
Q-learning学习笔记01
在强化学习中,「探索-利用」问题是非常重要的问题。具体来说,根据上面的定义,我们会尽可能地让机器人在每次选择最优的决策,来最大化长期奖励。但是这样做有如下的弊端:
一、在初步的学习中,我们的 Q 值会不准确,如果在这个时候都按照 Q 值来选择,那么会造成错误。
二、学习一段时间后,机器人的路线会相对固定,则机器人无法对环境进行有效的探索。
因此我们需要一种办法,来解决如上的问题,增加机器人的探索。由此我们考虑使用 epsilon-greedy 算法,即在小车选择动作的时候,以一部分的概率随机选择动作,以一部分的概率按照最优的 Q 值选择动作。同时,这个选择随机动作的概率应当随着训练的过程逐步减小。
Q值计算公式:

引入松弛变量 alpha,使得 Q 表的迭代变化更为平缓,计算公式:
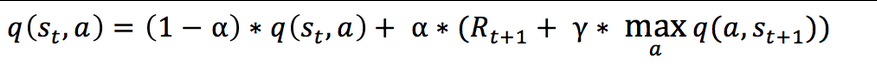
与Q-Learning相比,DQN主要改进在以下三个方面:
(1)DQN利用深度卷积网络(Convolutional Neural Networks,CNN)来逼近值函数;
(2)DQN利用经验回放训练强化学习的学习过程;
(3)DQN独立设置了目标网络来单独处理时序差分中的偏差。
(1)DQN利用深度卷积网络(Convolutional Neural Networks,CNN)来逼近值函数;
(2)DQN利用经验回放训练强化学习的学习过程;
(3)DQN独立设置了目标网络来单独处理时序差分中的偏差。
原文链接:https://blog.csdn.net/gao2175/article/details/83340449
https://www.jianshu.com/p/d8a1693d1fd5
雪儿言

 浙公网安备 33010602011771号
浙公网安备 33010602011771号