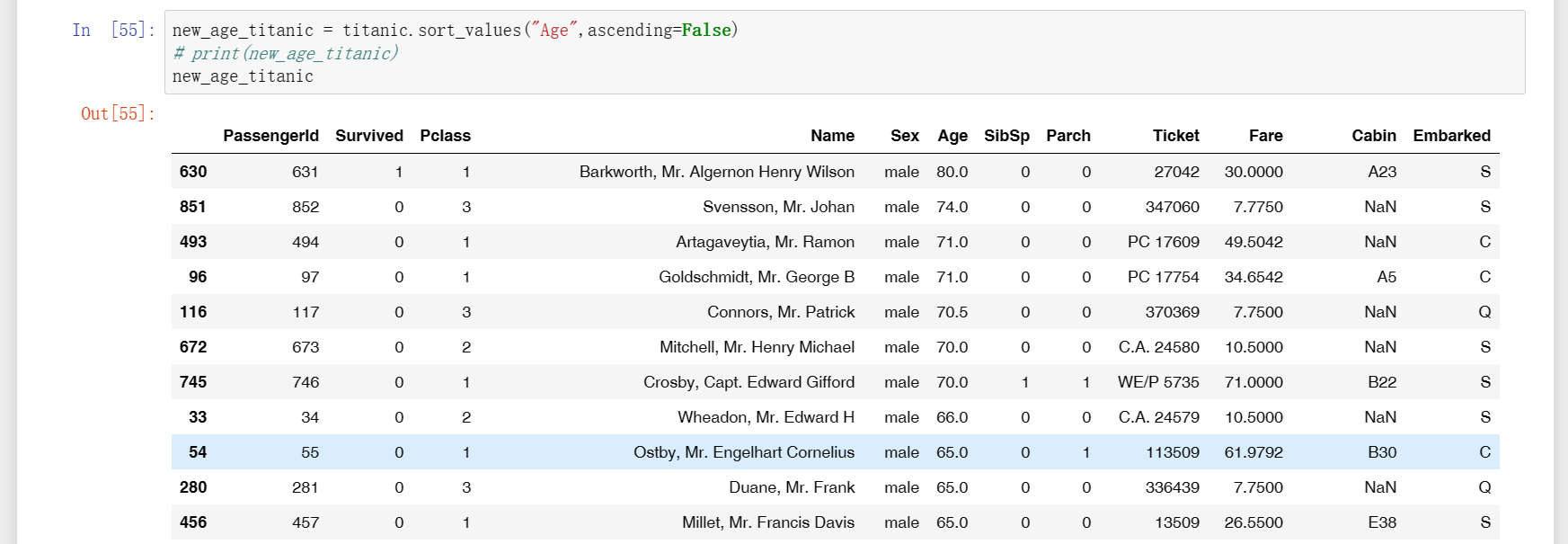
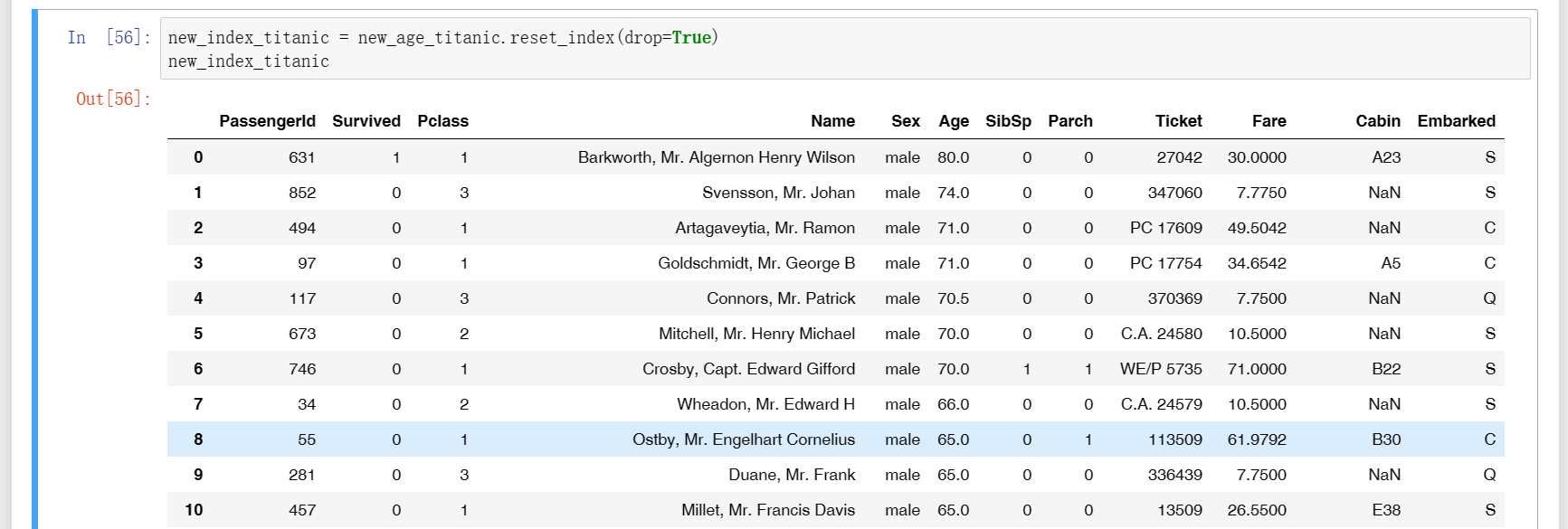
18、先将表格按照“Age”列使用sort_values进行降序排列,如下图一,可以观察到最前面index列由630、851、493等构成,不过是杂乱无章的,因此这里要做的就是使用reset_index重新生成一个新的index,而传入的参数drop=True说明确定要删掉该列再生成。
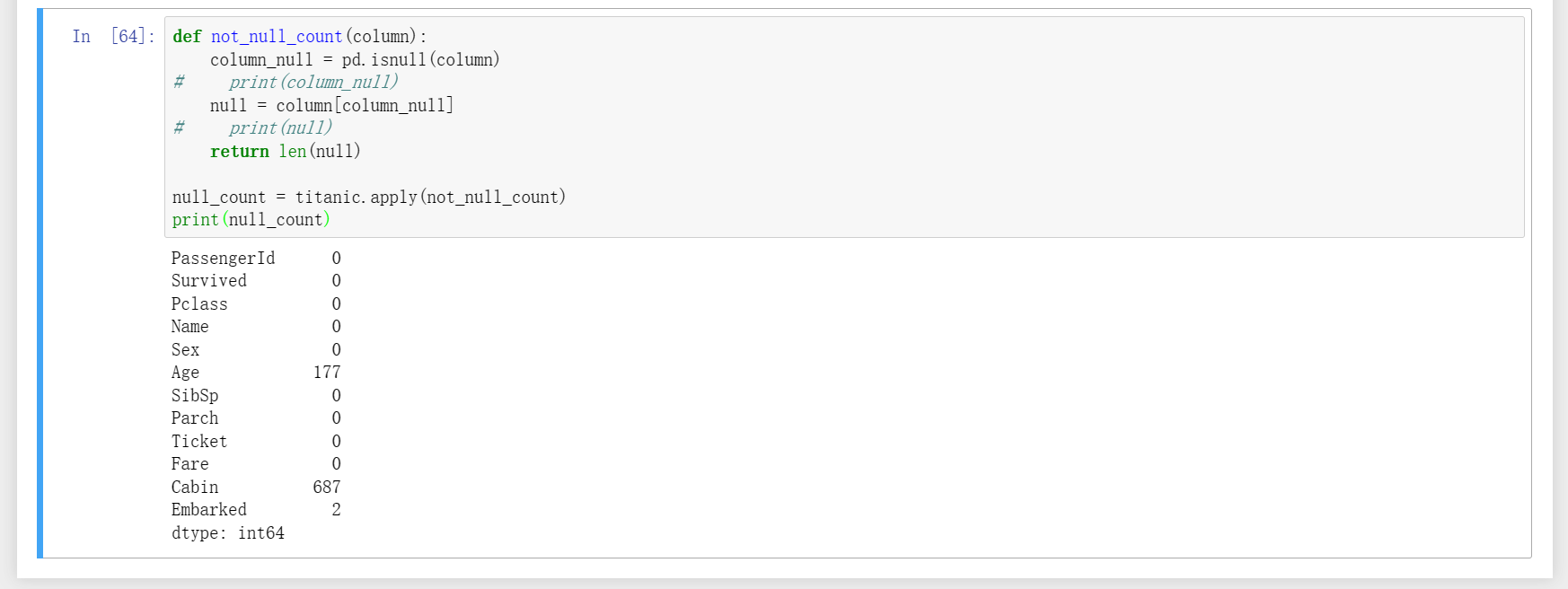
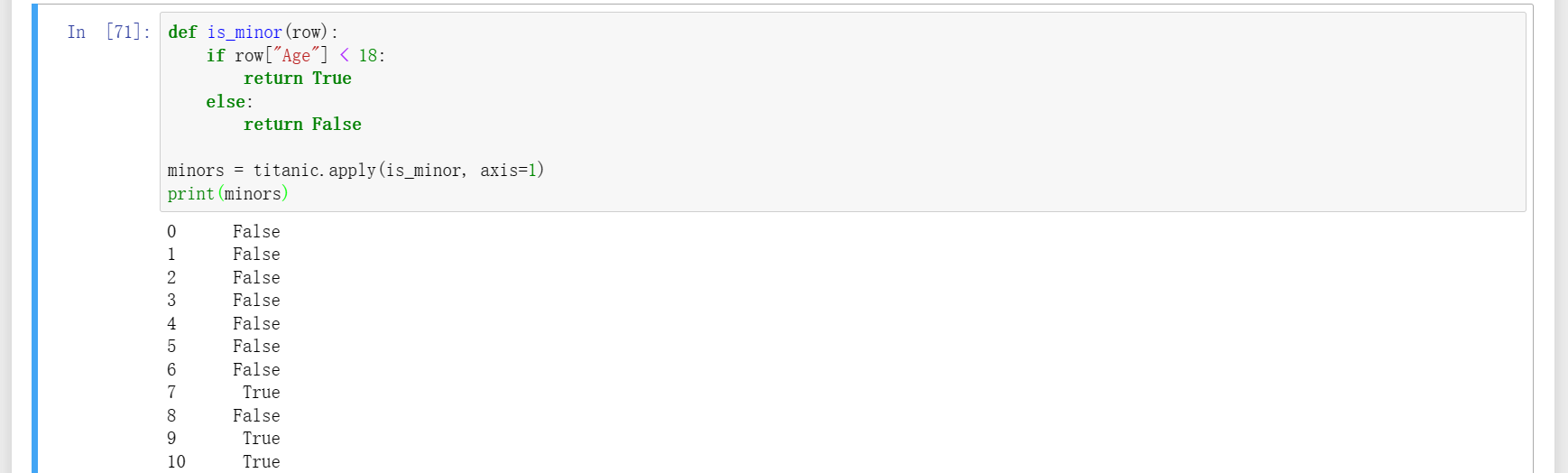
19、使用apply实现对自定义函数的调用,图一自定义了一个函数用于返回第一百行的样本数据,图二自定义了一个函数用于返回每一列中缺省值的总数;图三自定义了一个函数将“Pclass”的三种类别分别用对应的英文替换;图四和图五自定义了一个函数用于按年龄划分类别。




 浙公网安备 33010602011771号
浙公网安备 33010602011771号