
使用Kettle的Hive交换简单模型
目录
前言
还是用以前搭建的那个Kettle环境,当然引用的jar包也是以前5.1.0.0-752,这个是公司仓库上的包,已经很老很老了。
用这个包去做hive到hive的交换的话,需要改源码。
我下载的源码还是从这个地址下载的,这次下载的是5.1的源码,源码地址:https://github.com/pentaho/pentaho-kettle
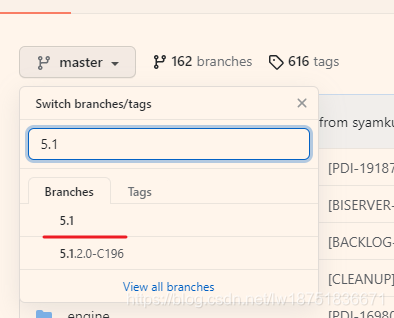
当然这个源码还是需要修改pom文件才能编译正常,这个和下载的8.2的源码修改一样,参考https://blog.csdn.net/lw18751836671/article/details/119600385
这里的话将9.3.0.0-snapshot修改为9.3.0.0-157,搞不懂8.2的源码是8.2.0.0-342的版本,比这之前的源码竟然是9.3.0.0-157这种。
这里只需要将5.1的源码处理kettle-core和kettle-engine两个模块即可。
打包到仓库中变成如下两个jar包,这样就可以在工程中替换以前的5.1.0.0-752这个版本的kettle的jar包。

下面先说一下没有替换以前5.1.0.0-752的jar包产生的事。
一、5.1.0.0-752的jar包运行
引包
这是hive的jdbc连接包,
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>1.2.1</version>
</dependency>编写HIVE2HIVE的Java代码
初始化环境
@Before
public void before() {
try {
// 初始化Kettle环境
KettleEnvironment.init();
EnvUtil.environmentInit();
} catch (KettleException e) {
e.printStackTrace();
}
}编写交换代码
这里每一行的含义已经在之前博客阐述过,不再过多描述。
这里的模型很简单,就是一个表输入到表输出,去掉了以前的字段选择啊,替换等等的步骤,而且连接也使用了XML方式,简单明了。
/**
* hive之间的交换
* @throws KettleException
*/
@Test
public void exchangeHive2Hive() throws KettleException{
//源数据库连接
String hive_src = "<?xml version=\"1.0\" encoding=\"UTF-8\"?>" +
"<connection>" +
"<name>hive_src</name>" +
"<server>192.168.10.212</server>" +
"<type>HIVE2</type>" +
"<access>Native</access>" +
"<database>ntzw_dev_64</database>" +
"<port>10000</port>" +
"<username>hadoop</username>" +
"<password>hadoop</password>" +
"</connection>";
//目标数据库连接
String hive_dest = "<?xml version=\"1.0\" encoding=\"UTF-8\"?>" +
"<connection>" +
"<name>hive_dest</name>" +
"<server>192.168.10.212</server>" +
"<type>HIVE2</type>" +
"<access>Native</access>" +
"<database>ntzw_dev_64</database>" +
"<port>10000</port>" +
"<username>hadoop</username>" +
"<password>hadoop</password>" +
"</connection>";
DatabaseMeta srcDatabaseMeta = new DatabaseMeta(hive_src);
DatabaseMeta destDatabaseMeta = new DatabaseMeta(hive_dest);
//创建转换元信息
TransMeta transMeta = new TransMeta();
transMeta.setName("hive之间的交换");
//设置源和目标
transMeta.addDatabase(srcDatabaseMeta);
transMeta.addDatabase(destDatabaseMeta);
/*
* 创建 表输入->表输出
* 同时将两个步骤连接起来
*/
PluginRegistry registry = PluginRegistry.getInstance();
TableInputMeta tableInputMeta = new TableInputMeta();
String tableInputPluginId = registry.getPluginId(StepPluginType.class,
tableInputMeta);
tableInputMeta.setDatabaseMeta(srcDatabaseMeta);
//设置查询条件
String selectSql = "select id ,name from user_info_src";
tableInputMeta.setSQL(selectSql);
StepMeta tableInputStepMeta = new StepMeta(tableInputPluginId,
"tableInput", (StepMetaInterface) tableInputMeta);
transMeta.addStep(tableInputStepMeta);
TableOutputMeta tableOutputMeta = new TableOutputMeta();
tableOutputMeta.setDatabaseMeta(destDatabaseMeta);
//设置目标表的 schema和表名
tableOutputMeta.setSchemaName(null);
tableOutputMeta.setTablename("user_info_dest");
String tableOutputPluginId = registry.getPluginId(StepPluginType.class, tableOutputMeta);
StepMeta tableOutputStep = new StepMeta(tableOutputPluginId, "tableOutput" , (StepMetaInterface) tableOutputMeta);
//将步骤添加进去
transMeta.addStep(tableOutputStep);
//将步骤和上一步关联起来
transMeta.addTransHop(new TransHopMeta(tableInputStepMeta, tableOutputStep));
Trans trans = new Trans(transMeta);
//执行转换
trans.execute(null);
//等待完成
trans.waitUntilFinished();
if (trans.getErrors() > 0) {
System.out.println("交换出错.");
return;
}
}编写HIVE的连接信息
要知道kettle目前这个jar包是不支持HIVE交换的,我下载的8.1版本也是不支持的,然后在上面连接的XML代码中,有如下一个type节点,定义了HIVE2类型,
<type>HIVE2</type>
这个是kettle-core模块从kettle-database-types.xml中寻找对应的数据库源数据信息的,而这个肯定是没有的。
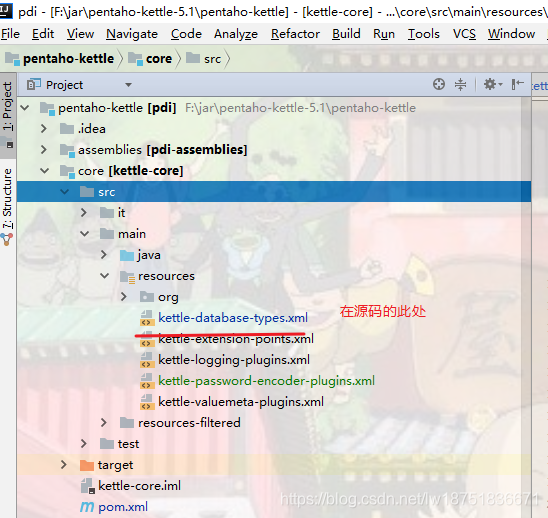
所以我们需要模仿里面的代码写一个Hive的数据源的元数据信息,首先在xml中加入如下配置,
<database-type id="HIVE2">
<description>HIVE2</description>
<classname>org.pentaho.di.core.database.Hive2SQLDatabaseMeta</classname>
</database-type>然后写Hive2SQLDatabaseMeta这个类,代码如下
package org.pentaho.di.core.database;
import org.pentaho.di.core.Const;
import org.pentaho.di.core.row.ValueMetaInterface;
/**
* 注释:kettle的databseType没用HIVE2,需要在kettle-core中的kettle-database-types.xml文件添加对应的hive2的数据库类型,并需要实现此类
*/
/**
* 此方法是参考 PostgreSQLDatabaseMeta.java以及 pentaho-big-data-bundles的pentaho-big-data-kettle-plugins-hive模块中DatabaseMetaWithVersion.java 来写的
*/
public class Hive2SQLDatabaseMeta extends BaseDatabaseMeta {
public Hive2SQLDatabaseMeta() {
}
@Override
public String getExtraOptionSeparator() {
return "&";
}
@Override
public String getExtraOptionIndicator() {
return "?";
}
@Override
public int[] getAccessTypeList() {
return new int[DatabaseMeta.TYPE_ACCESS_NATIVE];
}
@Override
public int getDefaultDatabasePort() {
return this.getAccessType() == 0 ? 10000 : -1;
}
@Override
public String getDriverClass() {
return this.getAccessType() == 1 ? "sun.jdbc.odbc.JdbcOdbcDriver" : "org.apache.hive.jdbc.HiveDriver";
}
@Override
public String getURL(String hostname, String port, String databaseName) {
return this.getAccessType() == 1 ? "jdbc:odbc:" + databaseName : "jdbc:hive2://" + hostname + ":" + port + "/" + databaseName;
}
@Override
public boolean isFetchSizeSupported() {
return true;
}
@Override
public boolean supportsBitmapIndex() {
return false;
}
@Override
public boolean supportsSynonyms() {
return false;
}
@Override
public boolean supportsSequences() {
return true;
}
@Override
public boolean supportsSequenceNoMaxValueOption() {
return true;
}
@Override
public boolean supportsAutoInc() {
return true;
}
@Override
public String getLimitClause(int nrRows) {
return " limit " + nrRows;
}
@Override
public String getSQLQueryFields(String tableName) {
return "SELECT * FROM " + tableName + this.getLimitClause(1);
}
@Override
public String getSQLTableExists(String tablename) {
return this.getSQLQueryFields(tablename);
}
@Override
public String getSQLColumnExists(String columnname, String tablename) {
return this.getSQLQueryColumnFields(columnname, tablename);
}
public String getSQLQueryColumnFields(String columnname, String tableName) {
return "SELECT " + columnname + " FROM " + tableName + this.getLimitClause(1);
}
@Override
public boolean needsToLockAllTables() {
return false;
}
/* @Override
public String getSQLListOfSequences() {
return "SELECT relname AS sequence_name FROM pg_catalog.pg_statio_all_sequences";
}*/
@Override
public String getSQLNextSequenceValue(String sequenceName) {
return "SELECT nextval('" + sequenceName + "')";
}
@Override
public String getSQLCurrentSequenceValue(String sequenceName) {
return "SELECT currval('" + sequenceName + "')";
}
/* @Override
public String getSQLSequenceExists(String sequenceName) {
return "SELECT relname AS sequence_name FROM pg_catalog.pg_statio_all_sequences WHERE relname = '" + sequenceName.toLowerCase() + "'";
}*/
@Override
public String getAddColumnStatement(String tablename, ValueMetaInterface v, String tk, boolean use_autoinc, String pk, boolean semicolon) {
return "ALTER TABLE " + tablename + " ADD " + getFieldDefinition( v, tk, pk, use_autoinc, true, false );
}
@Override
public String getDropColumnStatement(String tablename, ValueMetaInterface v, String tk, boolean use_autoinc, String pk, boolean semicolon) {
return "ALTER TABLE " + tablename + " DROP COLUMN " + v.getName();
}
@Override
public String getModifyColumnStatement(String tablename, ValueMetaInterface v, String tk, boolean use_autoinc, String pk, boolean semicolon) {
return "ALTER TABLE " + tablename + " MODIFY " + getFieldDefinition( v, tk, pk, use_autoinc, true, false );
}
@Override
public String getFieldDefinition(ValueMetaInterface v, String tk, String pk, boolean use_autoinc, boolean add_fieldname, boolean add_cr) {
String retval = "";
String fieldname = v.getName();
int length = v.getLength();
int precision = v.getPrecision();
if ( add_fieldname ) {
retval += fieldname + " ";
}
int type = v.getType();
switch ( type ) {
case ValueMetaInterface.TYPE_BOOLEAN:
retval += "BOOLEAN";
break;
case ValueMetaInterface.TYPE_DATE:
retval += "DATE";
break;
case ValueMetaInterface.TYPE_TIMESTAMP:
retval += "TIMESTAMP";
break;
case ValueMetaInterface.TYPE_STRING:
retval += "STRING";
break;
case ValueMetaInterface.TYPE_NUMBER:
case ValueMetaInterface.TYPE_INTEGER:
case ValueMetaInterface.TYPE_BIGNUMBER:
// Integer values...
if ( precision == 0 ) {
if ( length > 9 ) {
if ( length < 19 ) {
// can hold signed values between -9223372036854775808 and 9223372036854775807
// 18 significant digits
retval += "BIGINT";
} else {
retval += "FLOAT";
}
} else {
retval += "INT";
}
} else {
// Floating point values...
if ( length > 15 ) {
retval += "FLOAT";
} else {
// A double-precision floating-point number is accurate to approximately 15 decimal places.
// http://mysql.mirrors-r-us.net/doc/refman/5.1/en/numeric-type-overview.html
retval += "DOUBLE";
}
}
break;
}
return retval;
}
@Override
public String getSQLListOfProcedures() {
return null;
}
@Override
public String[] getReservedWords() {
return new String[]{"A", "ABORT", "ABS", "ABSOLUTE", "ACCESS", "ACTION", "ADA", "ADD", "ADMIN", "AFTER", "AGGREGATE", "ALIAS", "ALL", "ALLOCATE", "ALSO", "ALTER", "ALWAYS", "ANALYSE", "ANALYZE", "AND", "ANY", "ARE", "ARRAY", "AS", "ASC", "ASENSITIVE", "ASSERTION", "ASSIGNMENT", "ASYMMETRIC", "AT", "ATOMIC", "ATTRIBUTE", "ATTRIBUTES", "AUTHORIZATION", "AVG", "BACKWARD", "BEFORE", "BEGIN", "BERNOULLI", "BETWEEN", "BIGINT", "BINARY", "BIT", "BITVAR", "BIT_LENGTH", "BLOB", "BOOLEAN", "BOTH", "BREADTH", "BY", "C", "CACHE", "CALL", "CALLED", "CARDINALITY", "CASCADE", "CASCADED", "CASE", "CAST", "CATALOG", "CATALOG_NAME", "CEIL", "CEILING", "CHAIN", "CHAR", "CHARACTER", "CHARACTERISTICS", "CHARACTERS", "CHARACTER_LENGTH", "CHARACTER_SET_CATALOG", "CHARACTER_SET_NAME", "CHARACTER_SET_SCHEMA", "CHAR_LENGTH", "CHECK", "CHECKED", "CHECKPOINT", "CLASS", "CLASS_ORIGIN", "CLOB", "CLOSE", "CLUSTER", "COALESCE", "COBOL", "COLLATE", "COLLATION", "COLLATION_CATALOG", "COLLATION_NAME", "COLLATION_SCHEMA", "COLLECT", "COLUMN", "COLUMN_NAME", "COMMAND_FUNCTION", "COMMAND_FUNCTION_CODE", "COMMENT", "COMMIT", "COMMITTED", "COMPLETION", "CONDITION", "CONDITION_NUMBER", "CONNECT", "CONNECTION", "CONNECTION_NAME", "CONSTRAINT", "CONSTRAINTS", "CONSTRAINT_CATALOG", "CONSTRAINT_NAME", "CONSTRAINT_SCHEMA", "CONSTRUCTOR", "CONTAINS", "CONTINUE", "CONVERSION", "CONVERT", "COPY", "CORR", "CORRESPONDING", "COUNT", "COVAR_POP", "COVAR_SAMP", "CREATE", "CREATEDB", "CREATEROLE", "CREATEUSER", "CROSS", "CSV", "CUBE", "CUME_DIST", "CURRENT", "CURRENT_DATE", "CURRENT_DEFAULT_TRANSFORM_GROUP", "CURRENT_PATH", "CURRENT_ROLE", "CURRENT_TIME", "CURRENT_TIMESTAMP", "CURRENT_TRANSFORM_GROUP_FOR_TYPE", "CURRENT_USER", "CURSOR", "CURSOR_NAME", "CYCLE", "DATA", "DATABASE", "DATE", "DATETIME_INTERVAL_CODE", "DATETIME_INTERVAL_PRECISION", "DAY", "DEALLOCATE", "DEC", "DECIMAL", "DECLARE", "DEFAULT", "DEFAULTS", "DEFERRABLE", "DEFERRED", "DEFINED", "DEFINER", "DEGREE", "DELETE", "DELIMITER", "DELIMITERS", "DENSE_RANK", "DEPTH", "DEREF", "DERIVED", "DESC", "DESCRIBE", "DESCRIPTOR", "DESTROY", "DESTRUCTOR", "DETERMINISTIC", "DIAGNOSTICS", "DICTIONARY", "DISABLE", "DISCONNECT", "DISPATCH", "DISTINCT", "DO", "DOMAIN", "DOUBLE", "DROP", "DYNAMIC", "DYNAMIC_FUNCTION", "DYNAMIC_FUNCTION_CODE", "EACH", "ELEMENT", "ELSE", "ENABLE", "ENCODING", "ENCRYPTED", "END", "END-EXEC", "EQUALS", "ESCAPE", "EVERY", "EXCEPT", "EXCEPTION", "EXCLUDE", "EXCLUDING", "EXCLUSIVE", "EXEC", "EXECUTE", "EXISTING", "EXISTS", "EXP", "EXPLAIN", "EXTERNAL", "EXTRACT", "FALSE", "FETCH", "FILTER", "FINAL", "FIRST", "FLOAT", "FLOOR", "FOLLOWING", "FOR", "FORCE", "FOREIGN", "FORTRAN", "FORWARD", "FOUND", "FREE", "FREEZE", "FROM", "FULL", "FUNCTION", "FUSION", "G", "GENERAL", "GENERATED", "GET", "GLOBAL", "GO", "GOTO", "GRANT", "GRANTED", "GREATEST", "GROUP", "GROUPING", "HANDLER", "HAVING", "HEADER", "HIERARCHY", "HOLD", "HOST", "HOUR", "IDENTITY", "IGNORE", "ILIKE", "IMMEDIATE", "IMMUTABLE", "IMPLEMENTATION", "IMPLICIT", "IN", "INCLUDING", "INCREMENT", "INDEX", "INDICATOR", "INFIX", "INHERIT", "INHERITS", "INITIALIZE", "INITIALLY", "INNER", "INOUT", "INPUT", "INSENSITIVE", "INSERT", "INSTANCE", "INSTANTIABLE", "INSTEAD", "INT", "INTEGER", "INTERSECT", "INTERSECTION", "INTERVAL", "INTO", "INVOKER", "IS", "ISNULL", "ISOLATION", "ITERATE", "JOIN", "K", "KEY", "KEY_MEMBER", "KEY_TYPE", "LANCOMPILER", "LANGUAGE", "LARGE", "LAST", "LATERAL", "LEADING", "LEAST", "LEFT", "LENGTH", "LESS", "LEVEL", "LIKE", "LIMIT", "LISTEN", "LN", "LOAD", "LOCAL", "LOCALTIME", "LOCALTIMESTAMP", "LOCATION", "LOCATOR", "LOCK", "LOGIN", "LOWER", "M", "MAP", "MATCH", "MATCHED", "MAX", "MAXVALUE", "MEMBER", "MERGE", "MESSAGE_LENGTH", "MESSAGE_OCTET_LENGTH", "MESSAGE_TEXT", "METHOD", "MIN", "MINUTE", "MINVALUE", "MOD", "MODE", "MODIFIES", "MODIFY", "MODULE", "MONTH", "MORE", "MOVE", "MULTISET", "MUMPS", "NAME", "NAMES", "NATIONAL", "NATURAL", "NCHAR", "NCLOB", "NESTING", "NEW", "NEXT", "NO", "NOCREATEDB", "NOCREATEROLE", "NOCREATEUSER", "NOINHERIT", "NOLOGIN", "NONE", "NORMALIZE", "NORMALIZED", "NOSUPERUSER", "NOT", "NOTHING", "NOTIFY", "NOTNULL", "NOWAIT", "NULL", "NULLABLE", "NULLIF", "NULLS", "NUMBER", "NUMERIC", "OBJECT", "OCTETS", "OCTET_LENGTH", "OF", "OFF", "OFFSET", "OIDS", "OLD", "ON", "ONLY", "OPEN", "OPERATION", "OPERATOR", "OPTION", "OPTIONS", "OR", "ORDER", "ORDERING", "ORDINALITY", "OTHERS", "OUT", "OUTER", "OUTPUT", "OVER", "OVERLAPS", "OVERLAY", "OVERRIDING", "OWNER", "PAD", "PARAMETER", "PARAMETERS", "PARAMETER_MODE", "PARAMETER_NAME", "PARAMETER_ORDINAL_POSITION", "PARAMETER_SPECIFIC_CATALOG", "PARAMETER_SPECIFIC_NAME", "PARAMETER_SPECIFIC_SCHEMA", "PARTIAL", "PARTITION", "PASCAL", "PASSWORD", "PATH", "PERCENTILE_CONT", "PERCENTILE_DISC", "PERCENT_RANK", "PLACING", "PLI", "POSITION", "POSTFIX", "POWER", "PRECEDING", "PRECISION", "PREFIX", "PREORDER", "PREPARE", "PREPARED", "PRESERVE", "PRIMARY", "PRIOR", "PRIVILEGES", "PROCEDURAL", "PROCEDURE", "PUBLIC", "QUOTE", "RANGE", "RANK", "READ", "READS", "REAL", "RECHECK", "RECURSIVE", "REF", "REFERENCES", "REFERENCING", "REGR_AVGX", "REGR_AVGY", "REGR_COUNT", "REGR_INTERCEPT", "REGR_R2", "REGR_SLOPE", "REGR_SXX", "REGR_SXY", "REGR_SYY", "REINDEX", "RELATIVE", "RELEASE", "RENAME", "REPEATABLE", "REPLACE", "RESET", "RESTART", "RESTRICT", "RESULT", "RETURN", "RETURNED_CARDINALITY", "RETURNED_LENGTH", "RETURNED_OCTET_LENGTH", "RETURNED_SQLSTATE", "RETURNS", "REVOKE", "RIGHT", "ROLE", "ROLLBACK", "ROLLUP", "ROUTINE", "ROUTINE_CATALOG", "ROUTINE_NAME", "ROUTINE_SCHEMA", "ROW", "ROWS", "ROW_COUNT", "ROW_NUMBER", "RULE", "SAVEPOINT", "SCALE", "SCHEMA", "SCHEMA_NAME", "SCOPE", "SCOPE_CATALOG", "SCOPE_NAME", "SCOPE_SCHEMA", "SCROLL", "SEARCH", "SECOND", "SECTION", "SECURITY", "SELECT", "SELF", "SENSITIVE", "SEQUENCE", "SERIALIZABLE", "SERVER_NAME", "SESSION", "SESSION_USER", "SET", "SETOF", "SETS", "SHARE", "SHOW", "SIMILAR", "SIMPLE", "SIZE", "SMALLINT", "SOME", "SOURCE", "SPACE", "SPECIFIC", "SPECIFICTYPE", "SPECIFIC_NAME", "SQL", "SQLCODE", "SQLERROR", "SQLEXCEPTION", "SQLSTATE", "SQLWARNING", "SQRT", "STABLE", "START", "STATE", "STATEMENT", "STATIC", "STATISTICS", "STDDEV_POP", "STDDEV_SAMP", "STDIN", "STDOUT", "STORAGE", "STRICT", "STRUCTURE", "STYLE", "SUBCLASS_ORIGIN", "SUBLIST", "SUBMULTISET", "SUBSTRING", "SUM", "SUPERUSER", "SYMMETRIC", "SYSID", "SYSTEM", "SYSTEM_USER", "TABLE", "TABLESAMPLE", "TABLESPACE", "TABLE_NAME", "TEMP", "TEMPLATE", "TEMPORARY", "TERMINATE", "THAN", "THEN", "TIES", "TIME", "TIMESTAMP", "TIMEZONE_HOUR", "TIMEZONE_MINUTE", "TO", "TOAST", "TOP_LEVEL_COUNT", "TRAILING", "TRANSACTION", "TRANSACTIONS_COMMITTED", "TRANSACTIONS_ROLLED_BACK", "TRANSACTION_ACTIVE", "TRANSFORM", "TRANSFORMS", "TRANSLATE", "TRANSLATION", "TREAT", "TRIGGER", "TRIGGER_CATALOG", "TRIGGER_NAME", "TRIGGER_SCHEMA", "TRIM", "TRUE", "TRUNCATE", "TRUSTED", "TYPE", "UESCAPE", "UNBOUNDED", "UNCOMMITTED", "UNDER", "UNENCRYPTED", "UNION", "UNIQUE", "UNKNOWN", "UNLISTEN", "UNNAMED", "UNNEST", "UNTIL", "UPDATE", "UPPER", "USAGE", "USER", "USER_DEFINED_TYPE_CATALOG", "USER_DEFINED_TYPE_CODE", "USER_DEFINED_TYPE_NAME", "USER_DEFINED_TYPE_SCHEMA", "USING", "VACUUM", "VALID", "VALIDATOR", "VALUE", "VALUES", "VARCHAR", "VARIABLE", "VARYING", "VAR_POP", "VAR_SAMP", "VERBOSE", "VIEW", "VOLATILE", "WHEN", "WHENEVER", "WHERE", "WIDTH_BUCKET", "WINDOW", "WITH", "WITHIN", "WITHOUT", "WORK", "WRITE", "YEAR", "ZONE"};
}
@Override
public boolean supportsRepository() {
return true;
}
@Override
public String getSQLLockTables(String[] tableNames) {
String sql = "LOCK TABLE ";
for(int i = 0; i < tableNames.length; ++i) {
if (i > 0) {
sql = sql + ", ";
}
sql = sql + tableNames[i] + " ";
}
sql = sql + "IN ACCESS EXCLUSIVE MODE;" + Const.CR;
return sql;
}
@Override
public String getSQLUnlockTables(String[] tableName) {
return null;
}
@Override
public boolean isDefaultingToUppercase() {
return false;
}
@Override
public String[] getUsedLibraries() {
return new String[]{"hive-jdbc-1.2.1.jar"};
}
@Override
public boolean supportsErrorHandlingOnBatchUpdates() {
return false;
}
@Override
public String quoteSQLString(String string) {
string = string.replaceAll("'", "''");
string = string.replaceAll("\\n", "\\\\n");
string = string.replaceAll("\\r", "\\\\r");
return "E'" + string + "'";
}
@Override
public boolean requiresCastToVariousForIsNull() {
return true;
}
@Override
public boolean supportsGetBlob() {
return false;
}
@Override
public boolean useSafePoints() {
return true;
}
@Override public String getSQLInsertAutoIncUnknownDimensionRow( String schemaTable, String keyField,
String versionField ) {
return "insert into " + schemaTable + "(" + keyField + ", " + versionField + ") values (1, 1)";
}
/**
*TODO 看源码得知,当有特殊字段时,会在insert into对应字段加上特殊字符,
* 会生成如 insert into table12 (uid,name,"username","password") values(?,?,?,?);语句,执行会报错
*
* 重写此方法,将特殊字符去掉,不然会报错
* @return
*/
@Override public String getEndQuote() {
return "";
}
}
备注: 使用的是5.1.0.0-752版本的jar包,由于没有源码,所以将这个变为class文件后,直接360压缩打开jar包,将class放到指定位置,并修改kettle-database-types.xml文件,添加HIVE2的节点。
二、在hive中创建表
新建一个源表(user_info_src)和一个目标表(user_info_dest)
CREATE TABLE user_info_src`(
`id` string,
`name` string);
CREATE TABLE user_info_dest`(
`id` string,
`name` string);三、运行代码
运行Hive到hive的交换,报错如下,这里是连不上hive的数据库,然后看应该是缺少hadoop的配置。
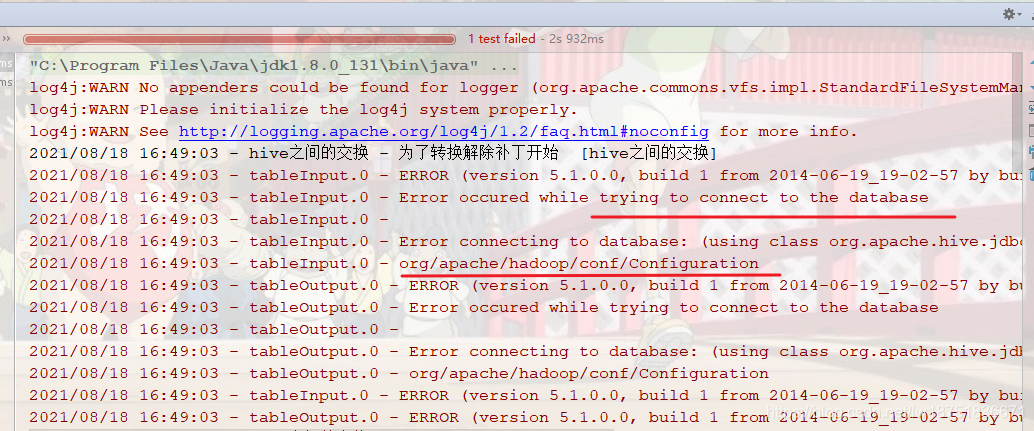
处理方式是引入hadoop的jar包,
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.3</version>
</dependency>继续报错,下面标出了报错的地方,是在getRowInfo方法中,
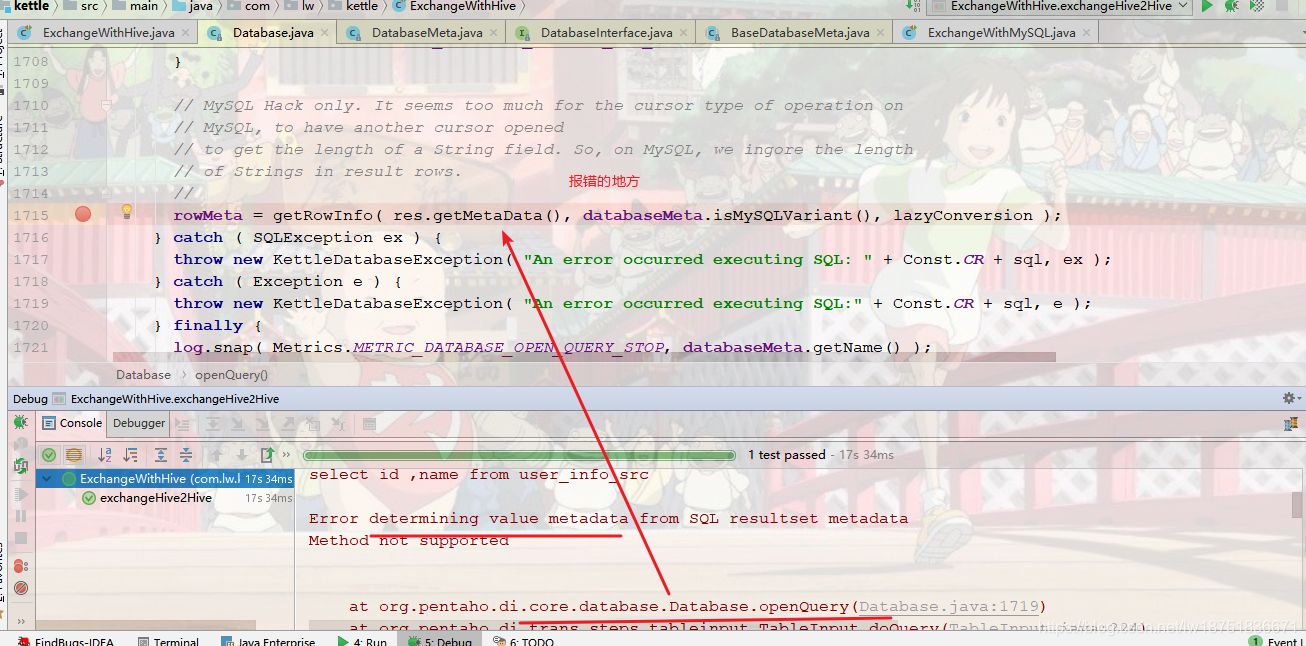
跟踪这个方法是发现如下的isSigned方法报错,
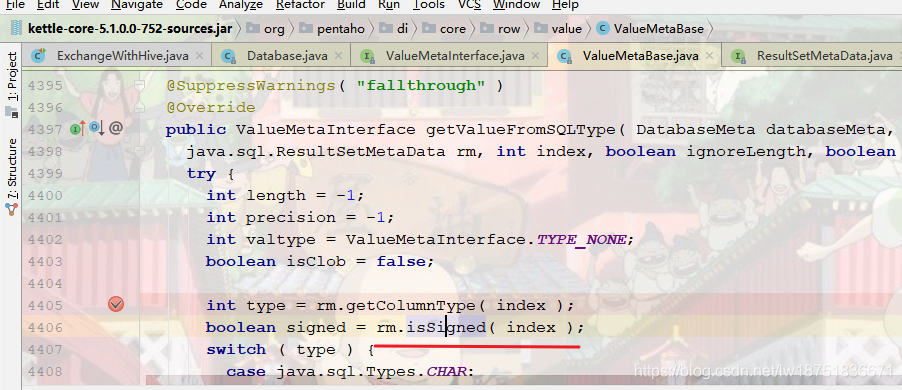
而isSigned方法调用的是hive的jdbc包中的方法,即如下图,
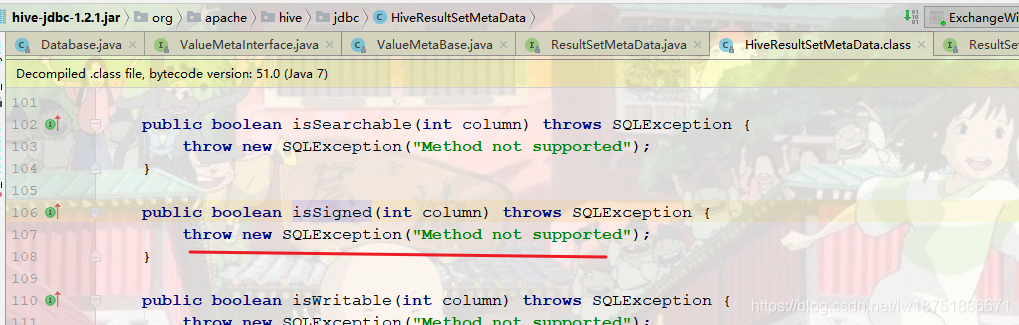
hive并不支持isSigned方法,导致异常抛出,所以此处思考一个点,在调用isSigned的方法处捕获异常是不是能进行下去,然后去看下载的5.1的源码,里面已经处理了。
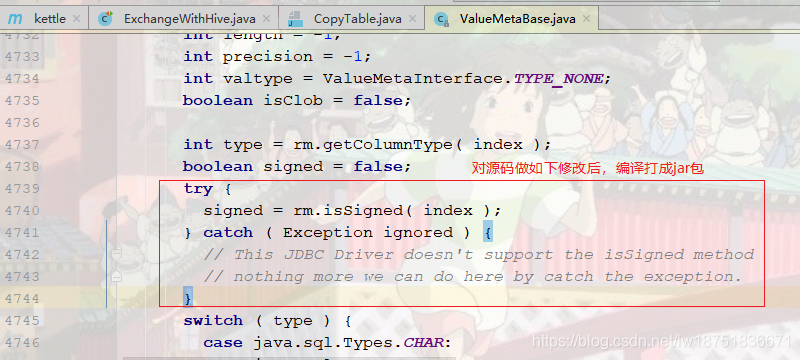
那么此处思考将5.1.0.0-752版本的此处代码捕获异常后,重新编译成class是否可以成功呢?
当然此处我还没试验,我直接将引用的kette包变为了9.3.0.0-157,如下图所示,这是我下载5.1源码打的jar包,

当然这个jar包中有些类变了,比如JsonOutputField这个类,在8.1源码中是在plugins模块下,5.1直接没有了。
换了jar包后继续运行,还是报错,提示jar包中缺少,kettle-password-encoder-plugins.xml文件,然后拷贝了8.1源码中的放过来,
再次运行,哇,不报错了。

但是,我发现源表我没有数据,所以上面是一次空交换,加入数据后交换呢?
继续报错,这里应该是插入的时候报错了,又是method not supported,看样子很可能是hive的jdbc包又不支持什么方法,继续跟踪代码下去,
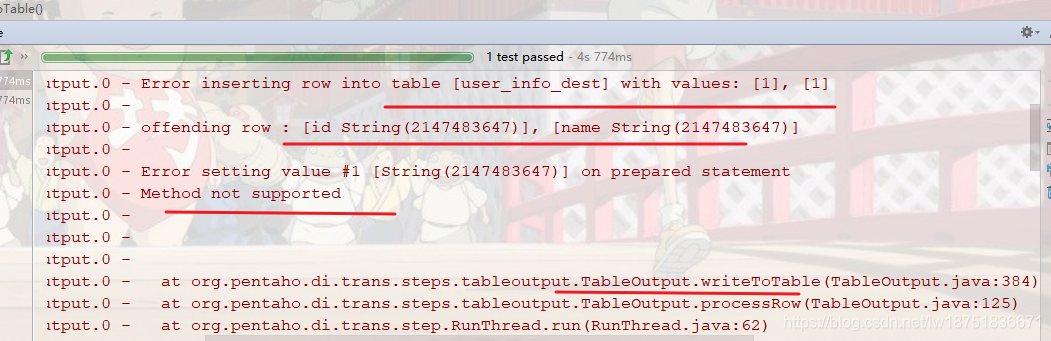
继续跟踪代码,果然是hvie的不支持,此处的红线处是true,然后进入hive的源码,
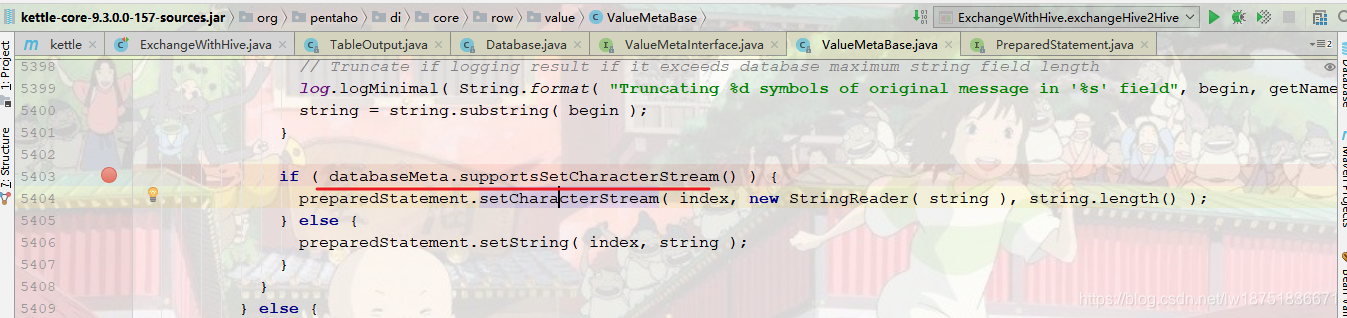

那就让 databaseMeta.supportsSetCharacterStream() 这个代码不为true呗,进入后发现,这个调用的是 Hive2SQLDatabaseMeta,这是我们自己写的,把如下图方法重构下,
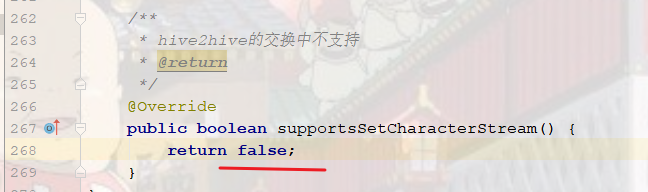
继续运行一次后,交换正常,数据也到目标表了
问题点
1. hive的插入数据很慢,用这种jdbc的insert语句,我观察了一下,我一条语句插入花了1s,我靠,这怎么行,
2. hive有时候select一条数据很慢,时间在5s~30s不等
然后在想,kettle不支持hive这种交换是不是因为此问题,毕竟Hive其实是hadoop的文件系统的jdbc展示,说白了压根就不是和传统数据库那样的存储模式。
后面然后就用直接操作hadoop文件系统的方式来实现交换,这些等后面有空再整理,总的来说,使用写文件,然后加载到hive里面,速度还是很快的。
感想
有人问我,Kettle资料一大堆,为啥还写博客,不重复了么?
别人的博客始终是别人的,自己写的博客是自己经历过的,是自己的思路,而且也是一种回顾,就和观后感一样,一千个人有一千种想法。
后续:
我靠,我是直接clone代码的,然后忘记切换分支了,上述不是5.1的源码,而是master的源码,我了个去,难怪我说jar包版本怎么是9.3,阿西吧
