
云计算与信息安全第三堂课20210316
BigTable
simhash
hash:当输入有差异的时候,输出的结果有非常大的差异
Google给的是网页的链接,不是网页的具体内容,而且采用了BigTable的格式管理这些链接。
BigTable的理解:


DDos:通过海量的请求,让资源大量被利用,并瘫痪网络从而达到攻击的目的。
BigTable的设计动机
BigTable应达到的基本目标
广泛的适用性
很强的可扩展性
高可用性
简单性
数据模型
关系数据库
两个数据库的表通过外键联系。
通过一个表去查询另一个表,所以查询速度比较慢。
这种结构不适合在线数据库,不适合Google的数据库检索结构。
Google BigTable数据的存储格式
Google一个行关键字可以对应多个列关键字,一个列关键字可以对应多个时间戳。
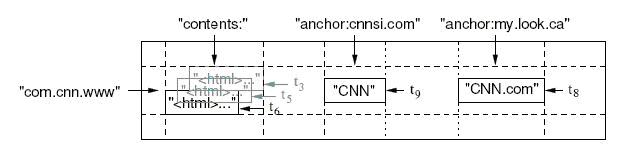
行
使用的字典序排序,字符串大小不能超过64KB
列
将其组织成列族,族名必须有意义,限定词则可以任意选定。
时间戳
保存不同时间的数据、网页、网站等等信息。
分布式数据库读写存在的问题?
正在读的数据不能进行写操作,正在写的数据也不能进行读操作。一句话,就是说,进行一个操作的时候,不能进行其他操作。
BigTable基本架构

Bigtable 依赖于 Chubby 锁服务完成如下功能:
(1) 选取并保证同一时间内只有一个主控服务器;
(2) 存储 Bigtable 系统引导信息;
(3) 用于配合主控服务器发现子表服务器加入和下线;
(4) 获取 Bigtable 表格的 schema 信息及访问控制信息。
Chubby(两地三数据中心五副本):时刻监测主服务器和子表服务器的状态,还有锁服务,可以保证原子性(保证在同一时刻只能有一个操作在进行,比如在读操作就不能进行写操作)
客户端程序库(Client):提供 Bigtable 到应用程序的接口,应用程序通过客户端程序库对表格的数据单元进行增、删、查、改等操作。客户端通过 Chubby 锁服务获取一些控制信息,但所有表格的数据内容都在客户端与子表服务器之间直接传送;
主控服务器(Master):新字表的分配,子表服务器状态监控,子服务器之间的负载均衡。
子表服务器(Tablet Server):所有的SSTable都存储在GFS上,实现子表的装载/卸出、表格内容的读和写,子表的合并和分裂。Table Server 服务的数据包括操作日志以及每个子表上的 Sstable 数据,这些数据存储在底层的 GFS 中。
频繁更新会增加服务器的负担,所以每个子服务器仅仅需要一个日志文件就可以了,
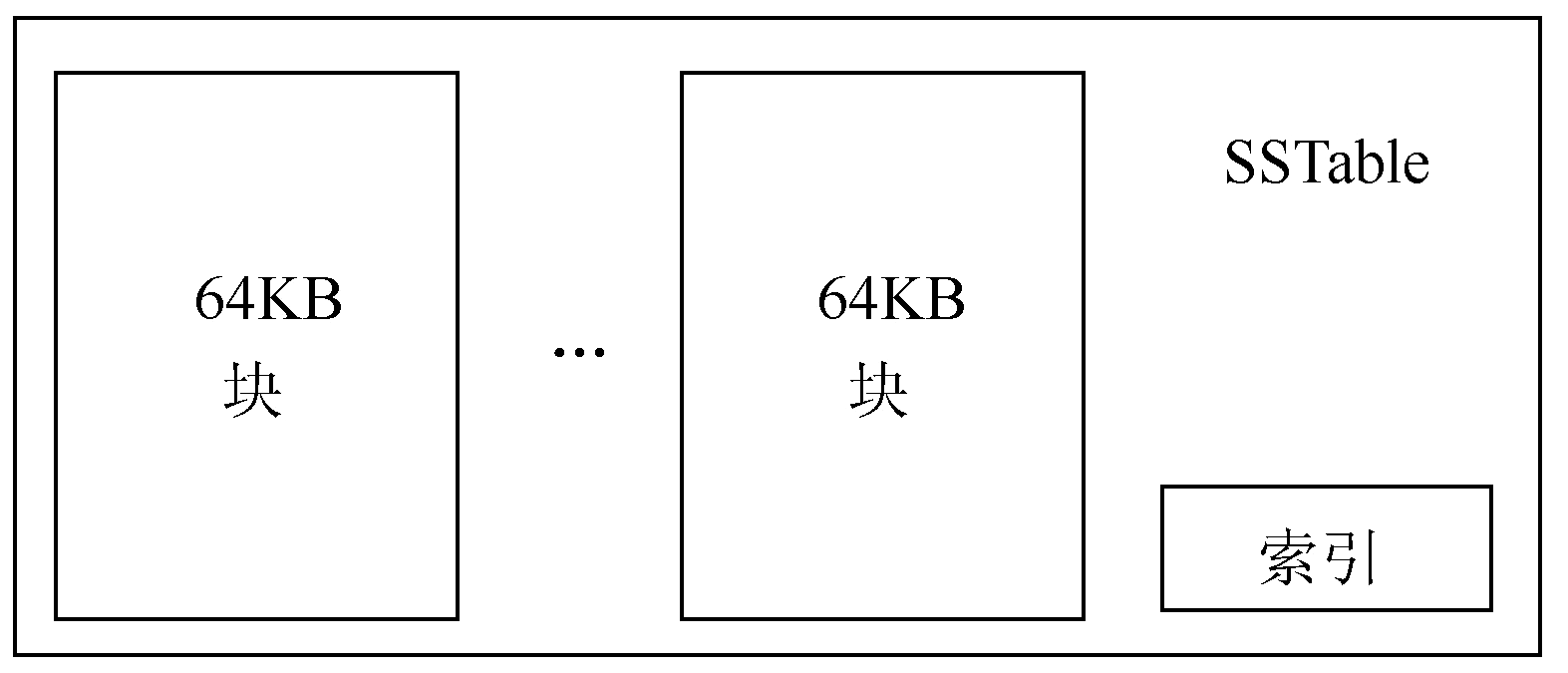
SSTable如下图所示:
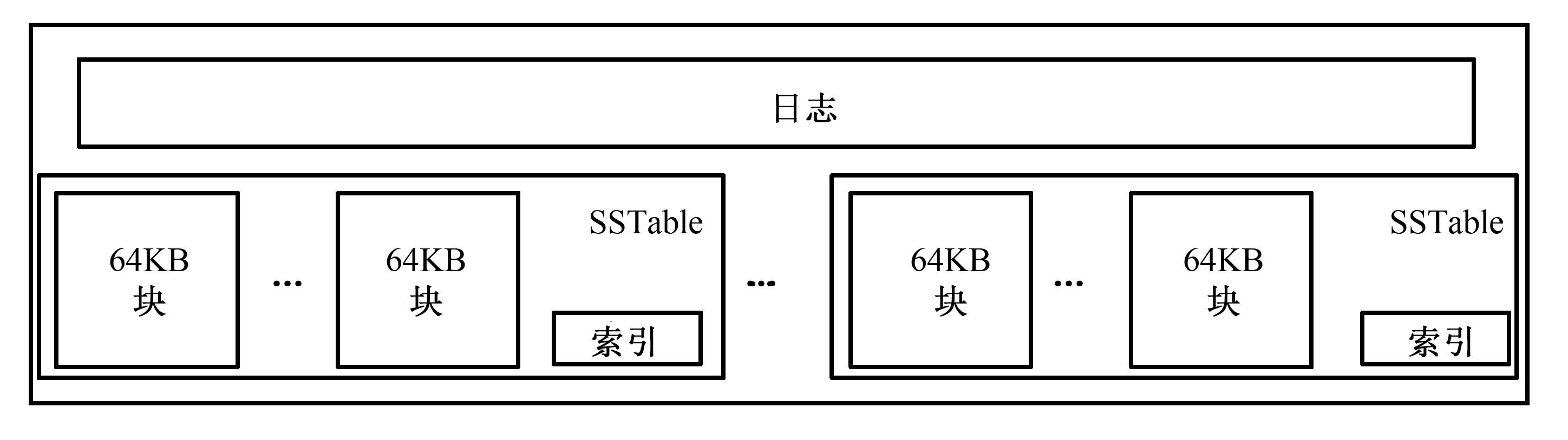
子表实际组成如下图所示:
三种形式压缩之间的关系

性能优化
局部性群组(Locality groups)
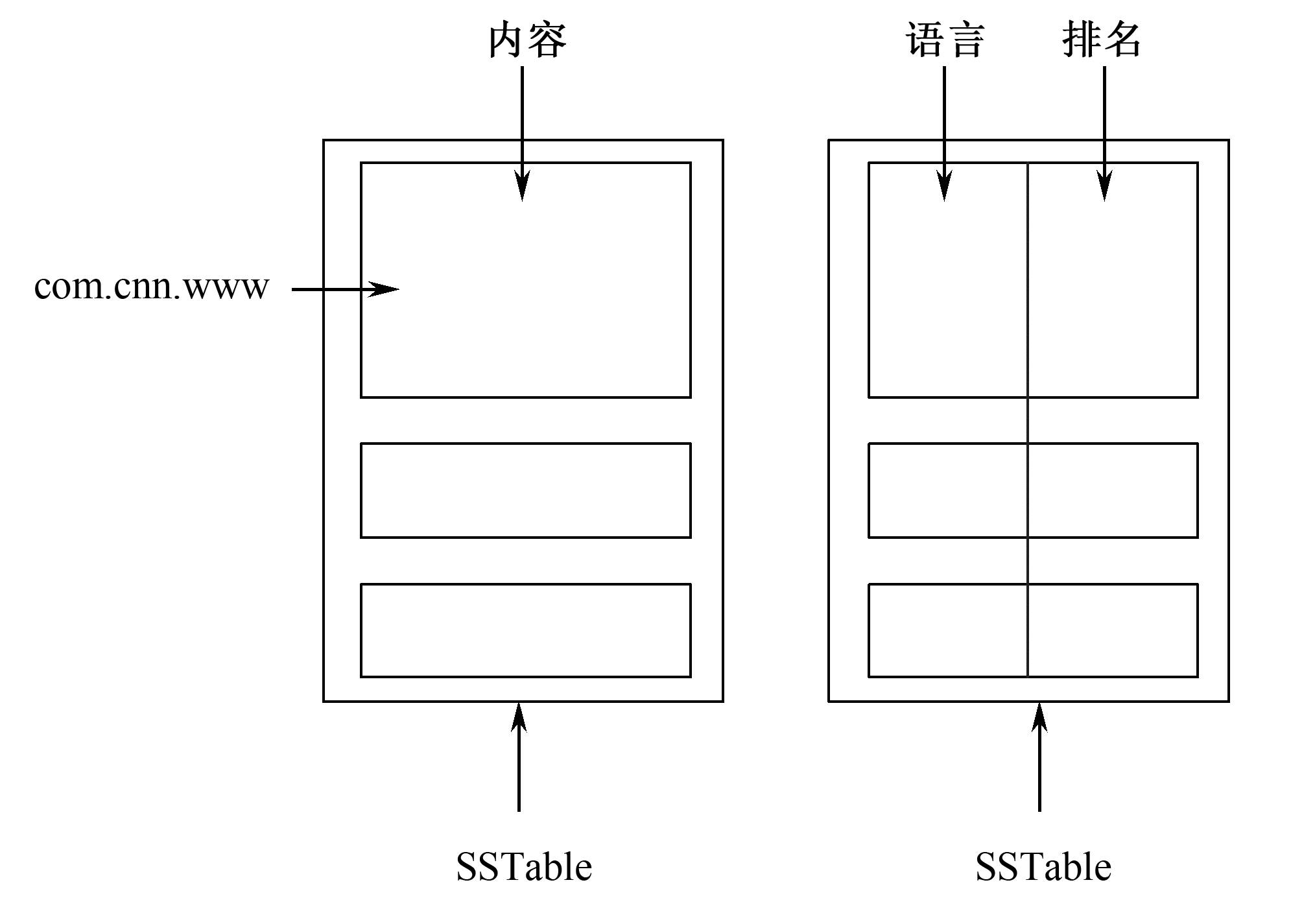
压缩
布隆过滤器(Bloom Filter):在检索里应用很广。
布隆过滤器是巴顿·布隆在1970年提出的,实际上它是一个很长的二进制向量和一系列随机映射函数,在读操作中确定子表的位置时非常有用。布隆过滤器的速度快,省空间。而且它有一个最大的好处是它绝不会将一个存在的子表判定为不存在。不过布隆过滤器也有一个缺点,那就是在某些情况下它会将不存在的子表判断为存在。
Bloom Filter 是一种空间效率很高的随机数据结构,Bloom filter 可以看做是对 bit-map 的扩展, 它的原理是:
当一个元素被加入集合时,通过 K 个 Hash 函数将这个元素映射成一个位阵列(Bit array)中的 K 个点,把它们置为 1。检索时,我们只要看看这些点是不是都是 1 就(大约)知道集合中有没有它了:
如果这些点有任何一个 0,则被检索元素一定不在;如果都是 1,则被检索元素很可能在。
布隆过滤器缺点
但是布隆过滤器的缺点和优点一样明显。误算率是其中之一。随着存入的元素数量增加,误算率随之增加。但是如果元素数量太少,则使用散列表足矣。
参考链接:http://blog.itpub.net/31556438/viewspace-2218075/
https://blog.csdn.net/pinuo/article/details/6712700
https://blog.csdn.net/qq_38289815/article/details/89854719
https://www.sohu.com/a/127177387_610696
https://www.cnblogs.com/wuer888/p/11236164.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号