python-2020-09-25
1、单行注释用#,多行注释时,三个单引号(双引号)作为开始,对应地用三个单引号(双引号)作为结束。
2、多行注释还可以用作多行打印,譬如:
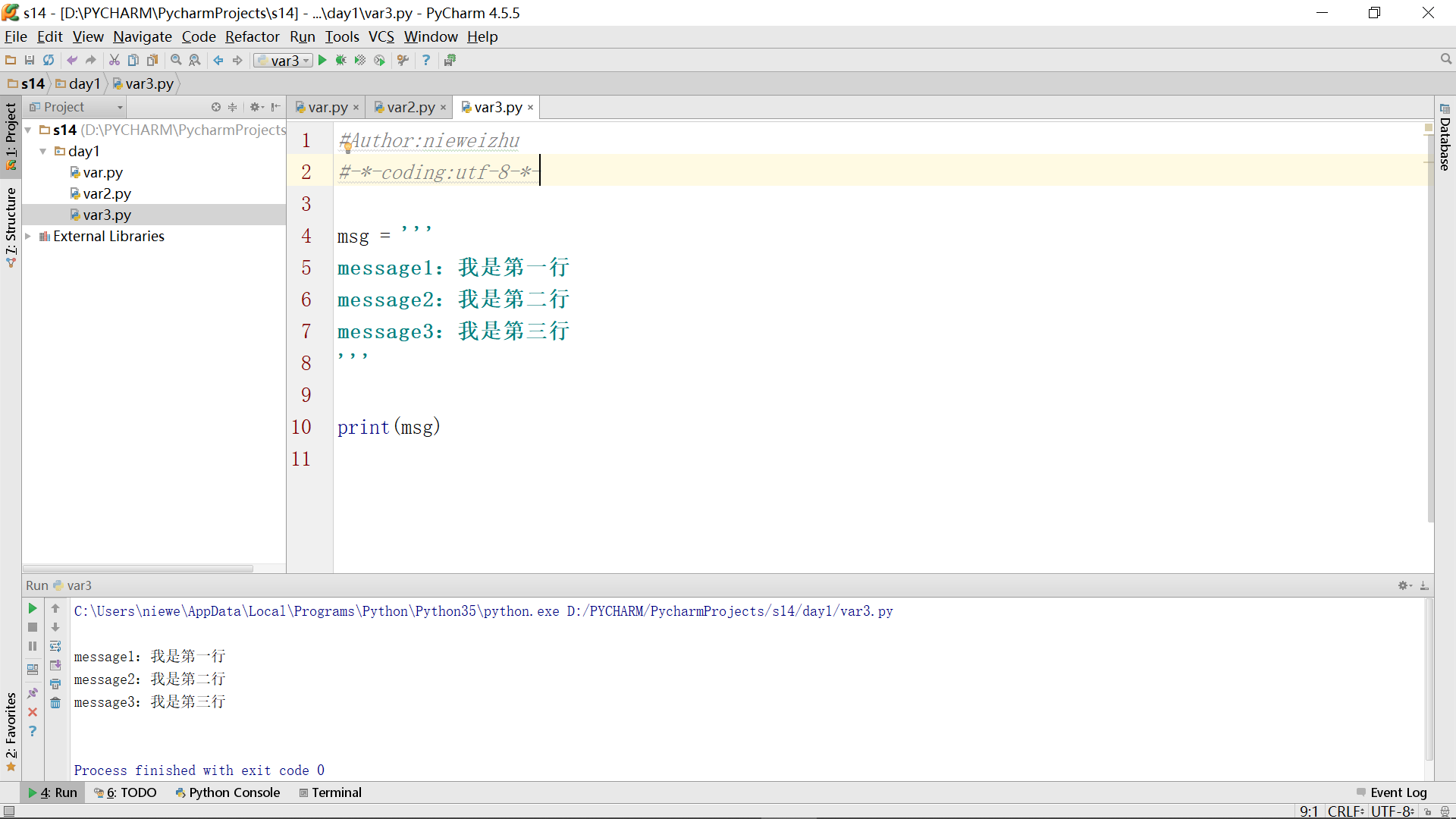 3、在编译上面的例程时,如果程序中出现中文了但没有告诉编译器使用何种编码,会出现下面这种提示:
3、在编译上面的例程时,如果程序中出现中文了但没有告诉编译器使用何种编码,会出现下面这种提示:
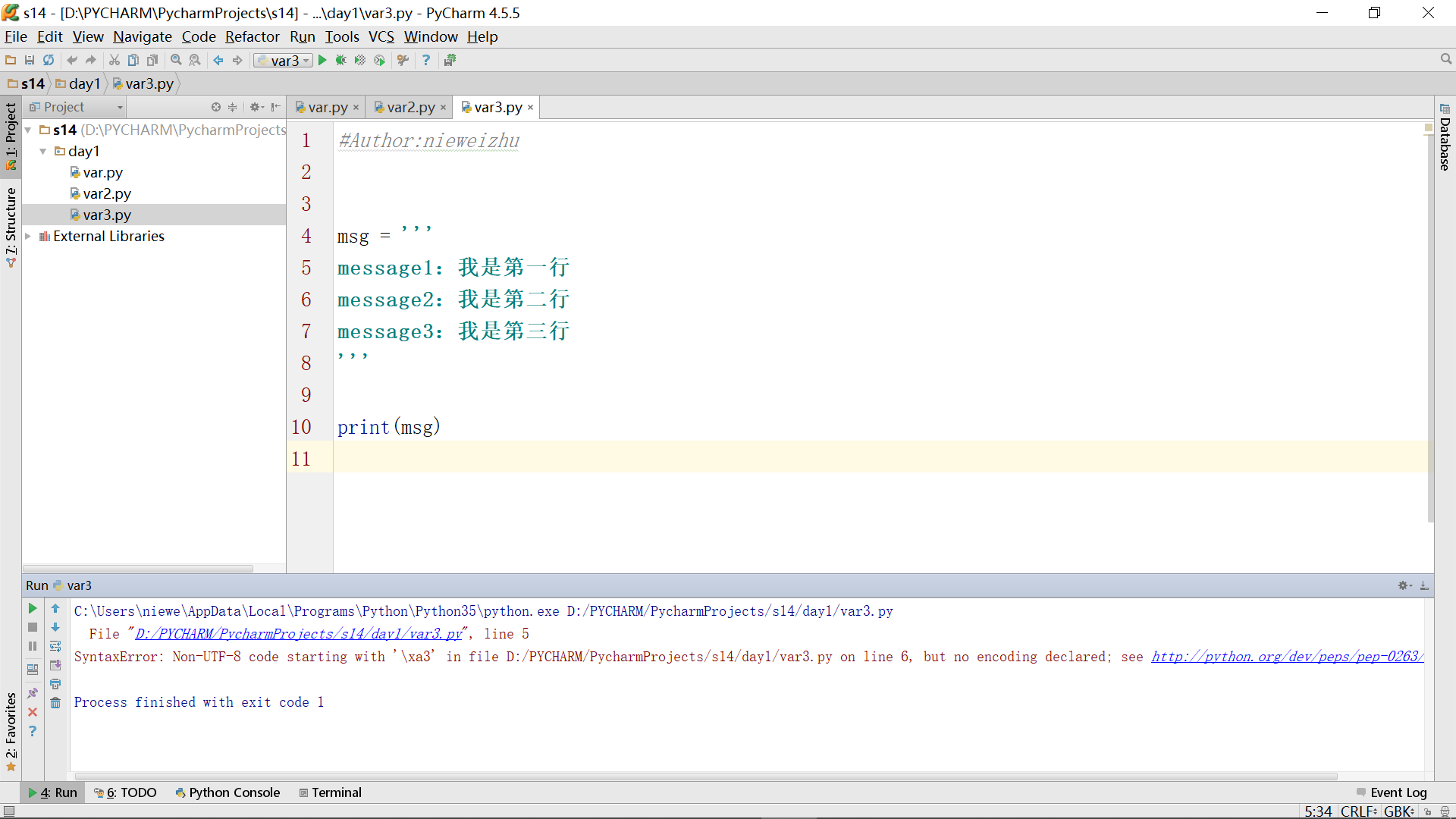
网络上有的解决办法是直接通过最右下角来修改编码格式,但这种方式会导致原来已经打好的汉字变成乱码,需要重新将所有乱码修改成中文,所以不推荐。
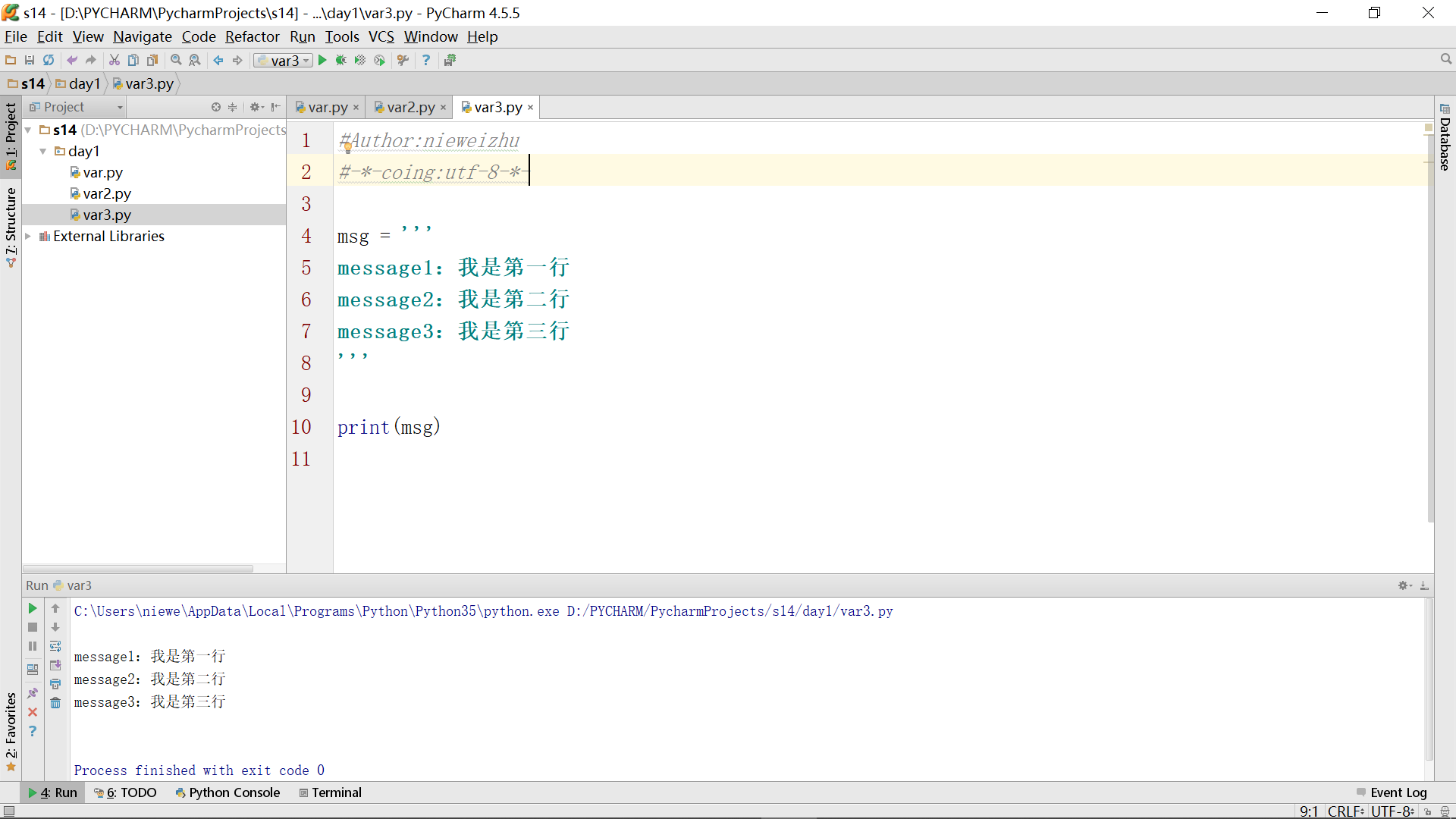
另一个办法那就是使用语句告诉编译器使用何种编码格式来编译,针对这里的情况,可以在起始的地方加上#-*-coding:utf-8-*-,现象如下:
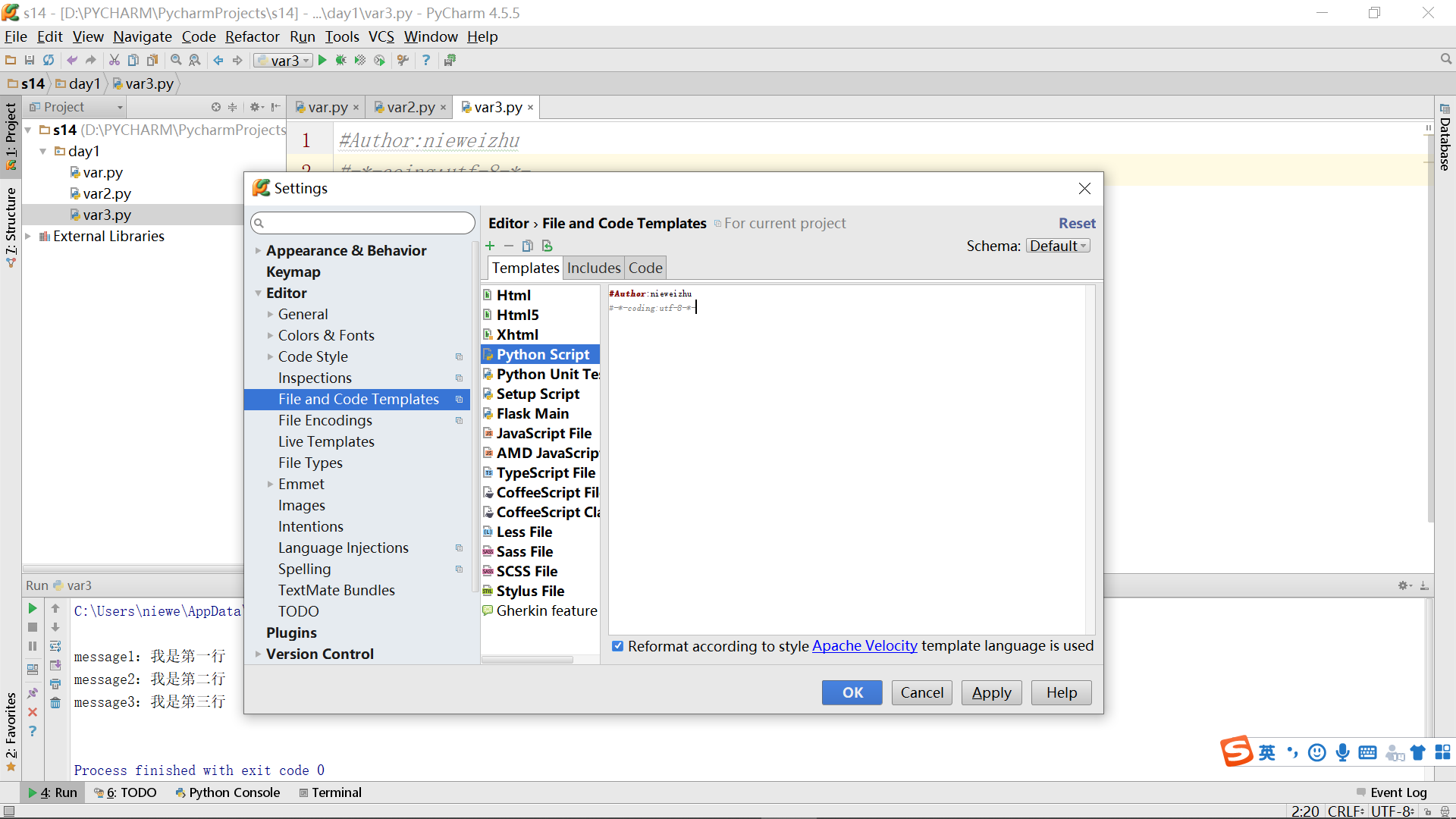
 为了不用每次麻烦都要写一次,可以将该语句放到预编译中,而每一次新建文件就都能自动附带上这一语句但又不用重复输入了,做法如下:
为了不用每次麻烦都要写一次,可以将该语句放到预编译中,而每一次新建文件就都能自动附带上这一语句但又不用重复输入了,做法如下:
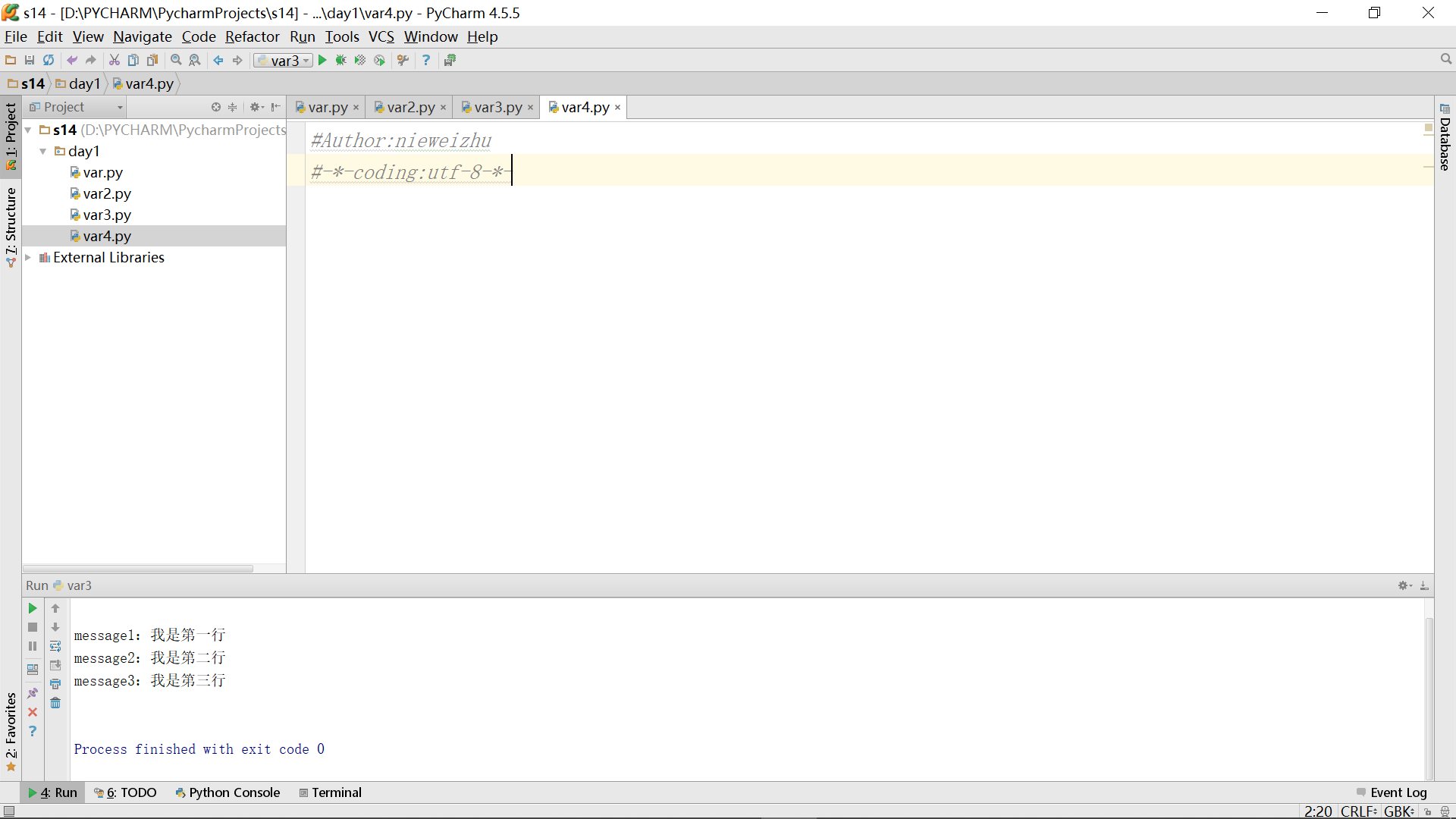 4、实现字符的输入和拼接:一开始只能录入,但没办法显示到多行注释里头对应的位置里去。
4、实现字符的输入和拼接:一开始只能录入,但没办法显示到多行注释里头对应的位置里去。
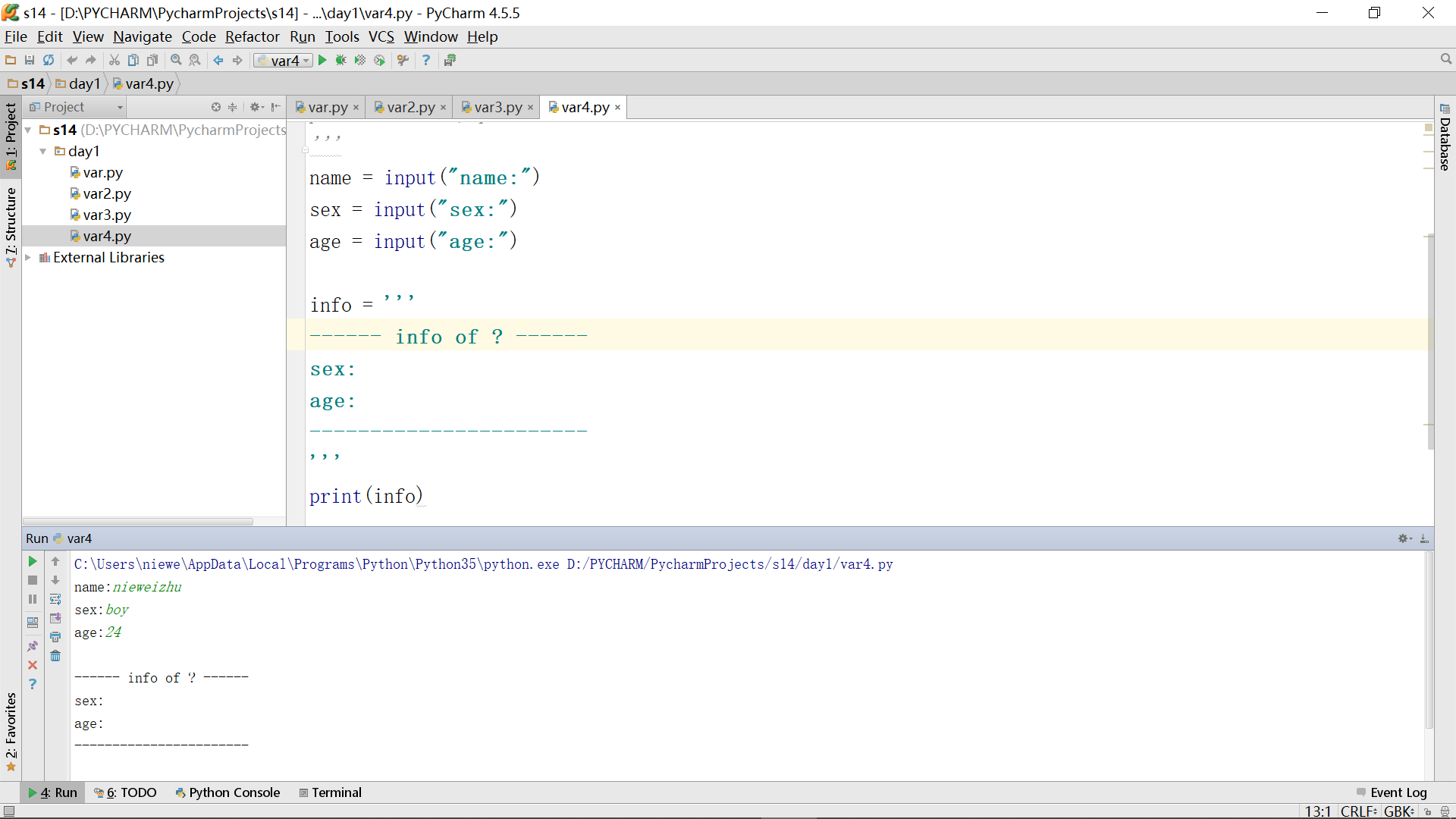 这时,还是继续使用基本功能“字符拼接”,来尝试能否完成效果:
这时,还是继续使用基本功能“字符拼接”,来尝试能否完成效果:
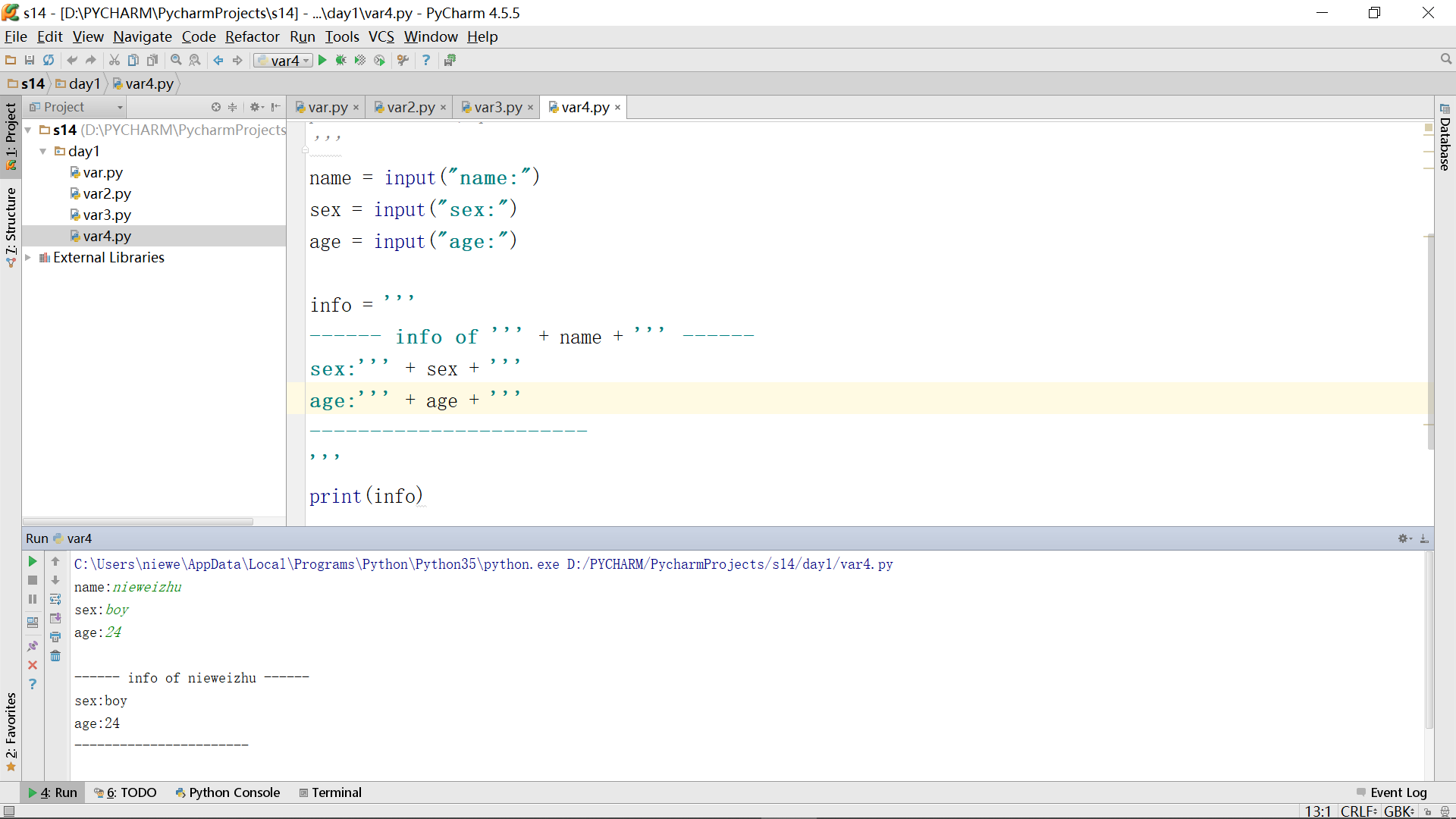 但是上面这种办法太过麻烦,需要考虑采用别的办法,在此之前,遇到了以下麻烦:
但是上面这种办法太过麻烦,需要考虑采用别的办法,在此之前,遇到了以下麻烦:
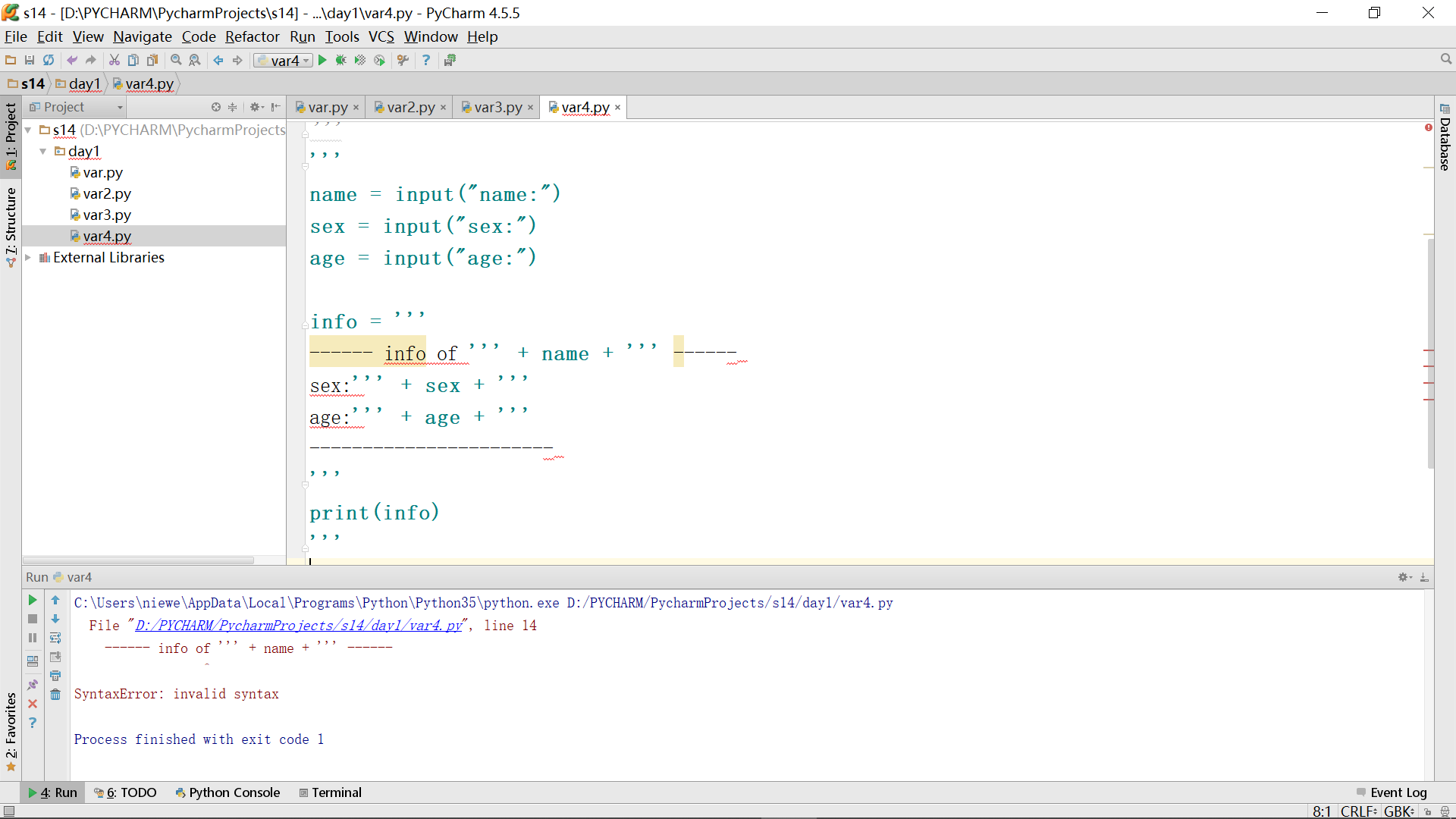 因为原来的内容已经有三个单引号的注释了,所以想要再使用三个单引号进行多行注释就起不了作用了,这时,只需要换成双引号对含有三个单引号注释过的内容进行全部注释,如下:
因为原来的内容已经有三个单引号的注释了,所以想要再使用三个单引号进行多行注释就起不了作用了,这时,只需要换成双引号对含有三个单引号注释过的内容进行全部注释,如下:
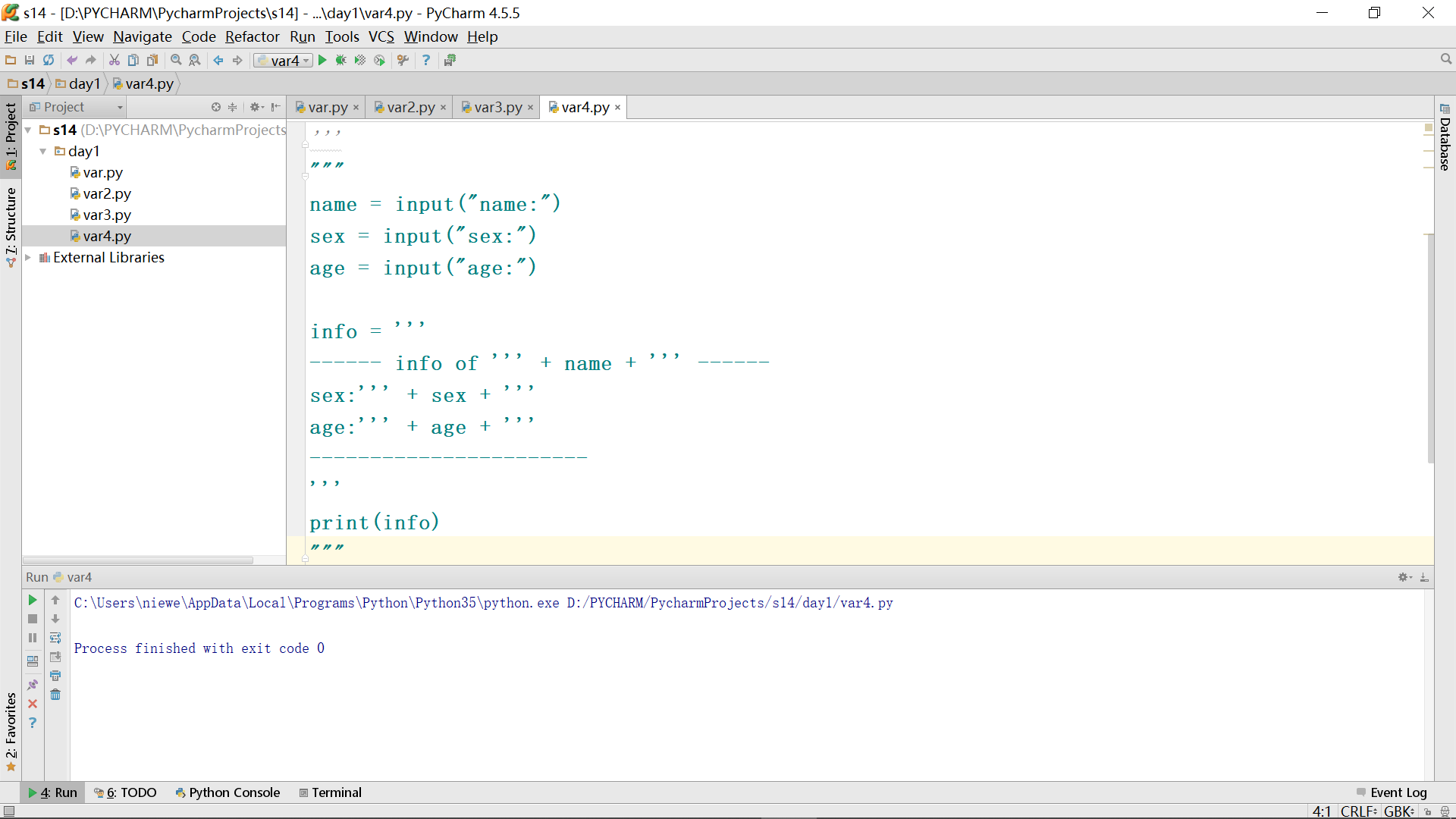 解决掉途中冒出来的程咬金,就正式进入正题了:
解决掉途中冒出来的程咬金,就正式进入正题了:
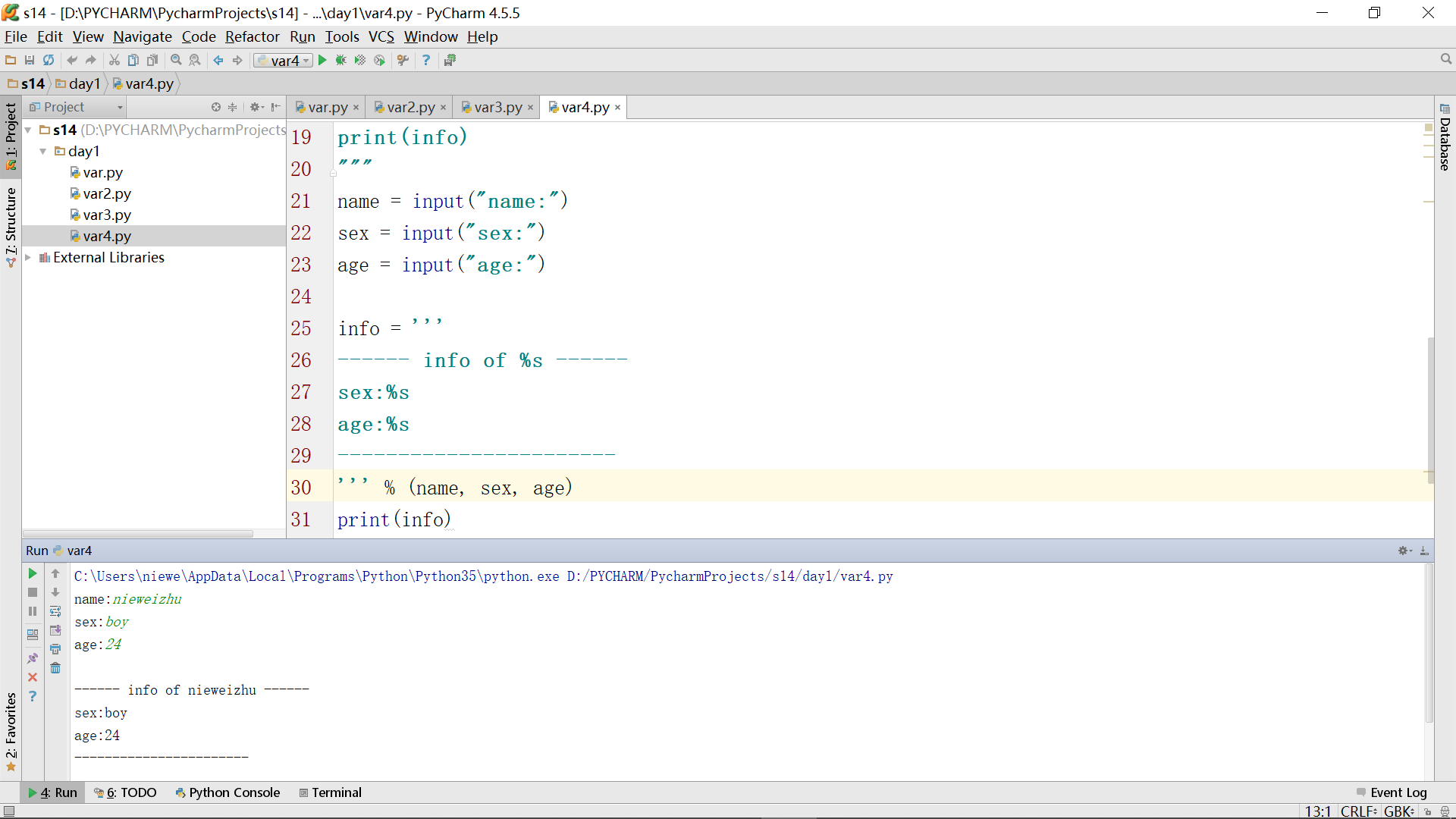 但其实age这里还有问题,因为本来它要求的是数字,但是我们使用的是%s(即%string),这样就不太妥当了,所以把例程改一下得到:
但其实age这里还有问题,因为本来它要求的是数字,但是我们使用的是%s(即%string),这样就不太妥当了,所以把例程改一下得到:
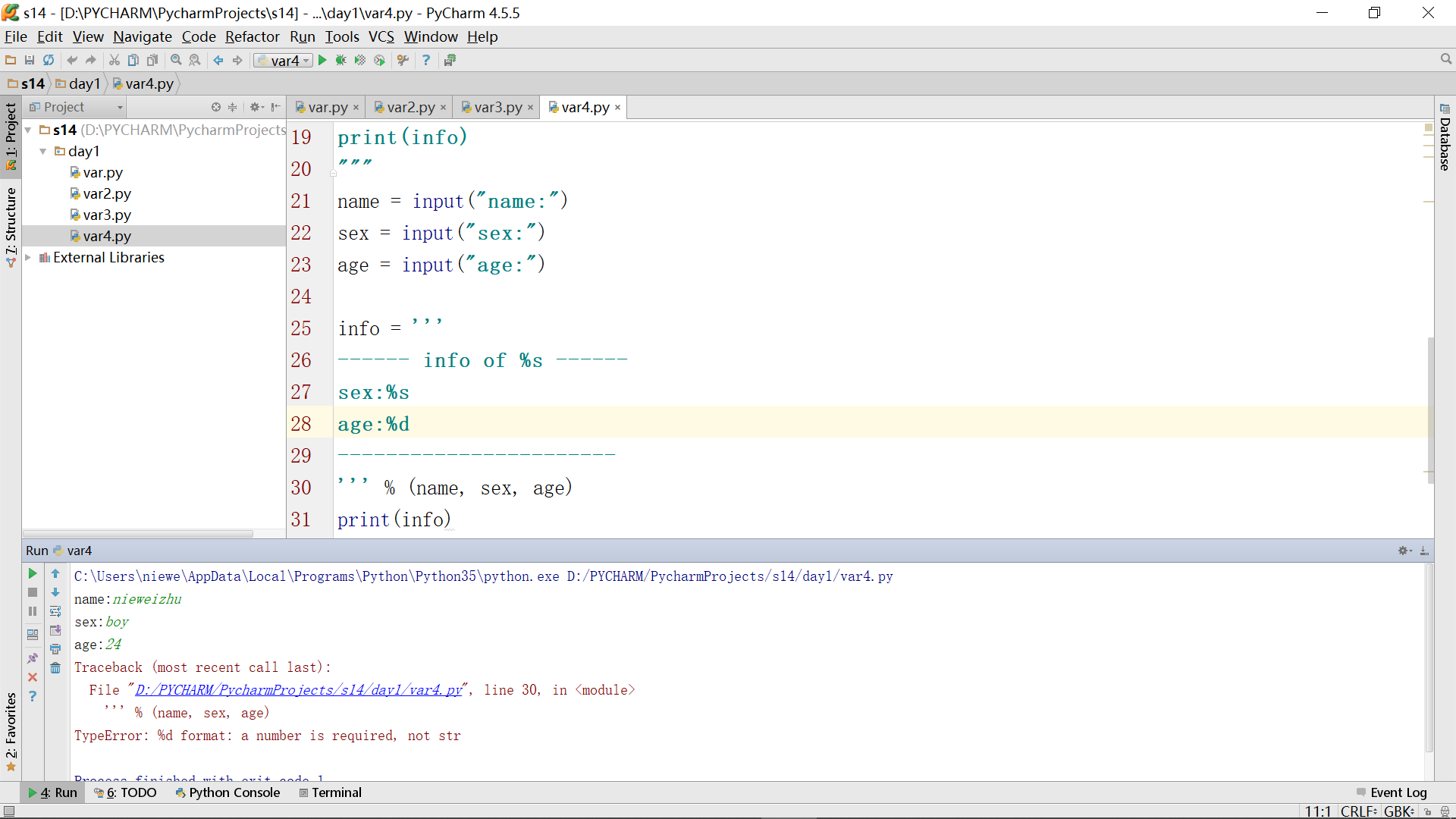 得到了一个错误,这里如果需要快速定位错误所在行数,可以直接单击红色错误提示中被双引号引起来的深蓝色部分内容即可。
得到了一个错误,这里如果需要快速定位错误所在行数,可以直接单击红色错误提示中被双引号引起来的深蓝色部分内容即可。
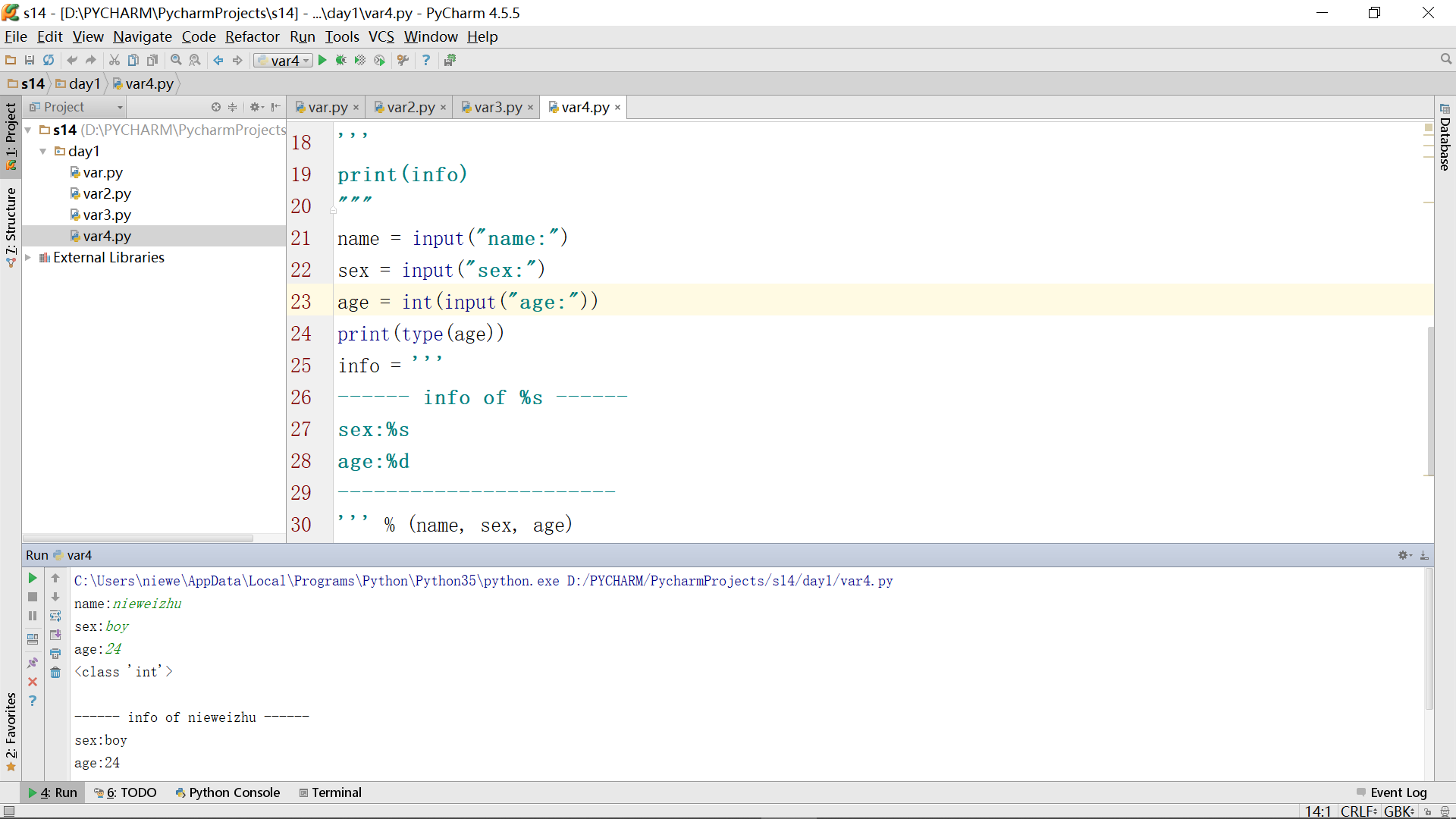
这里的错误表面上是不容易看出来的,明明录入变量时是按顺序进行录入的,而且录入的age的确也是24,这其实是由于python中默认将你没指定的类型统一为string类型所导致的,所以刚刚在录入age的时候,确实是24,但是这已经被编译器当string来处理了,而我们在info中引用age时已经指定要int类型了,这时录入时为string的24被放到%d就自然地造成编译错误了。
调试时,可以在age变量处使用语句将变量的类型打印出来查看,发现录入的age确实是string类型的:
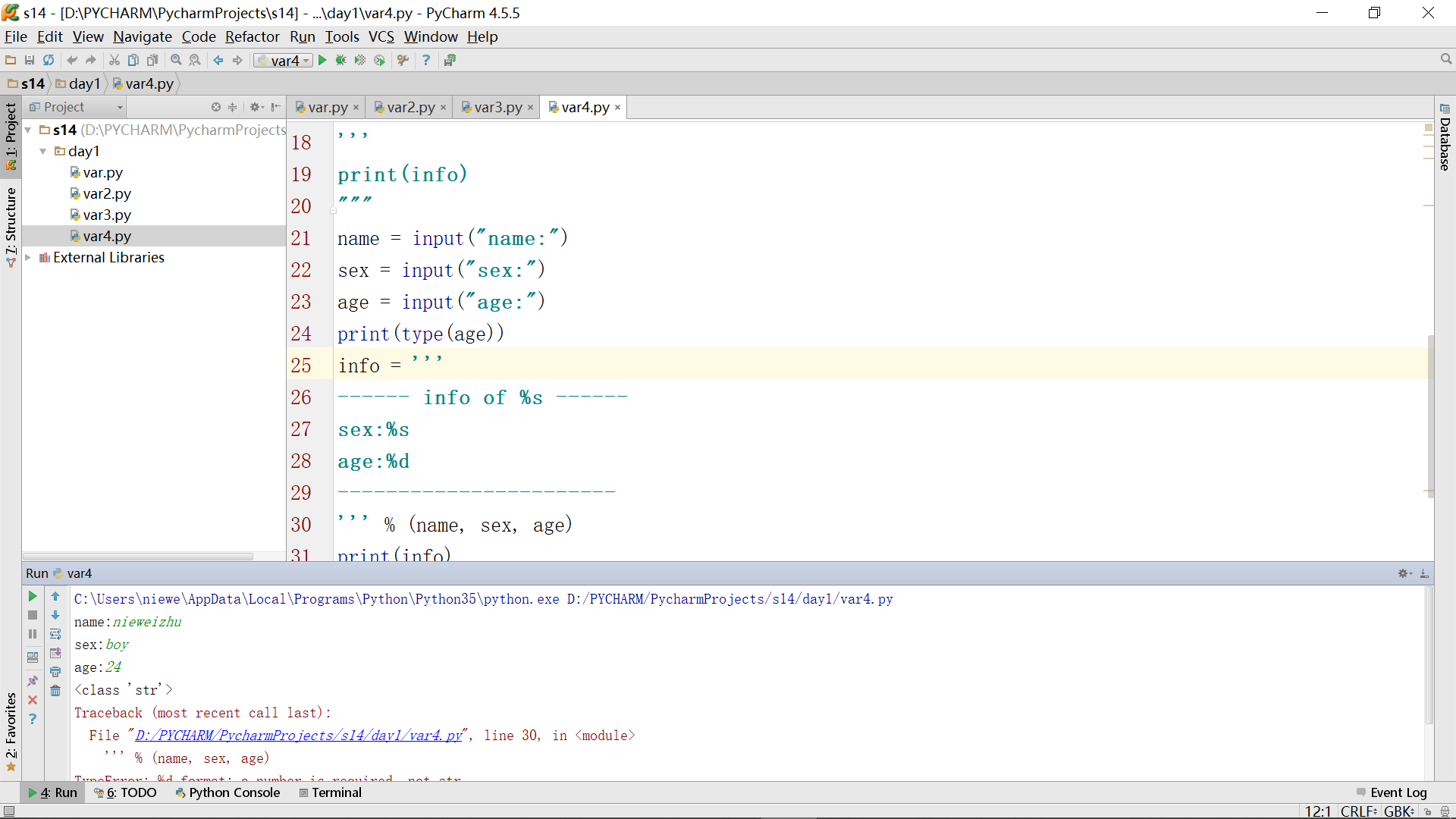 为了解决,可以采用强转的办法:
为了解决,可以采用强转的办法:
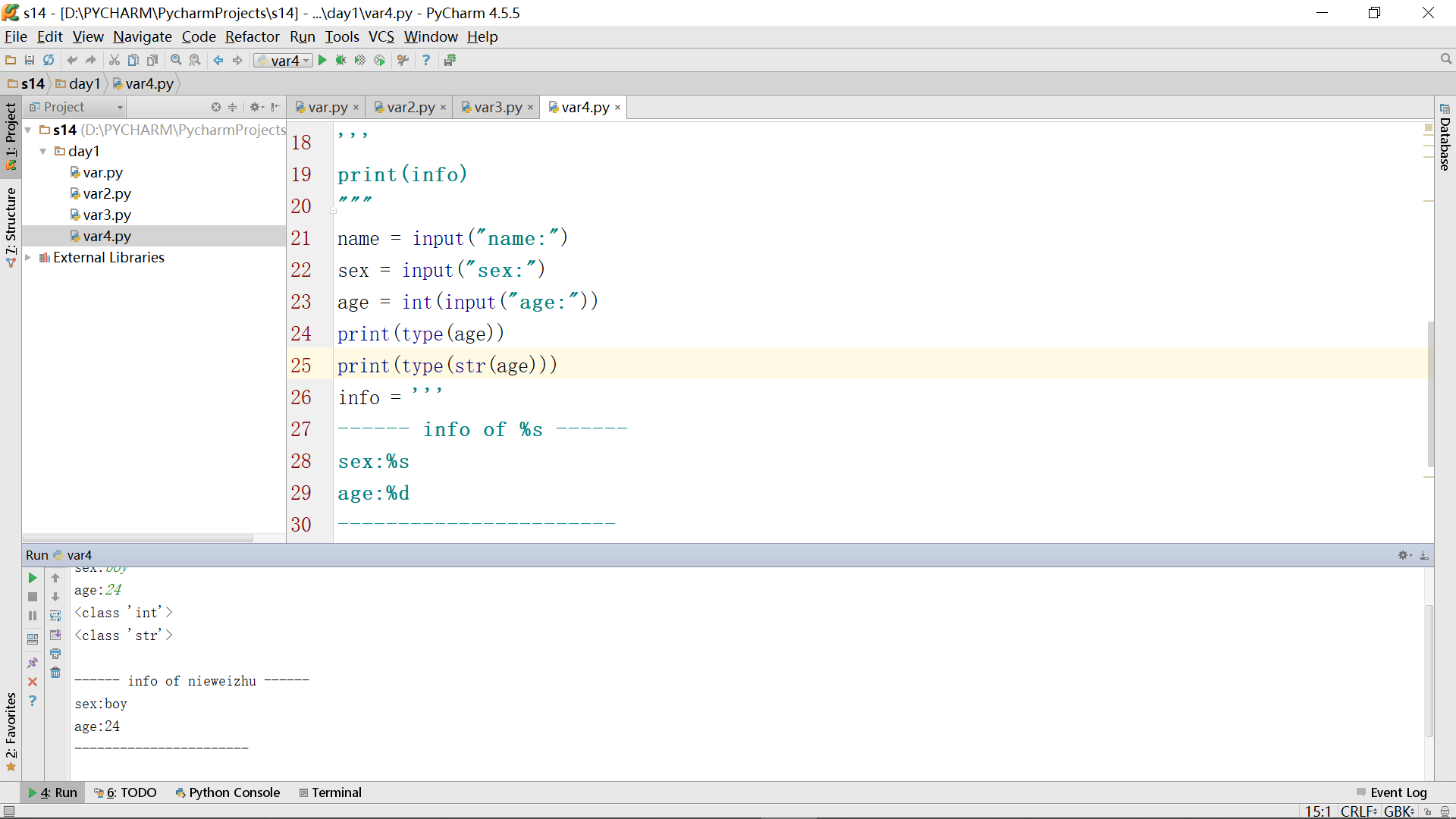
 如果还想将int转回去string,可以看如下第25行:
如果还想将int转回去string,可以看如下第25行:
 5、raw input只在python2.x中,在python3.x中没有raw input,用的是input,但两者的效果是一样的。
5、raw input只在python2.x中,在python3.x中没有raw input,用的是input,但两者的效果是一样的。
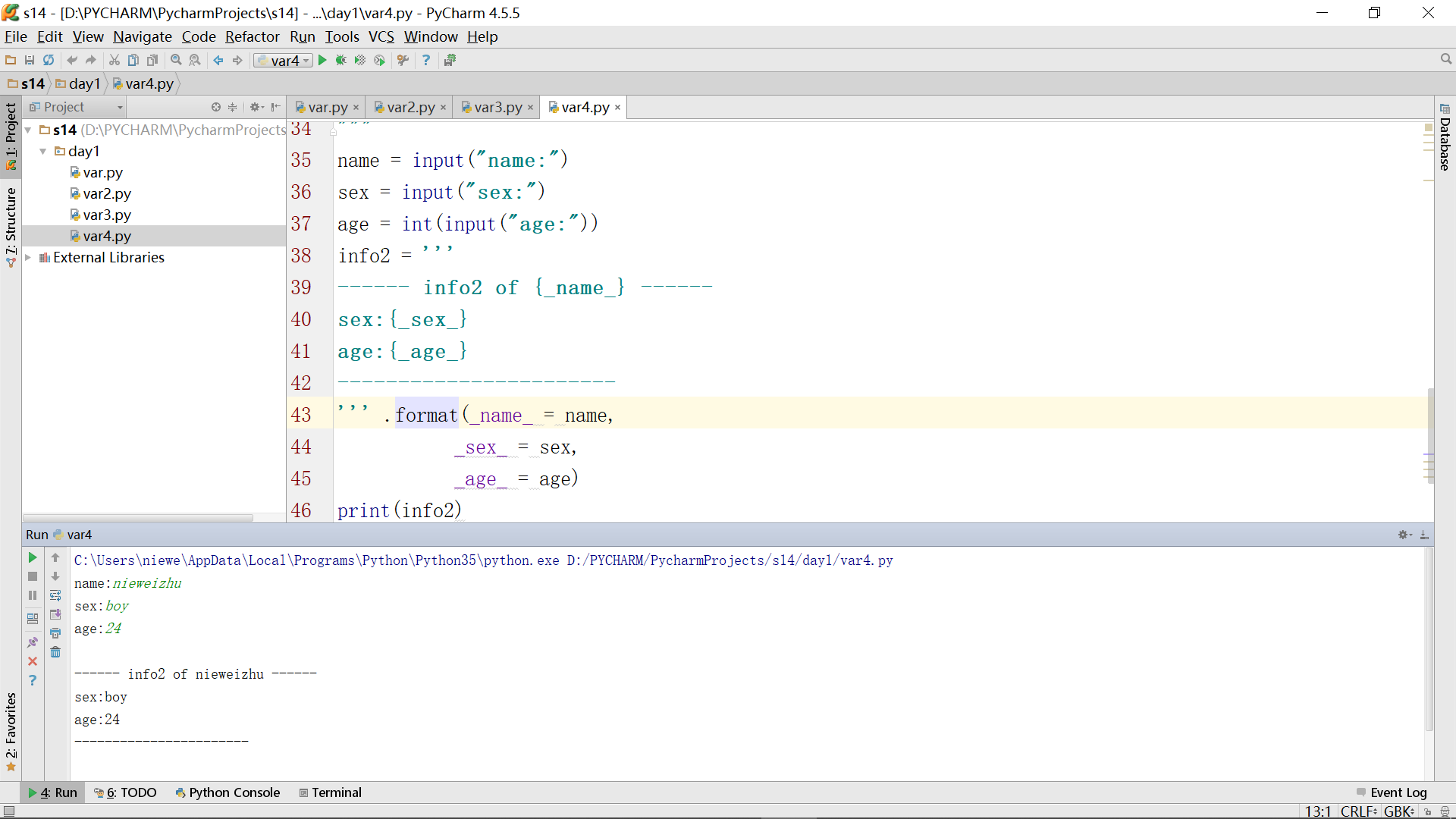
6、字符拼接除了用+、%s(引用),还可以用format如下,这种方式类似结构体和结构体赋值,避免了频繁修改引用的地方(这里应该就是指info里头需要被内容替代的位置):
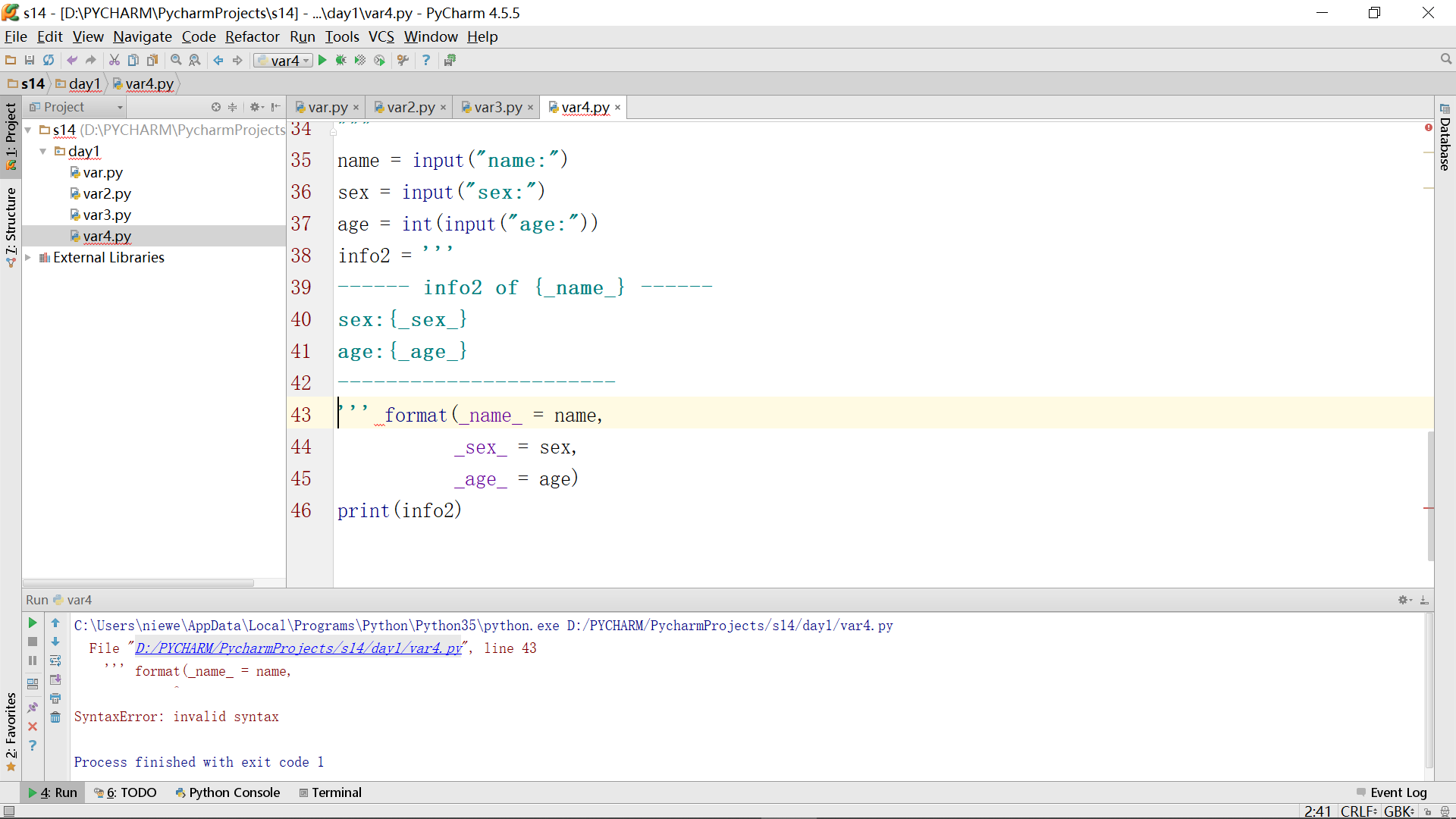
 但是,如果稍不注意,就会出现如下错误,在format前丢掉一点:
但是,如果稍不注意,就会出现如下错误,在format前丢掉一点:
 format还可以用下面这种形式:
format还可以用下面这种形式:
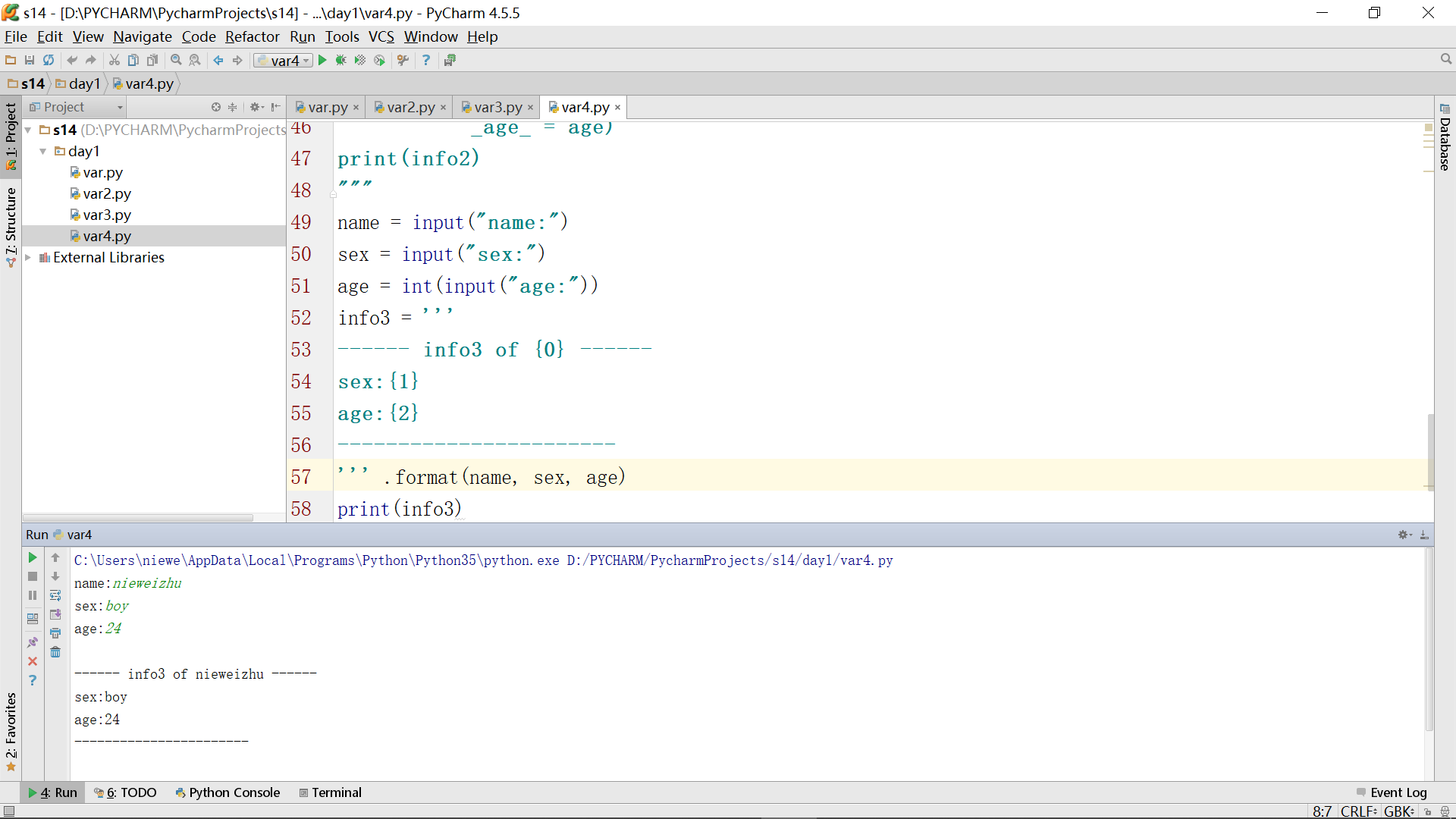 实际上,+方式如果使用了多个,会开辟多块内存空间,相比其它几种方式效率会更低,不提倡使用。
实际上,+方式如果使用了多个,会开辟多块内存空间,相比其它几种方式效率会更低,不提倡使用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号