
大并发服务器开发(实战)
大并发服务器开发(实战)
P1: 大并发服务器架构介绍
任何网路系统都可以抽象为C/S结构。
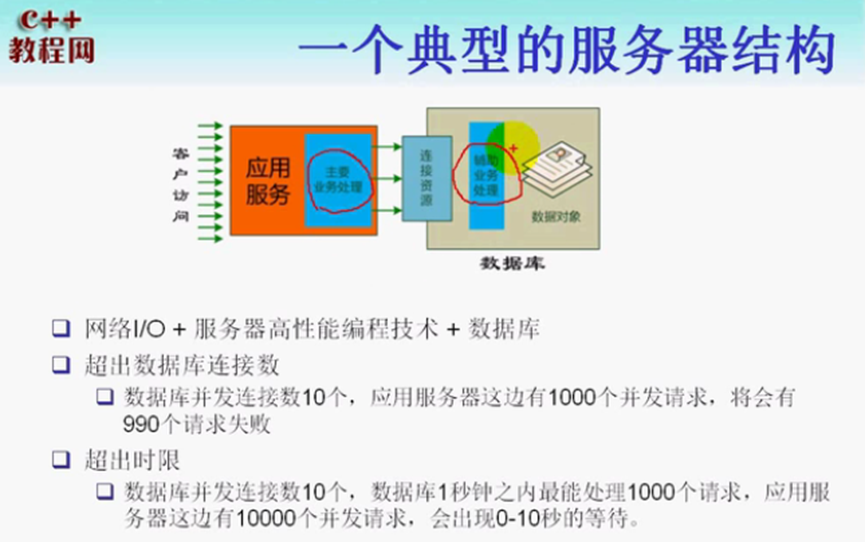
请求超过最大数量限制的时候,需要考虑队列。
DAL:数据访问层,有队列服务 + 连接池
一个典型的服务器结构:
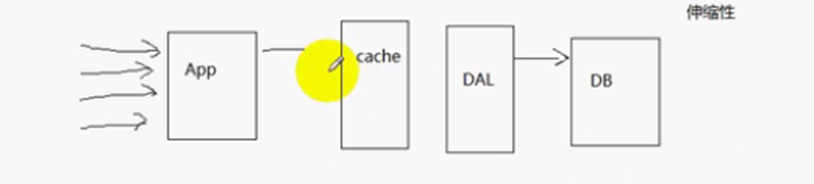
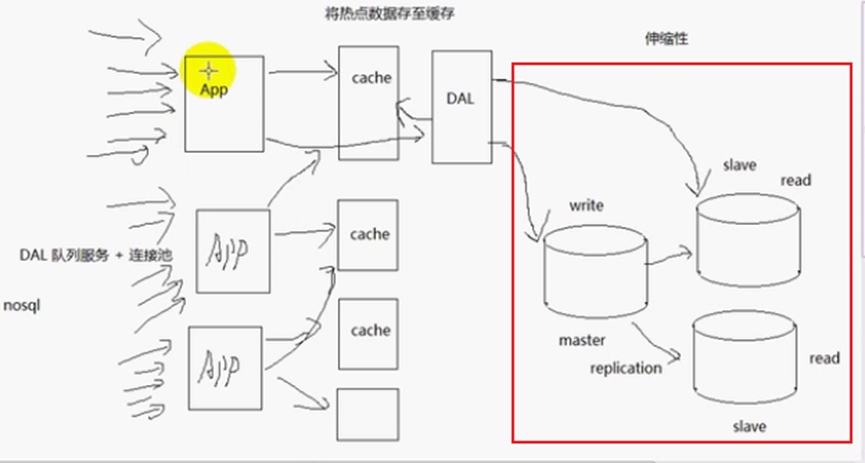
减少数据库的压力的方法:增加队列服务 + 连接池;主要业务处理放在应用服务器处理,数据库只做辅助的业务处理,可以有限减少数据库的压力;增加缓存(cache)有效减少数据库的压力,如果缓存里面有数据,则不去数据库查询,减少了数据库的压力,但是缓存的更新、同步问题。
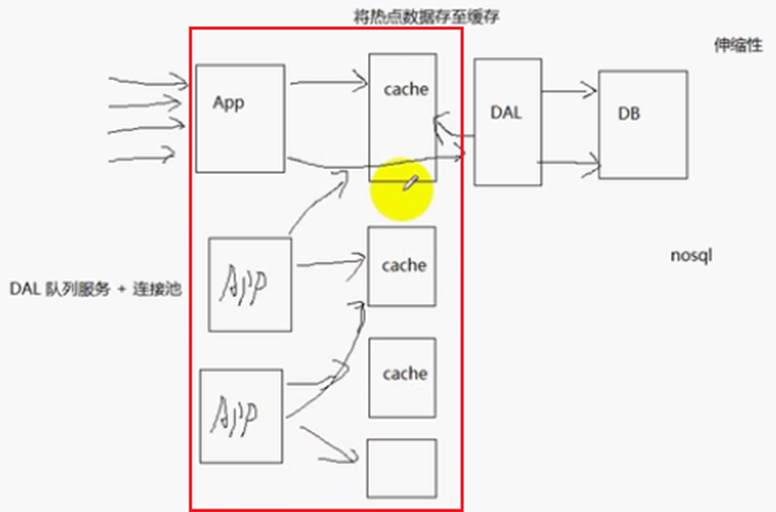
缓存更新(缓存同步)的解决办法:缓存time out (超时),如果缓存失效,就需要重新去数据库查询,然后更新缓存,使得缓存和数据库的信息相同,但是缓存和数据库的信息不同步,实时性差;先将一些热点数据存至缓存,如果要更新数据库的数据,我们直接对数据库的数据进行改写操作(update),然后回到缓存中将相应的信息更新,实时性比较高,也就是一旦数据库中的数据更新了,立即通知前端的缓存更新,实时性比较高,实现起来麻烦一些。
缓存换页的定义:内存不够,将不活跃的数据换出内存。
缓存换页的方法:FIFO,LRU(least recently used)(最近最少使用),LFU(least frequently used)(最不频繁使用),在操作系统里面有介绍这些方法。
nosql(反sql):基于key-value存储非关系的数据。例如分布式的缓存:redis,memcached,都是开源的软件。
如果缓存和APP1部署在一台机器上面,则这个缓存不是全局的缓存,而是局部的缓存,仅仅缓存在APP1上面。假设APP有两台,那么另一台APP2(应用服务器)没办法访问部署在APP1上面的缓存,或者访问比较麻烦;如果缓存是部署在独立的机器上面,而且使用的是分布式缓存机制(有很多机器都有独立的缓存,这些缓存是全局缓存),那么各个APP(应用服务器)都可以访问缓存,减少对服务器的访问,减轻对服务器的负担。如图:
正在对数据库进行写操作,如果此时业务服务器发来多个读请求,那么数据会锁(读写锁)。所以需要进行数据读写分离。
数据库的读操作(查询)比写操作(更新、删除)难得多,需要对数据库进行负载均衡。现在主流的数据库都具有replication机制,这个机制可以使得数据库具有负载均衡。
主从机制:Master主数据库,进行write操作,slave从数据库,进行read操作。当更新、删除操作在主库的时候,信息也要同步到从库。这个同步,就是replication机制,通过一些日志文件进行控制。
任务服务器的负载均衡实现:
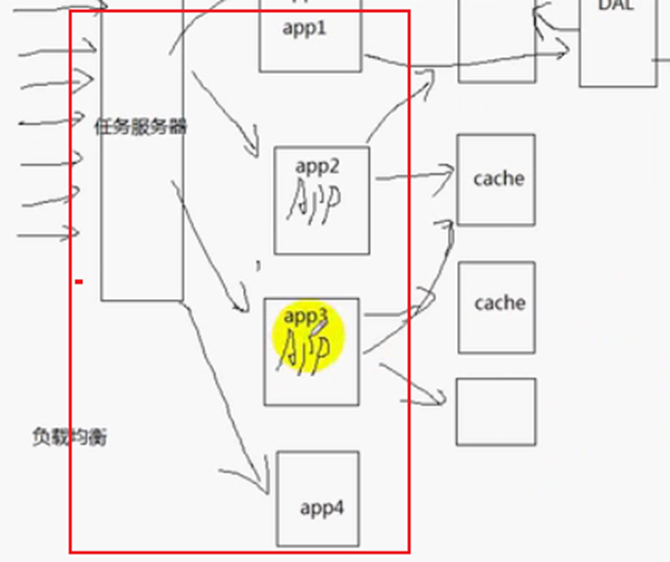
方案1:增加一个任务服务器来实现,任务服务器可以监视应用服务器的负载,CPU高、IO高、并发高、内存换页高。因为任务服务器可以监控业务服务器的状态,那么在实现应用服务器的时候,可以暴露一个http协议的接口,让任务服务器查询到应用服务器的CPU高、IO高、并发高、内存换页高等信息,查询到这些信息之后,选取负载最低的服务器分配任务。会有一些算法来确定哪个服务器的负载最低,方案1中,任务服务器主动把任务分配给应用服务器,应用服务器被动的接受任务。那么能不能应用服务器主动地获取任务呢?能。方案2:应用服务器主动到任务服务器接受任务进行处理。好处是:当应用服务器处于空闲状态的时候,主动去任务服务器取任务,这样是更加科学的。更科学,更公平的原因如图:

但是方案2也有缺点:如果某个应用服务器只能处理某些特定的应用,那么就会增加任务服务器实现的复杂度。如果不同应用服务器处理的任务相同,那么采用方案2,会更加公平一些。
任务服务器有2台或者多台,保证服务器的高可用性,当一个服务器出现故障,可以另一个服务器进行工作。
数据库的优化:除了数据读写分离,还可以数据分区(分库和分表),和水平分区。
数据分区,一般称为垂直分区。分库,指数据库可以按照一定的逻辑,把表分散到不同数据。表,有用户表、业务信表、基础信息表。用户表可以组成用户的数据库,业务表可以组成业务数据库,基础信息表组成基础信息的数据库。
更常用的是水平分区,把数据库水平切割为n个数据库,每个数据库都有用户表、业务表、基础信息表,只是把每个表的记录平均分配给各个数据库。比如,用户表的10条记录,可以平均分配给5个数据库,每个数据库有用户表的2条记录。
服务器性能四大杀手:第一个杀手,数据拷贝(办法:缓存),需要减少数据拷贝,需要有缓存来解决。第二个杀手,环境切换(办法:理性创建线程),该不该用多线程,单线程好,还是多线程好。如果是单核服务器,采用状态机编程的效率是最高的。大量的任务提交到服务器不能并行地处理,如果使用了多线程,会增加线程间的切换开销,类似操作系统的进程切换。如果是多核服务器,多线程能够充分发挥多核服务器的性能,并且线程不是越多越好,会增加线程上下文切换(环境切换)。第三个杀手,内存分配,增加内存池,减少对内存的分配,减少向操作系统分配内存;第四个杀手,锁竞争,减少锁的竞争。
P2:大型网站架构演变过程
Step1:Web动静资源分离
Step2:缓存处理:
Step3:web server集群+读写分离
负载均衡:
Step4:CDN、分布式缓存、分库分表
CDN是内容分发的
垂直分区:
水平分区:
Step5:多数据中心+分布式存储与计算
P3:第三章,poll
I/O复用,select,poll,epoll,其中epoll的效率最高。
Poll使用基本流程:
signal(SIGPIPE, SIG_IGN);
Linux网络编程,第12讲 tcp 11种状态中
如果客户端关闭套接字close,而服务器调用了一次write,服务器会接收一个RST segment(TCP传输层)
如果服务器再次调用了write,这个时候就会产生SIGPIPE信号。
TIME_WAIT状态 对大并发服务器的影响
应尽可能在服务器端避免出现 TIME_WIAT状态
如果服务器端 主动断开连接(先与client调用 close),服务端就会进入TIME_WAIT
协议设计上,应该让客户端主动断开连接,这样就把TIME_WAIT状态分散到大量的客户端。
如果客户端不活跃了,一些客户端不断开连接,这样子就会占用服务器端的连接资源。
服务器端也要有个机制来踢掉不活跃的连 close
Nonblocking socket + I/O复用
&*pollfds.begin();
C++ 11
Pollfds.data();
数据包:一个数据包,两次read。
Read 可能并没有把connfd所对应的接收缓冲区的数据都读完,那么connfd仍然是活跃的。
我们应该将读到的数据保存在connfd的应用层接收缓冲区。
Read发送缓冲区满了的话,那么write调用可能并不能把所有的数据都发送出去,而且还需要弄成非阻塞模式,非阻塞套接字。
write发送的时候,我们也应该有一个应用层发送缓冲区,
POLLOUT事件 触发条件, connfd的发送缓冲区不满(可以容纳数据)。
当内存缓冲区的数据在满了的时候,才关注connfd的POLLOUT事件。
忙等待。
poll模型是电平触发(LT)模式,不支持边沿触发(ET)。
epoll的电平触发模式和poll的电平触发模式相同,但是还多了边沿触发模式。
accept(2)返回EMFILE的处理方法:
1、调高进程文件描述符数目(治标不治本,因为我们是做大并发)
2、死等(效率也比较低)
3、退出程序(是暂时性的,有点小题大做,,不满足系统7*24小时不间断的服务)
4、关闭监听套接字。那什么时候重新打开呢?(这种方法也不太现实)
5、如果是epoll模型,可以改用edge trigger(边沿触发)。
6、准备一个空闲的文件描述符。(推荐)
Cmake
Ubuntu系统:
Sudo apt-get install make
P4:epoll
Epoll三个函数:
Epoll_create()
Epoll_ctl()
Epoll_wait()
EPOLLIN事件
内核中的接收缓冲区 为空 低电平
内核中的接收缓冲区 不为空 高电平
EPOLLOUT事件
内核中的socket发送缓冲区不满 高电平
内核中的socket发送缓冲区满 低电平
LT 电平触发
高电平触发
ET边沿触发
低电平-》高电平 触发
高电平-》低电平 触发
三种I/O复用方式的使用情况:
Poll select:适用于已连接套接字不太大,并且这些套接字非常活跃。
Epoll:适用于一次性遍历返回,活跃的文件描述符。因为epoll内部的实现更复杂,更复杂的代码逻辑,适用于处理大量连接的时候。
参考链接:https://www.bilibili.com/video/BV11b411q7zr?from=search&seid=18026742472358864629&spm_id_from=333.337.0.0

 浙公网安备 33010602011771号
浙公网安备 33010602011771号