

numpy-2023-07-17
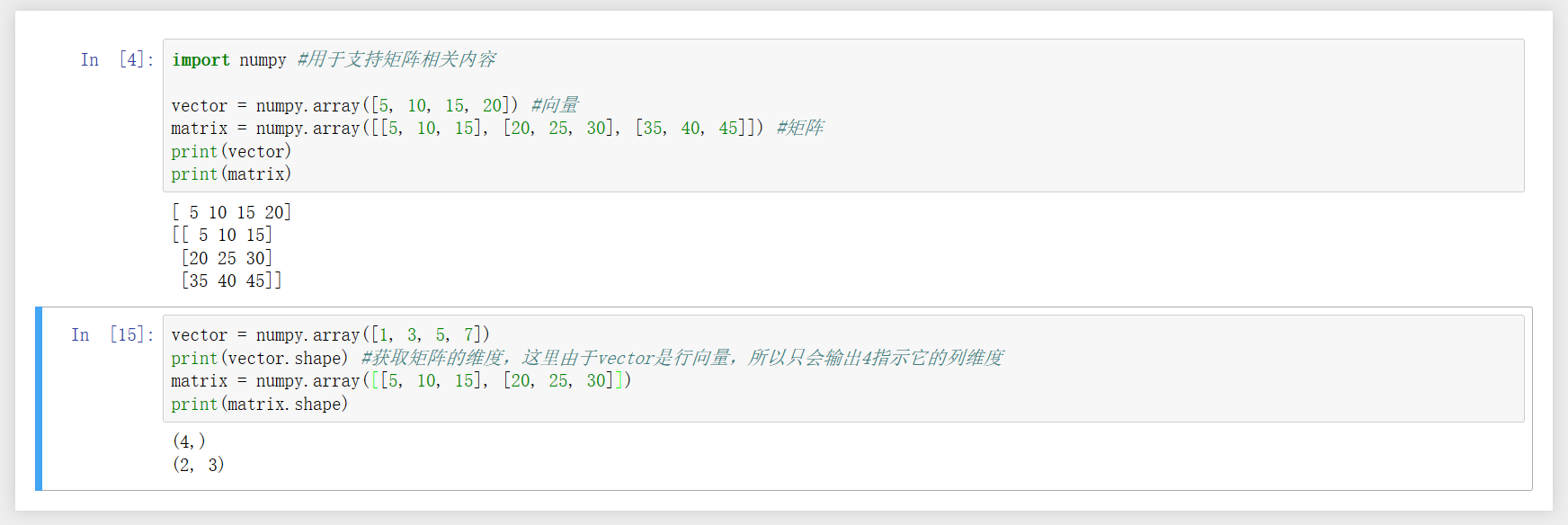
1、用shape获取矩阵维度。
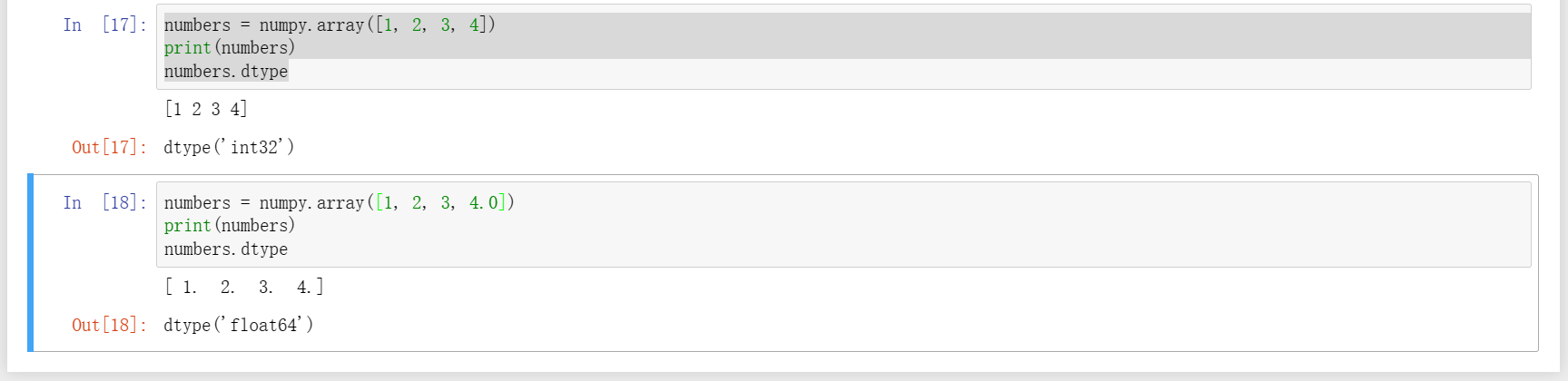
2、在list中是不限定数据的类型的,可以混杂各种不同的类型,但是在numpy中则要求数据均为统一的,不统一时会自动转换,如下图,另外观察可知,只将末尾4改成4.0,元素在打印时也有些许变化,变为以小数点结束的形式,如果想要更明显,可以改成字符‘4’再输出观察。
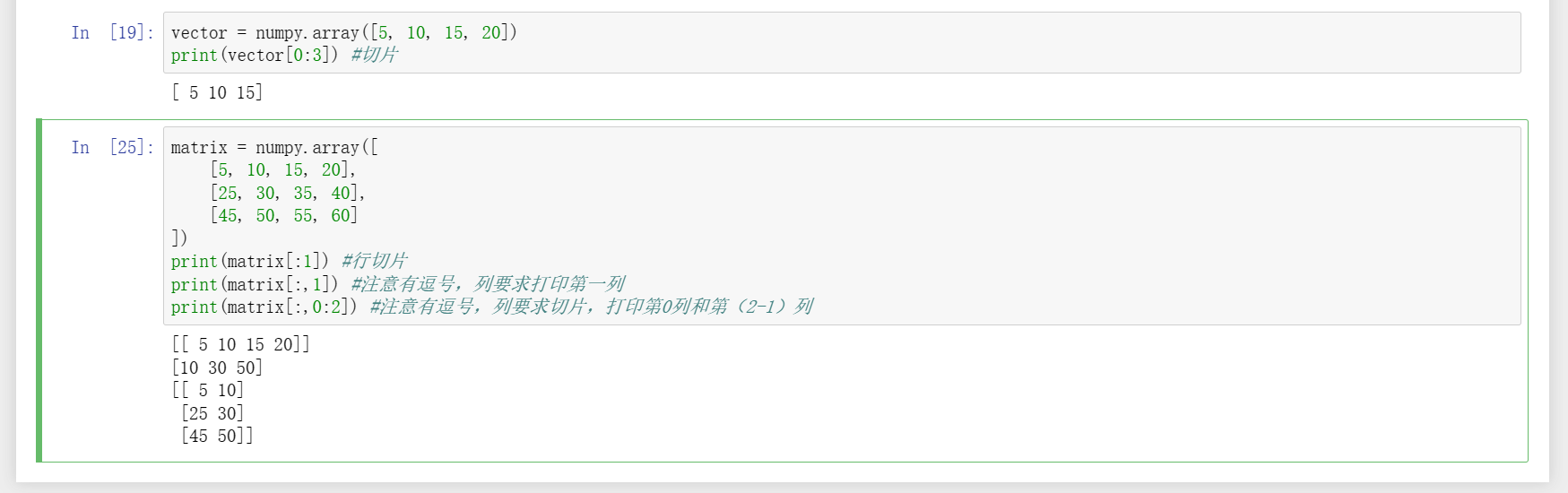
3、切片打印和非切片打印。
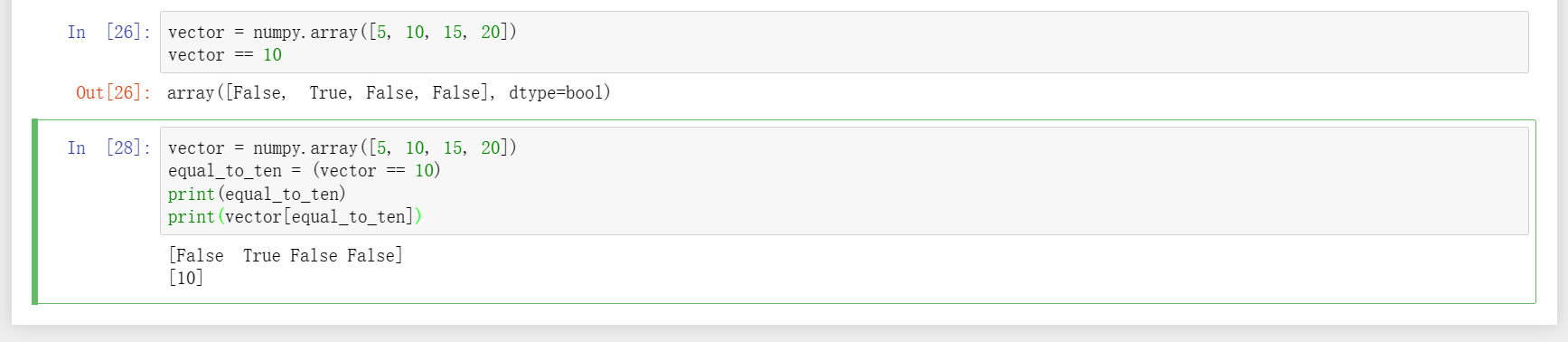
4、判断是否相等时,会将向量中每一个元素与条件内容都比较一次,比较结果以向量的形式显示,这时不仅可以看作下标索引而且如果将其传入原向量,将可以获取使条件成立的元素,同理,矩阵也类似。
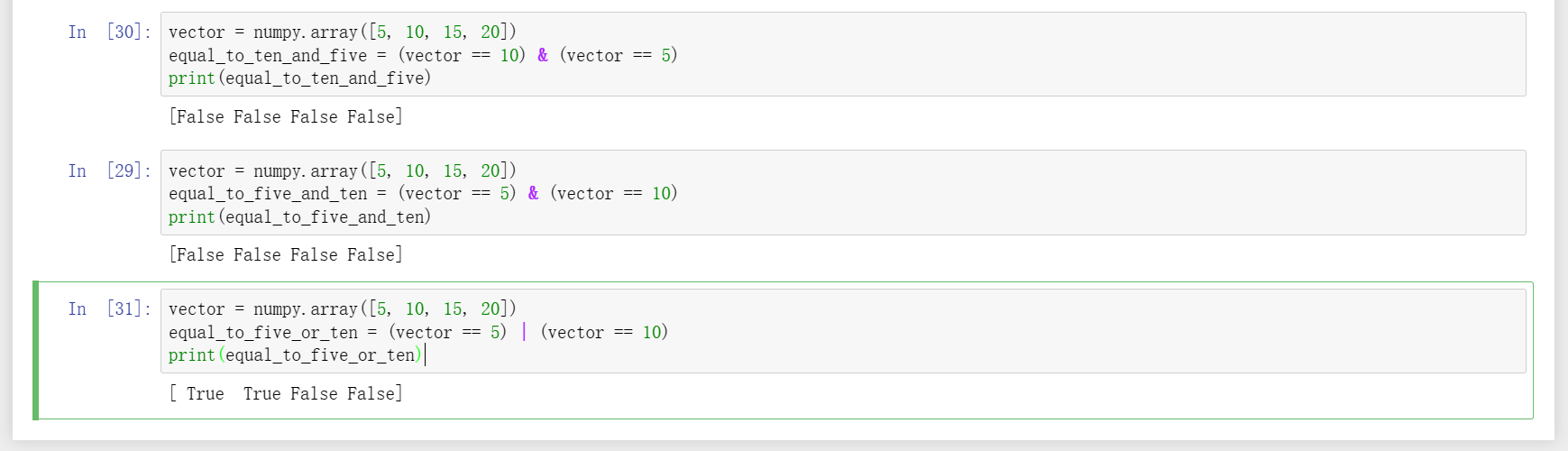
5、看到下图第一个例子输出结果时会理所当然地认为没问题,但是看到第二个例子结果也全都是False时,直觉反应是不是系统出错了,按说应该是[True True False False]吧,其实系统没错,而是直觉当中没把&重视起来所造成的,并且直觉还会顺其自然地把第一个条件和第二个条件一一对应到向量的第一个元素和第二个元素,看起来也一一匹配呀,殊不知,其实是每个向量元素要和所有条件逐个比较完才能轮到下一个元素,即元素:条件,在这里是1:2的关系,由于总共有4个元素,所以一共需要比较4*2=8次,而这里犯的直觉错误在于误认为第一个元素和第一条件比较,然后第二个元素和第二个条件比较,依次类推。
6、在第4点基础上加入了对查找到的匹配条件的值进行修改。

7、用astype将字符串类型转换成了整型。

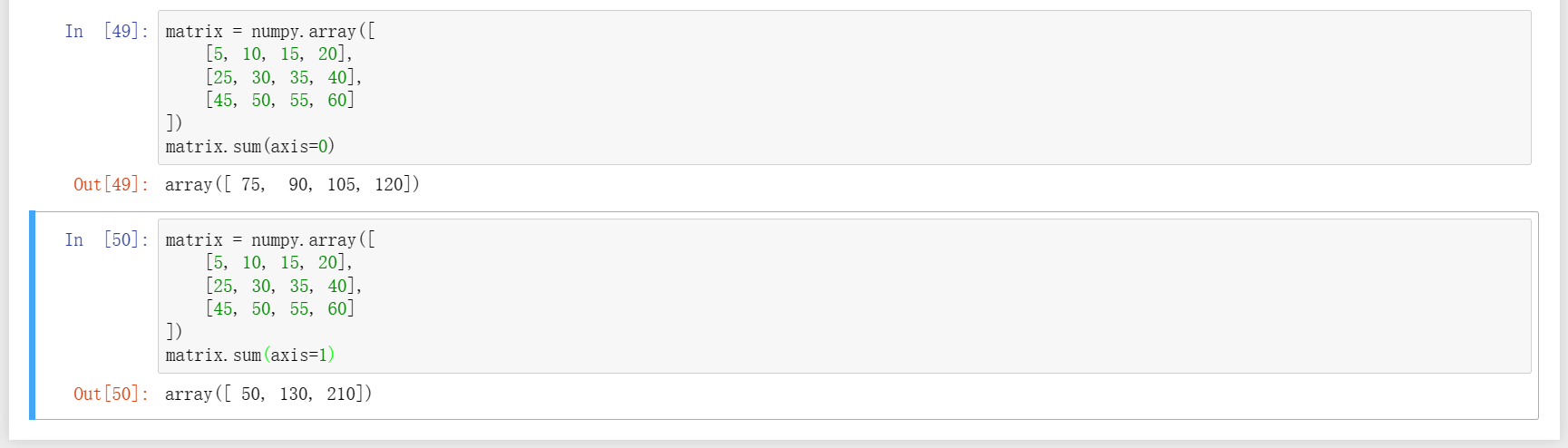
8、在求和的基础下,axis=0是对列求和,axis=0是对行求和。
9、reshape将list转换成按指定行列数的矩阵,再用shape可获取变换后矩阵的行列数(一般用于矩阵连续变换过程,观察是否出现错误) 。

10、numpy使用zeros()初始化矩阵时,默认初始化为float类型的0值,并且传入参数为元组(3,4),不能直接写成np.zeros(3,4),即小括号不能丢。

11、以下使用ones()初始化一个三维矩阵为全1值,并且指定数据类型。

12、arange()传入三个参数时,前两个参数指定起始和结束值,最后一个值为值之间的间隔,即步长,如果生成的值超过了结束值将不再纳入生成值列表里。

13、random()参数传入元组可以初始化成一个随机数矩阵,范围为-1到1(理论是这样说的,但实际测试发现并没有看见有负数?);另外,第一个random指的是numpy下的模块,第二个random是指random模块下的random函数,如果不写全两个random会报错。


14、基本运算,值得注意的是,要使用π,需要用语句提前导入pi。
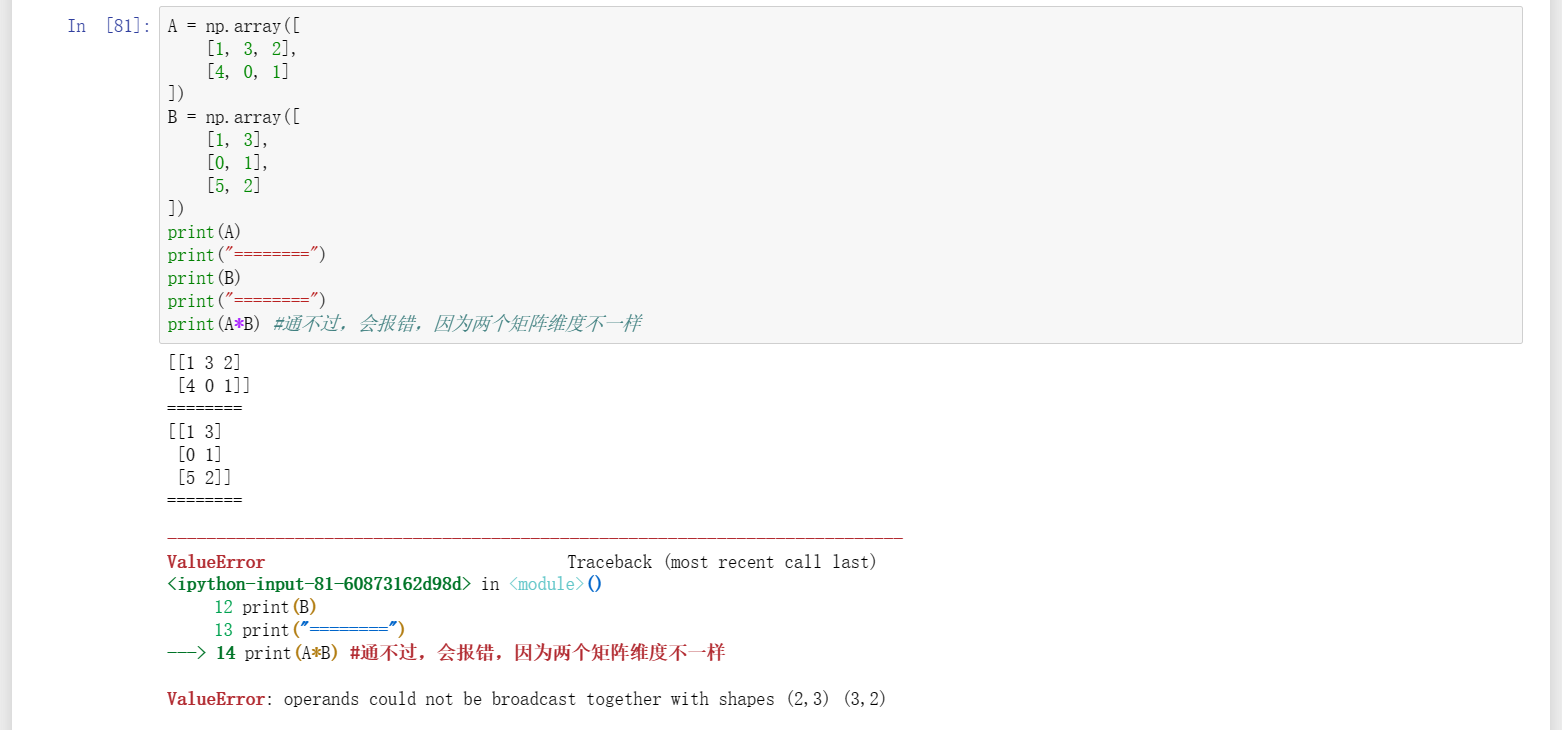
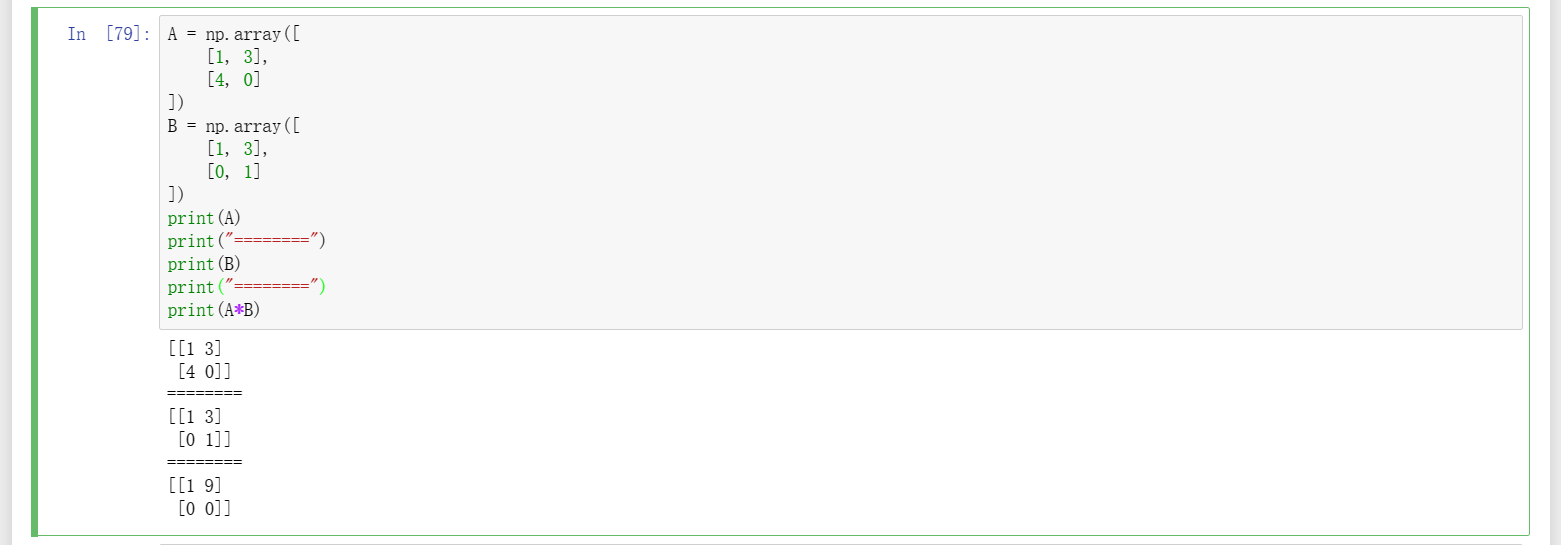
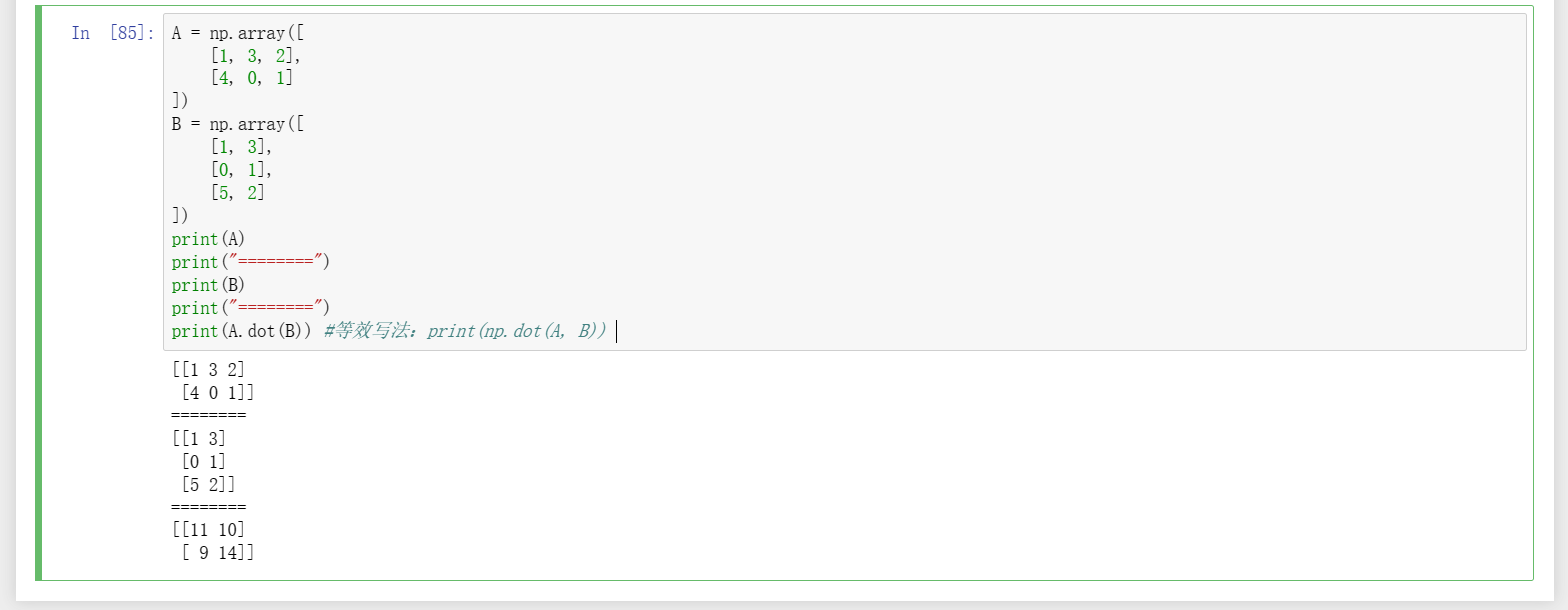
15、两矩阵內积A*B,要求两个矩阵必须都是相同维度,即行列数完全相等才可以,否则会报错,如下图一;将A、B两个矩阵都修改为2行2列,编译通过并打印相应结果,如下图二;但是这样一来就违背了最开始的想法,因为并不想修改数据,那这里大概率想要的就是矩阵乘法A ×B了,看图三,即;通过测试可以知道,矩阵內积是两个矩阵对应位置元素一一对应相乘的,所以才会有行列数完全相等的要求,而矩阵乘法则是整行乘以整列再相加的,所以要求的是行元素个数要对应列元素个数,这里找了內积和叉乘的文章做参考:(1)https://blog.csdn.net/XIAOSHUCONG/article/details/115717893,(2)https://www.bilibili.com/read/cv14355096/。
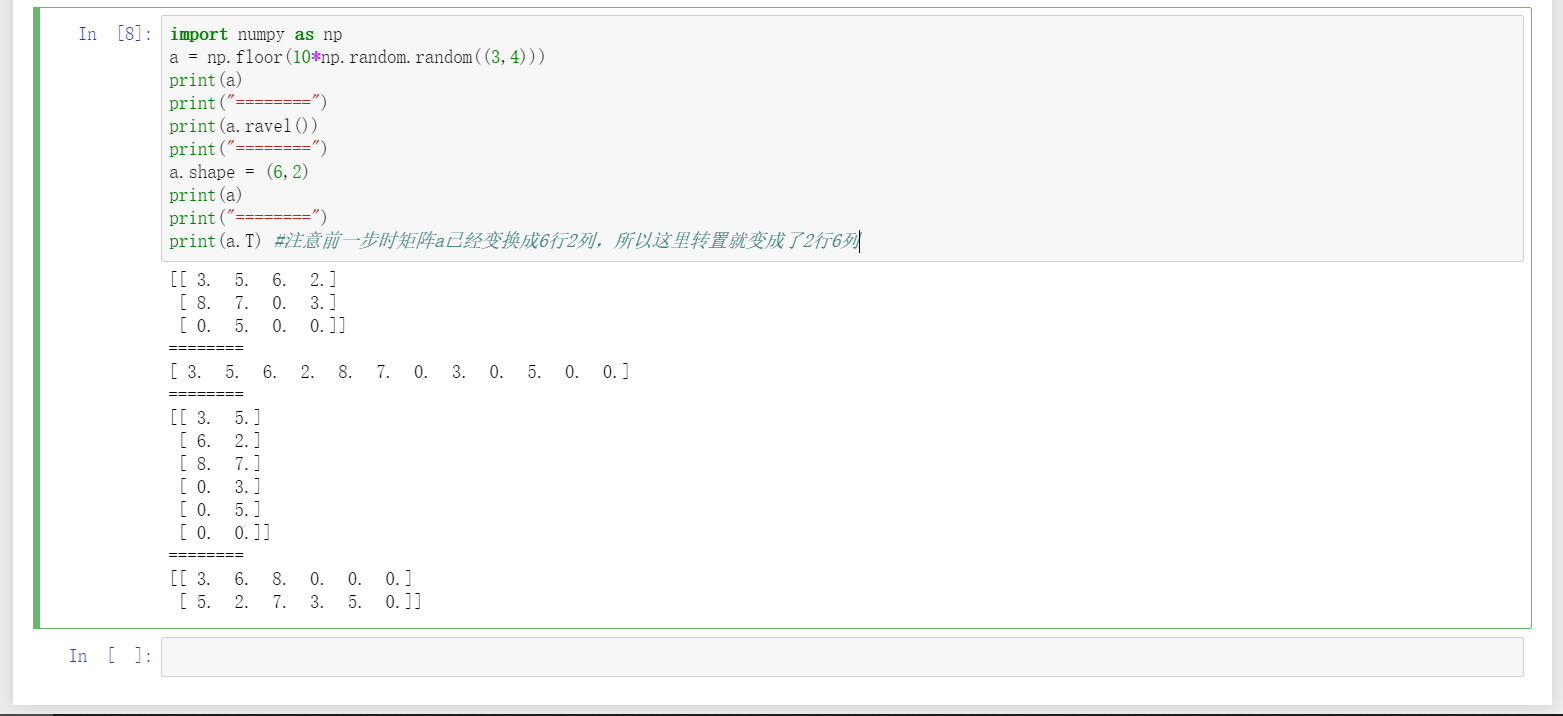
16、用floor()对已经放大10倍的随机数矩阵进行向下取整;用ravel()对矩阵进行横向扩展,可看做reshape()的逆操作;除了可以用reshape()使行向量按指定行列数进行矩阵变换,还可以通过shape直接指定行列数使其变换成对应的矩阵。
17、用vstack实现行拼接、hstack实现列拼接,要注意的是传入a和b矩阵时需要用元组方式。
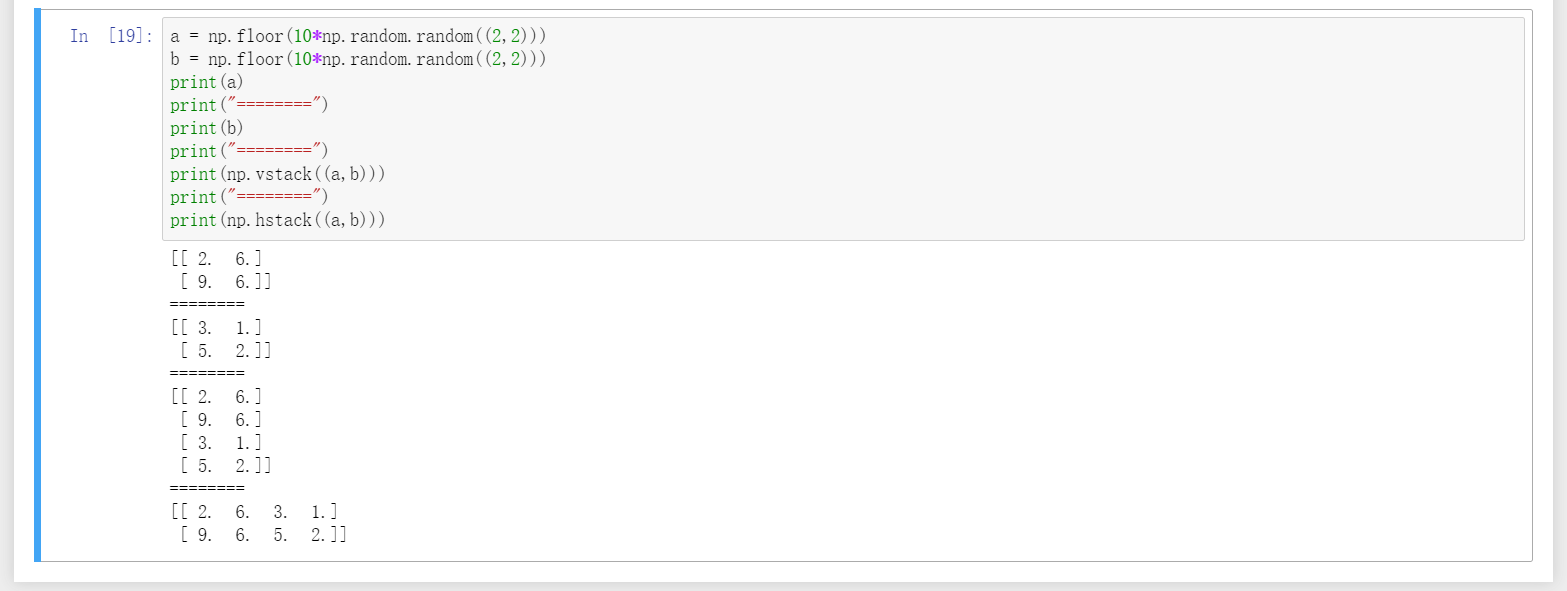
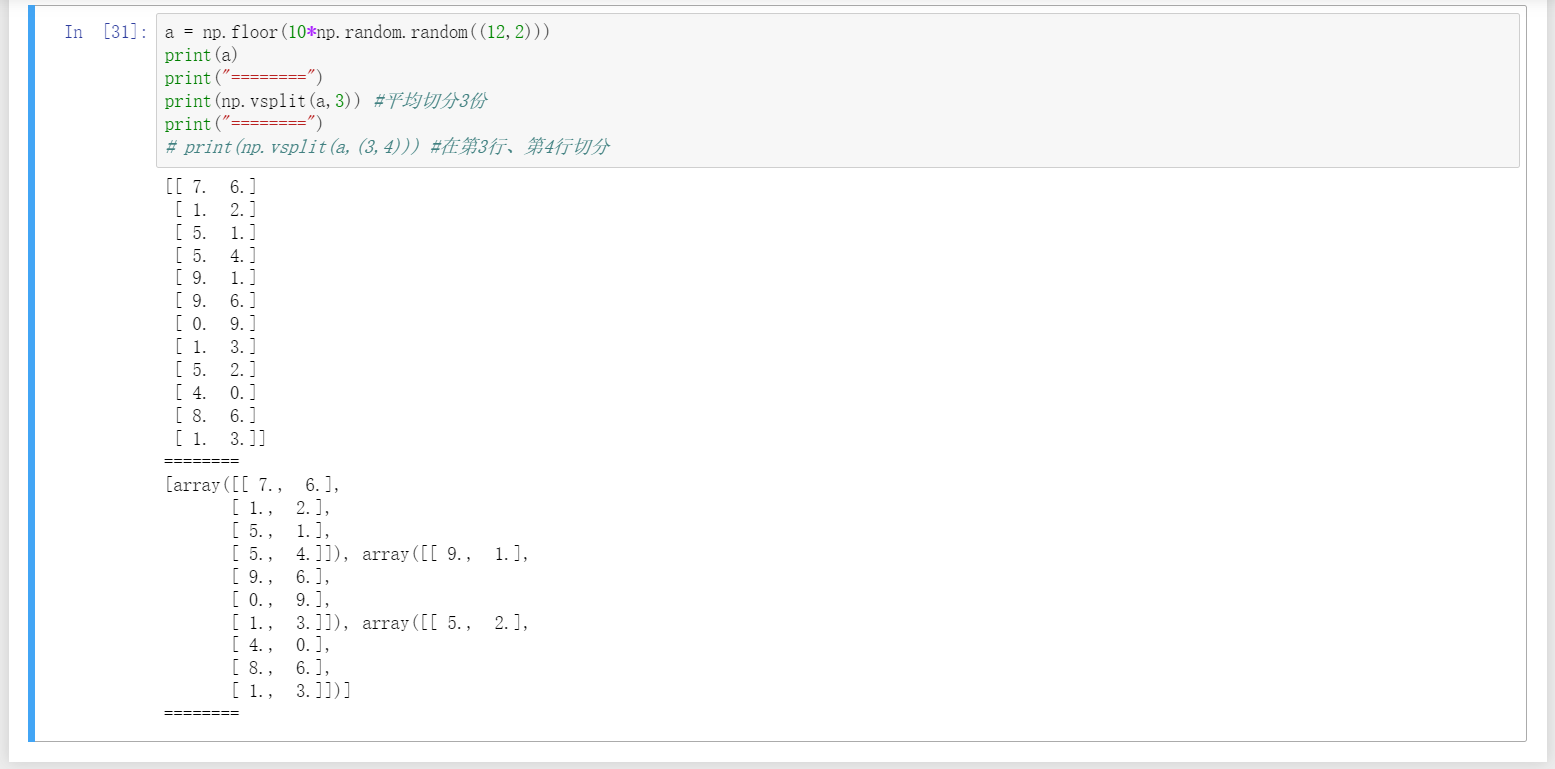
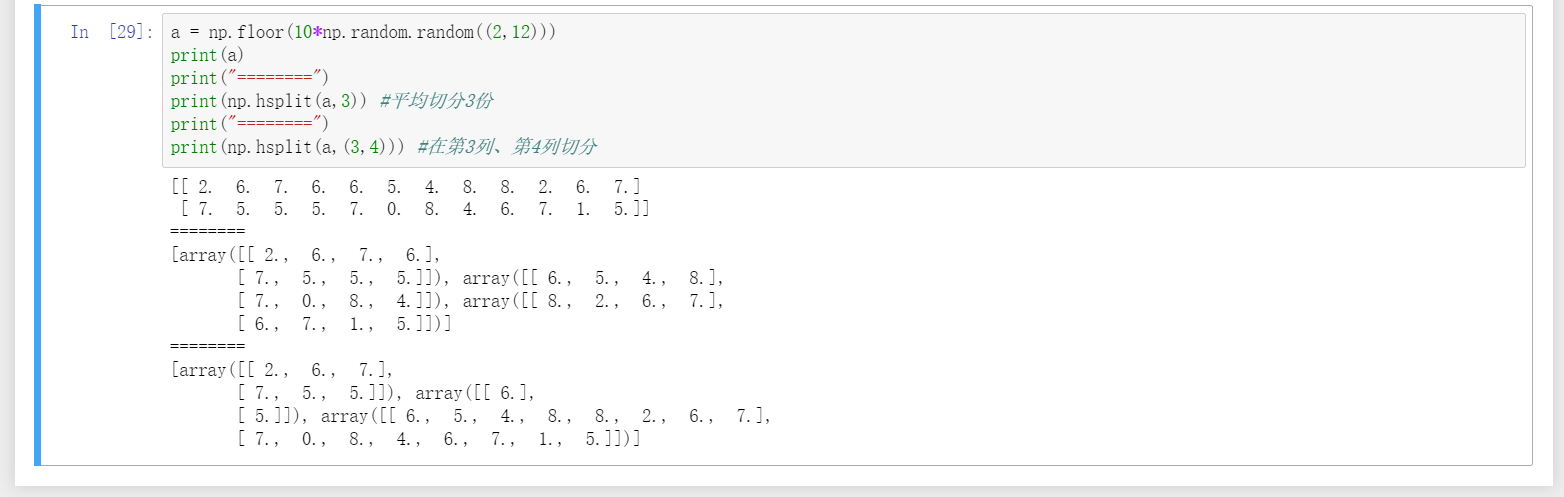
18、用vsplit实现行切分、hsplit实现列切分。
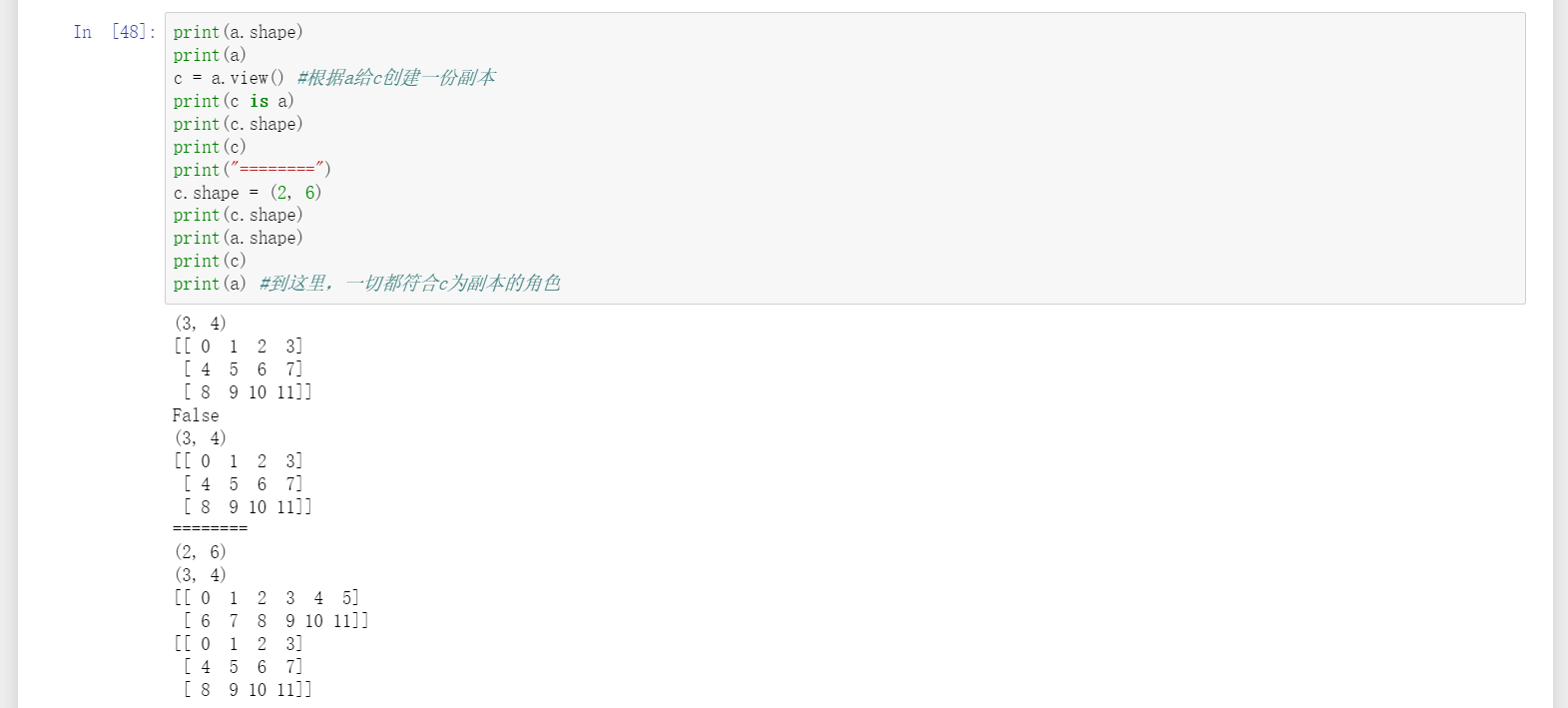
19、关于深浅拷贝,不推荐使用view(),推荐使用copy(),容易出错可能是由于直接用了赋值号“=”,这时a和b是同一个矩阵,只是b是a的别名而已。


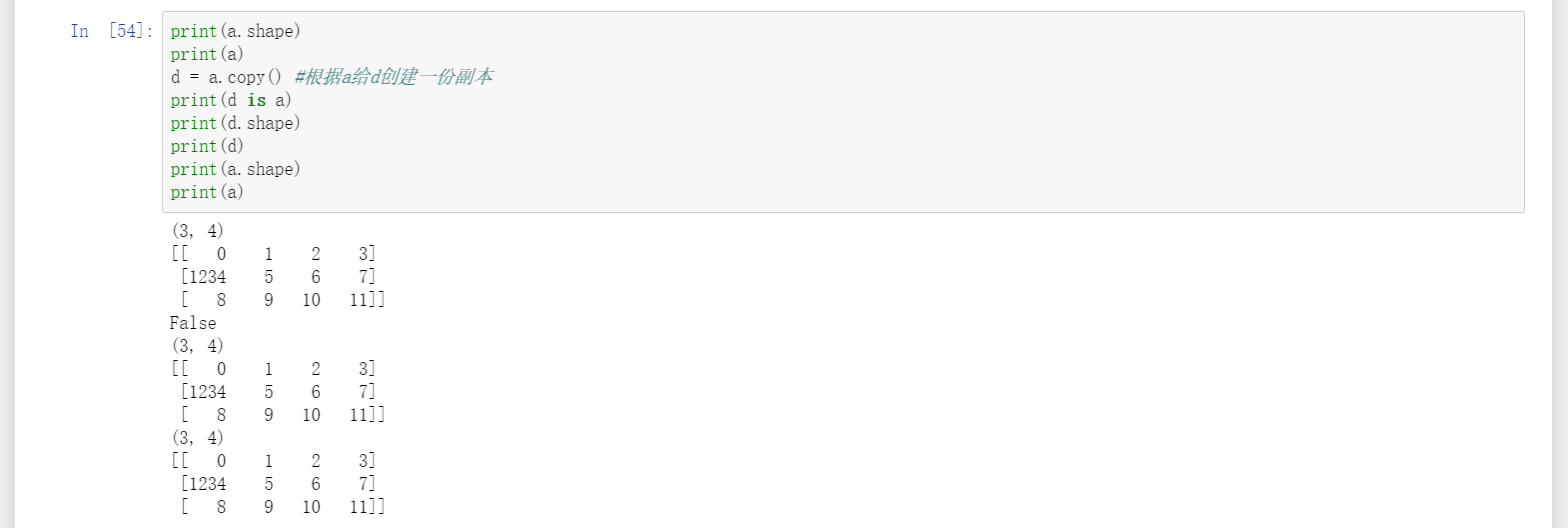
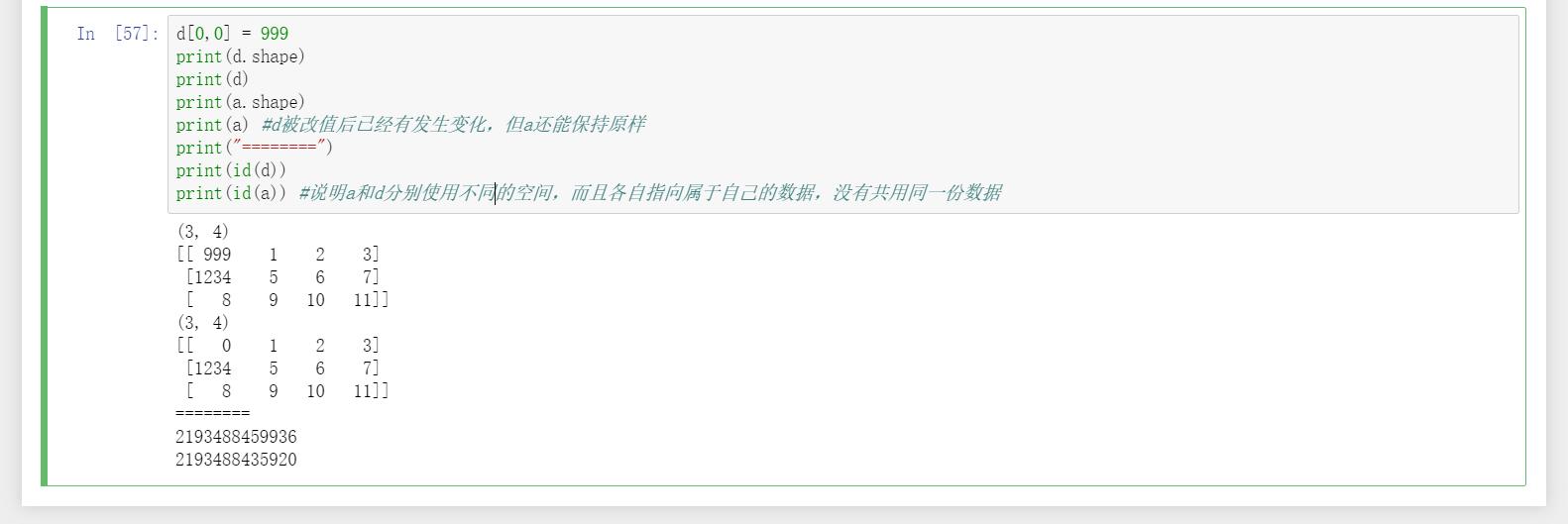
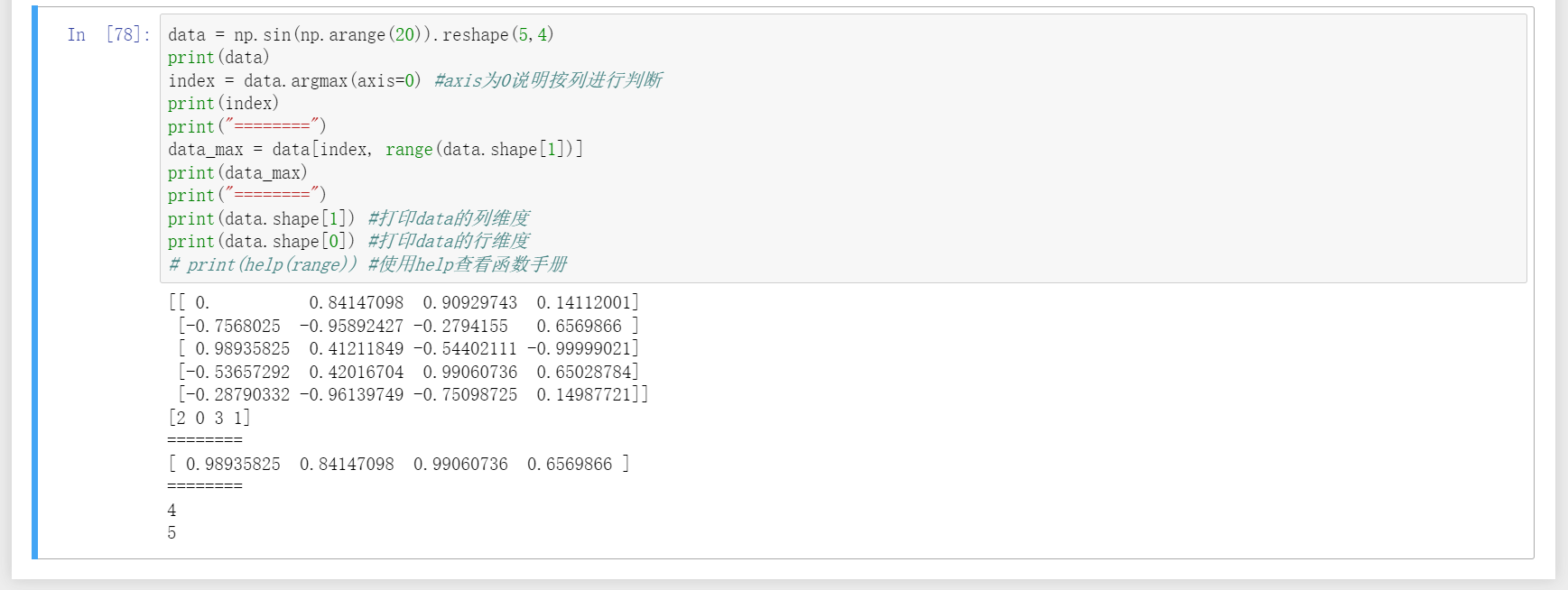
20、argmax用于按行或列找出该行或列最大值的下标。
21、tile以传入向量(或矩阵)为基础按指定行列进行复制和堆叠。

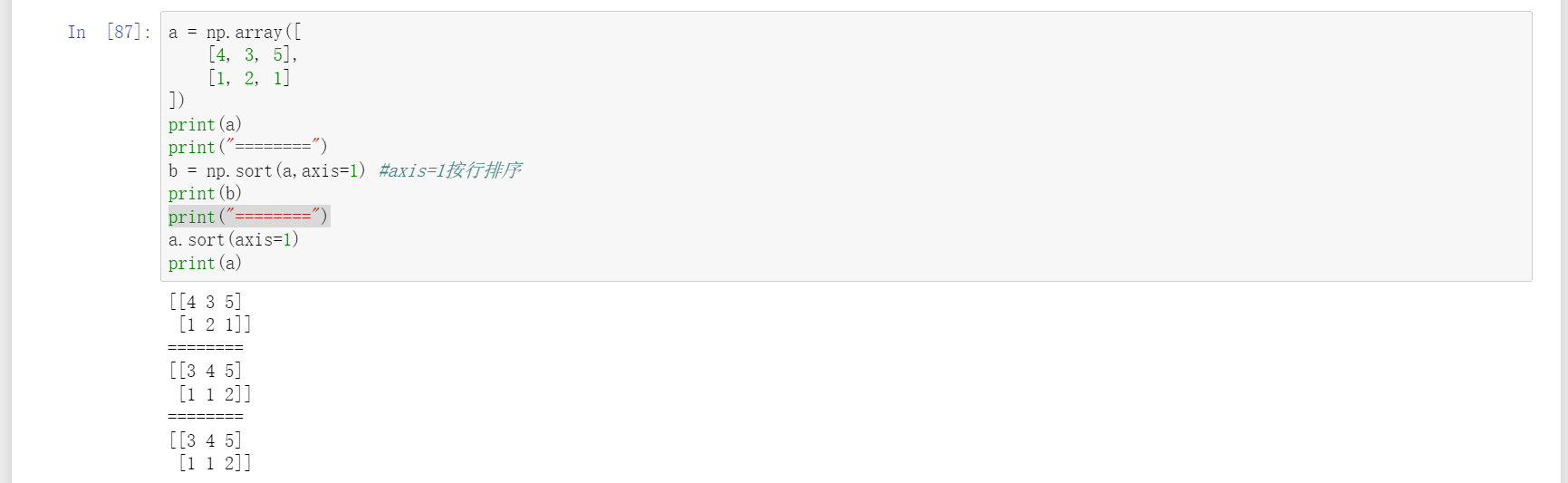
22、sort按行或列对传入矩阵进行升序排列。
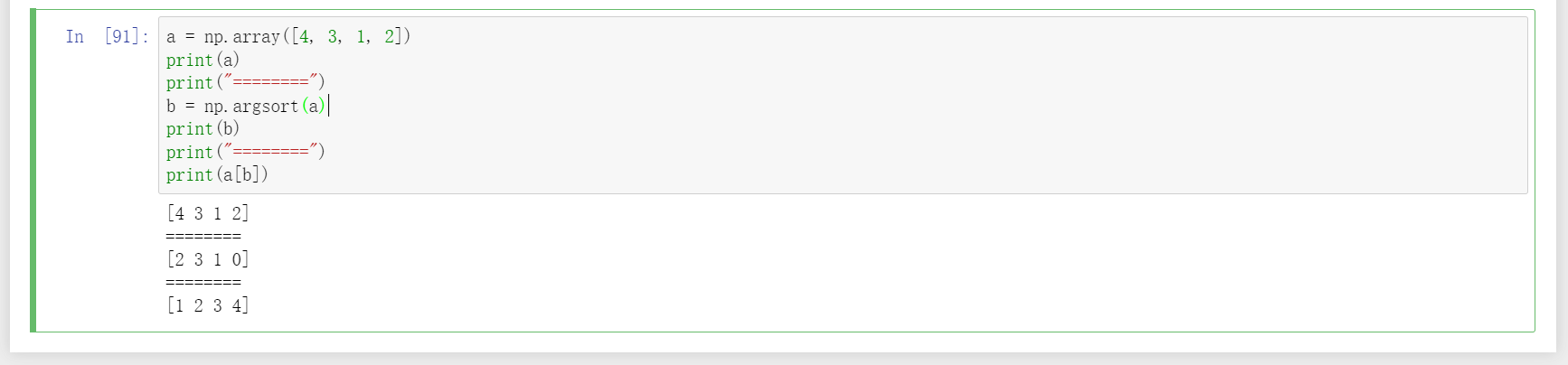
23、argsort可用于找出向量中从最小值到最大值各元素的下标。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!