深度学习之 TensorFlow(四):卷积神经网络
基础概念:
卷积神经网络(CNN):属于人工神经网络的一种,它的权值共享的网络结构显著降低了模型的复杂度,减少了权值的数量。卷积神经网络不像传统的识别算法一样,需要对数据进行特征提取和数据重建,可以直接将图片作为网络的输入,自动提取特征,并且对图形的变形等具有高度不变形。在语音分析和图像识别领域有重要用途。
卷积:卷积是泛函分析中的一种积分变换的数学方法,通过两个函数 f 和 g 生成第三个函数的一种数学算子,表征函数 f 与 g 经过翻转和平移的重叠部分的面积。设函数 





具体解释下:
1.已知两函数f(t)和g(t)。下图第一行两图分别为f(t)和g(t)。
2.首先将两个函数都用 来表示,从而得到f(
来表示,从而得到f(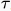 )和g(
)和g(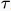 )。将函数g(
)。将函数g(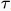 )向右移动t个单位,得到函数g(
)向右移动t个单位,得到函数g(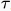 -t)的图像。将g(
-t)的图像。将g(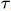 -t)翻转至纵轴另一侧,得到g(-(
-t)翻转至纵轴另一侧,得到g(-(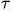 -t))即g(t-
-t))即g(t-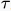 )的图像。下图第二行两图分别为f(
)的图像。下图第二行两图分别为f( )和g(t-
)和g(t-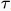 )。
)。
3.由于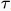 非常数(实际上是时间变量),当时间变量(以下简称“时移”)取不同值时,
非常数(实际上是时间变量),当时间变量(以下简称“时移”)取不同值时,
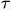 轴“滑动”。下图第三四五行可理解为“滑动”。
轴“滑动”。下图第三四五行可理解为“滑动”。
4.让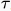 从-∞滑动到+∞。两函数交会时,计算交会范围中两函数乘积的积分值。换句话说,我们是在计算一个滑动的的加权总和(weighted-sum)。也就是使用
从-∞滑动到+∞。两函数交会时,计算交会范围中两函数乘积的积分值。换句话说,我们是在计算一个滑动的的加权总和(weighted-sum)。也就是使用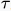 )取加权值。
)取加权值。
最后得到的波形(未包含在此图中)就是f和g的卷积。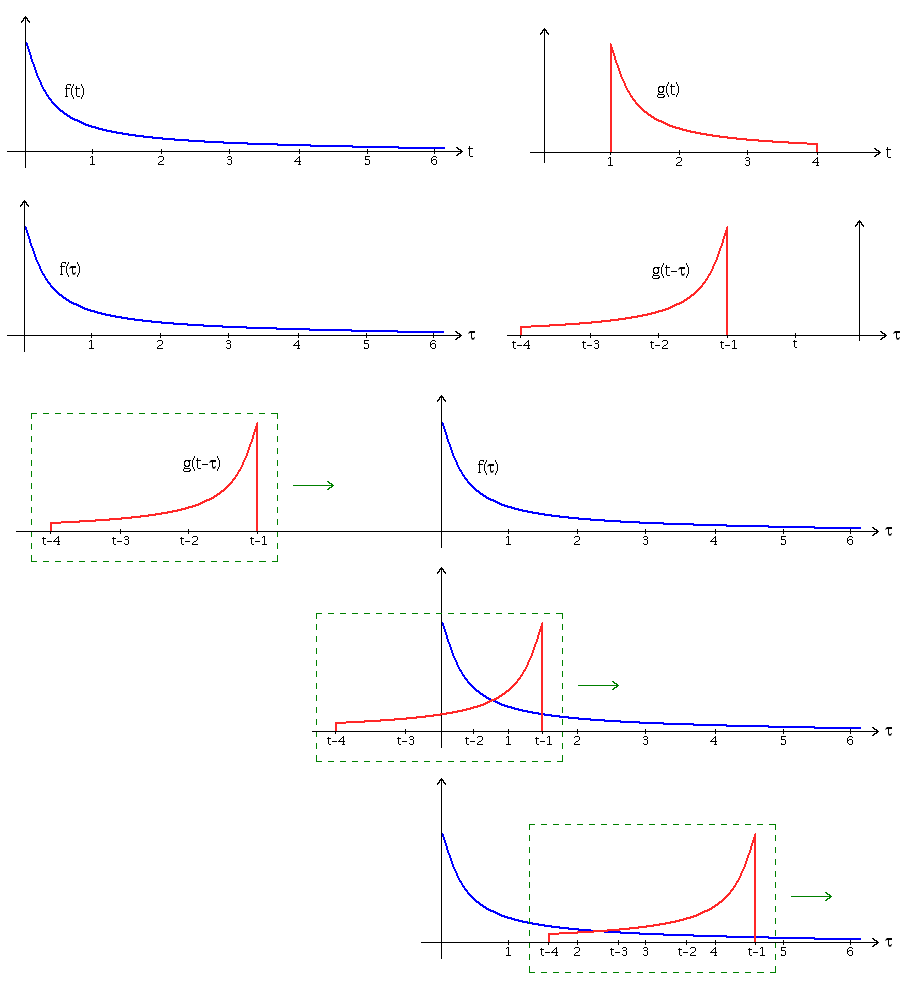
神经网络的基本组成包括输入层、隐藏层、输出层。卷积神经网络的特点在于隐藏层分为卷积层和池化层。卷积层通过一块块的卷积核在原始图像上平移来提取特征,每一个特征就是一个特征映射;而池化层通过汇聚特征后稀疏参数来减少要学习的参数,降低网络的复杂度,池化层最常见的包括最大值池化 (max pooling) 和平均值池化 (average pooling) 。
卷积核在提取特征映射时的动作称为 padding,其有两种方式,即 SAME 和 VALID。由于移动步长(Stride)不一定能整除整张图的像素宽度,我们把不越过边缘取样称为 Vaild Padding,取样的面积小于输入图像的像素宽度;越过边缘取样称为 Same Padding, 取样的面积和输入图像的像素宽度一致。
几种不同的卷积神经网络:
1.LeNet
- 输入层:32 x 32
- 卷积层:3个
- 下采样层:2个
- 全连接层:1个
- 输出层:10个类别(数字0~9的概率)。
(1)输入层。输入图像尺寸为32 x 32。
(2)卷积层:卷积运算的主要目的是使原信号特征增强,并且降低噪音。
(3)下采样层:下采样层主要是想降低网络训练参数及模型的过拟合程度。通常有以下两种方式。
- 最大池化(max pooling):在选中的区域中找最大的值作为采样后的值。
- 平均值池化(mean pooling):把选中区域中的平均值作为采样后的值。
(4)全连接层:计算输入向量和权重向量的点积,再加上一个偏置,随后将其传递给 sigmoid 函数,产生单元 i 的一个状态。
2.AlexNet
AlextNet 由5个卷积层、5个池化层、3个全连接层、大约5000万个可调参数组成。
优点:使用了如下方法
- 防止过拟合:Dropout、数据增强。
- 非线性激活函数:ReLU。
- 大数据训练:120万 ImageNet 图像数据。
- GPU 实现、LRN规范化层的使用。
此外还有 VGGNet、GoogLeNet、ResNet 等卷积神经网络模型,这里不再一一叙述。
***讲下解决过拟合的方法。
(1)数据增强:增加训练数据是避免过拟合的好方法,并且能提升算法的准确性。当训练数据有限的时候,可以通过一些变换从已有的训练数据集中生成一些新数据。来扩大训练数据量。通常采用的变形方法以下几种:
- 水平翻转图像(又称反射变化,filp)。
- 从原始图像随机地平移变换出一些图像。
- 给图像增加一些随机的光照(又称光照、彩色变换、颜色抖动)。
(2)Dropout。以 Alexnet 为例,Alexnet 是以0.5 的概率将每个隐层神经元的输出设置为0 。以这种方式被抑制的神经元既不参加前向传播,也不参与反向传播。因此,每次输入一个样本,就相当于该神经网络尝试了一个新结构,但是所有这些结果之间共享权重。因为神经元不能依赖于其他神经元而存在,所以这种技术降低了神经元复杂的互适应关系。因此,网络需要被迫学习更为健壮的特征,这些特征在结合其他神经元的一些不同随机子集时很有用。Dropout 使收敛所需的迭代次数大致增加了一倍。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号