
Mysql-Limit 优化
limit 查询导出优化
耗时本质
mysql大数据量使用limit分页,随着页码的增大,查询效率越低下。
当一个表数据有几百万的数据的时候成了问题!
如 select * from table limit 0,10 这个没有问题 当 limit 200000,10 的时候数据读取就很慢
原因本质: 1)limit语句的查询时间与起始记录(offset)的位置成正比 2)mysql的limit语句是很方便,但是对记录很多:百万,千万级别的表并不适合直接使用。
例如: limit10000,20的意思扫描满足条件的10020行,扔掉前面的10000行,返回最后的20行,问题就在这里。 LIMIT 2000000, 30 扫描了200万+ 30行,怪不得慢的都堵死了,甚至会导致磁盘io 100%消耗。 但是: limit 30 这样的语句仅仅扫描30行。
优化手段
干掉或者利用 limit offset,size 中的offset
不是直接使用limit,而是首先获取到offset的id然后直接使用limit size来获取数据
对limit分页问题的性能优化方法
利用表的覆盖索引来加速分页查询
覆盖索引:
就是select 的数据列只用从索引中就能获得,不必读取数据行。mysql 可以利用索引返回select列表中的字段,而不必根据索引再次读取数据文件,换句话说:查询列要被所创建的索引覆盖
因为利用索引查找有优化算法,且数据就在查询索引上面,不用再去找相关的数据地址了,这样节省了很多时间。另外Mysql中也有相关的索引缓存,在并发高的时候利用缓存就效果更好了。在我们的例子中,我们知道id字段是主键,自然就包含了默认的主键索引。
这次我们之间查询最后一页的数据(利用覆盖索引,只包含id列),如下:
#覆盖索引只包含id列 的时间显著优于 select * 不言而喻 select * from order_table where company_id = 1 and mark =0 order by id desc limit 200000 ,20; select id from order_table where company_id = 1 and mark =0 order by id desc limit 200000 ,20;
那么如果我们也要查询所有列,有两种方法,一种是id>=的形式,另一种就是利用join,看下实际情况:
#两者用的都是一个原理嘛,所以效果也差不多 SELECT * FROM xxx WHERE ID > =(select id from xxx limit 1000000, 1) limit 20; SELECT * FROM xxx a JOIN (select id from xxx limit 1000000, 20) b ON a.ID = b.id;
-
test_dev.order_table 300万数据
-
test_begin.order_table 5000万数据
环境差异:两边表结构->索引不一样,会存再同样查询前20万数据 test_begin 比 test_dev 快些
实战1:数据量百万级别
利用或使用 offset
#show profiles 分析性能 #临时开启 SET profiling =1; #查询时候以非缓存方式查询验证:select SQL_NO_CACHE ...... #20-40万:12559073 60-80万:12159073 160-180万:11159073 260-280万:10158757 #含 offset 查询 ->平均耗时:9.958s 左右 select SQL_NO_CACHE * from order_table where company_id = 1 and mark =0 order by id desc limit 200000 ,200000; #分开查询 先查询最大id 在执行 id<=max 的效率性能与合在一起几乎一致 #平均耗时:7.505s 左右 select id from order_table where company_id = 1 and mark =0 order by id desc limit 200000 ,1; #平均耗时:9.092s 左右 select * from order_table where company_id = 1 and mark =0 and id <=12559073 order by id desc limit 200000; #覆盖索引获取max => id<=max -> 平均耗时:17.576s 左右 select SQL_NO_CACHE * from order_table where company_id = 1 and mark =0 and id <= (select id from order_table where company_id = 1 and mark =0 order by id desc limit 200000 ,1) order by id desc limit 200000; #覆盖索引 + join ->平均耗时:11.325s 左右 select SQL_NO_CACHE p.* from order_table p join (select id from order_table where company_id = 1 and mark =0 order by id desc limit 200000 ,200000) a on a.id = p.id;
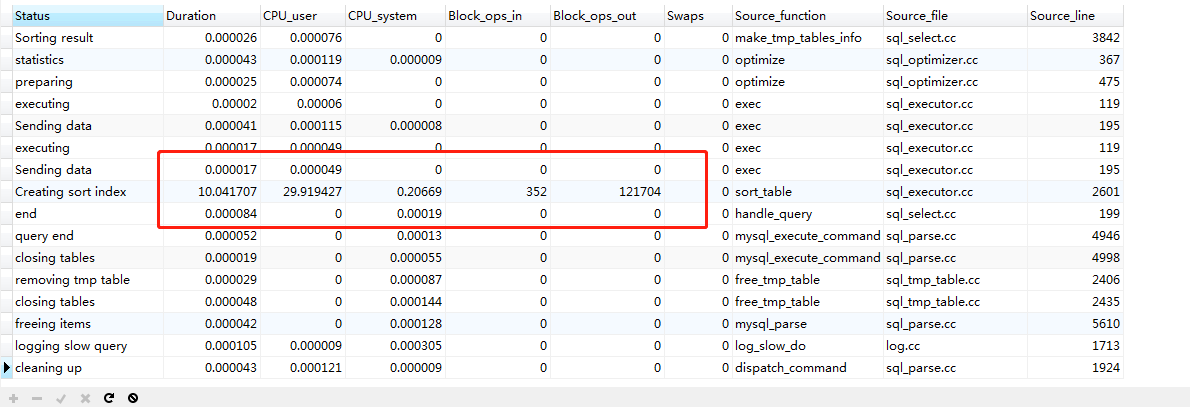
show profile CPU,SWAPS,BLOCK IO,MEMORY,SOURCE for query 520;
方式1.limit offset,size(含子查询)
20-40万
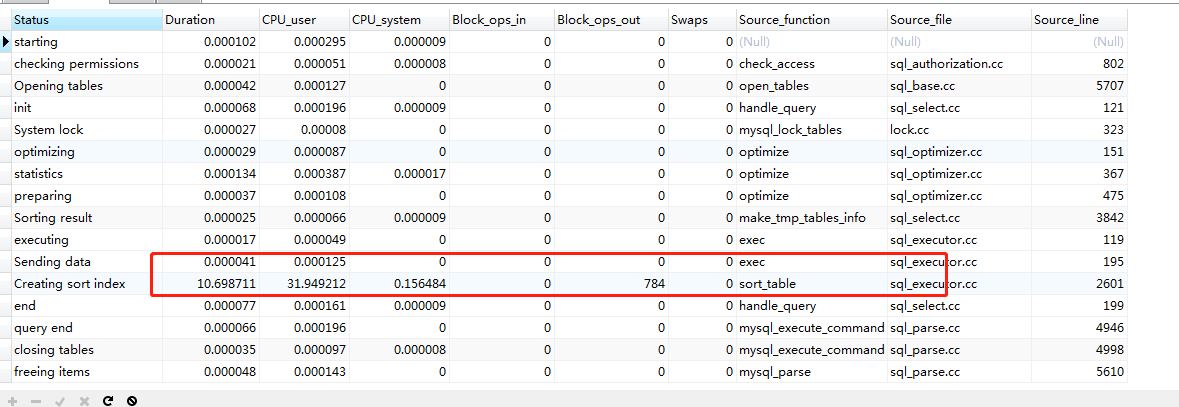
60-80万
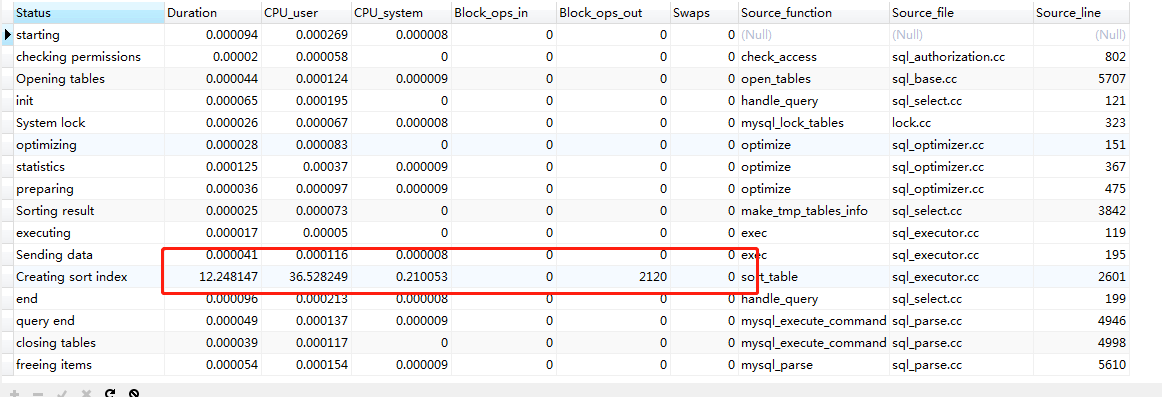
160-180万
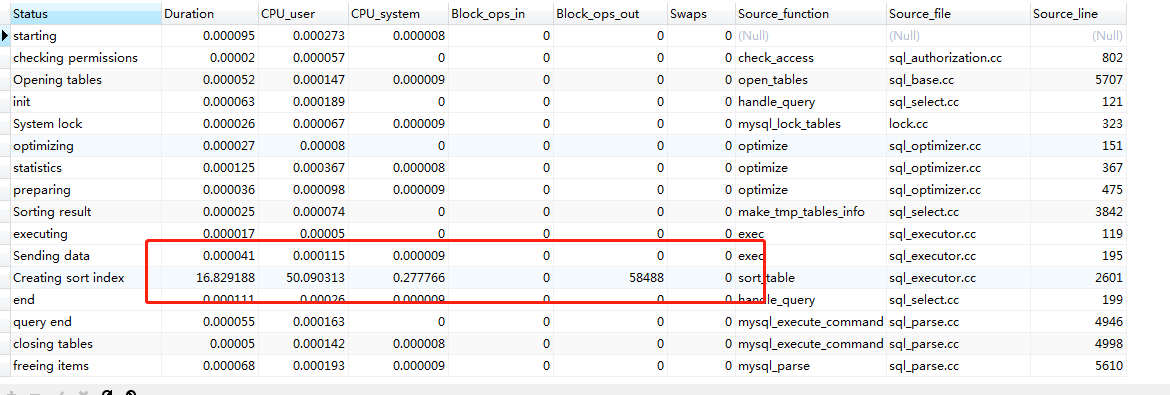
260-280万
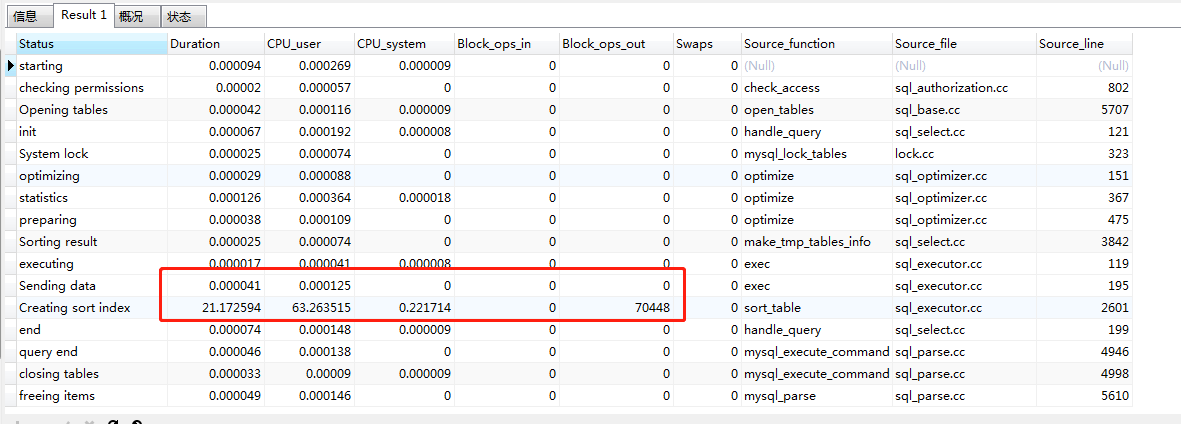
方式2.id < max and limit size
ps: 实战中可以直接将上一页的最小id 传入到下一页查询中当max使用,从而节省子查询的消耗。(后面再千万级别的环境中就已省去子查询)
20-40万
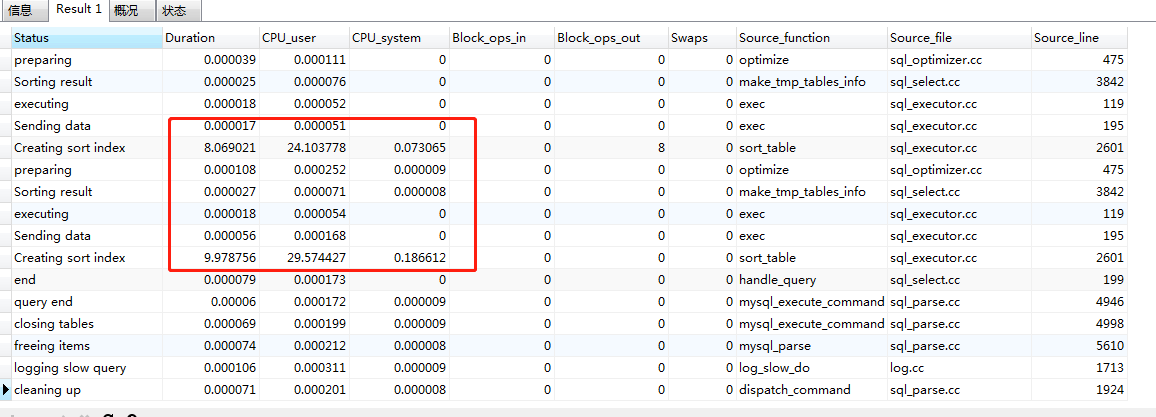
60-80万

160-180万
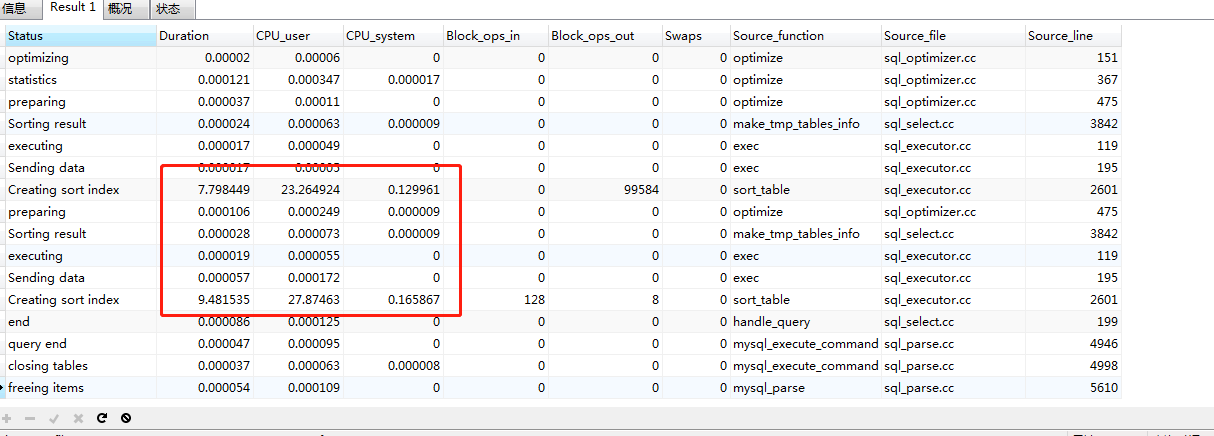
260-280万
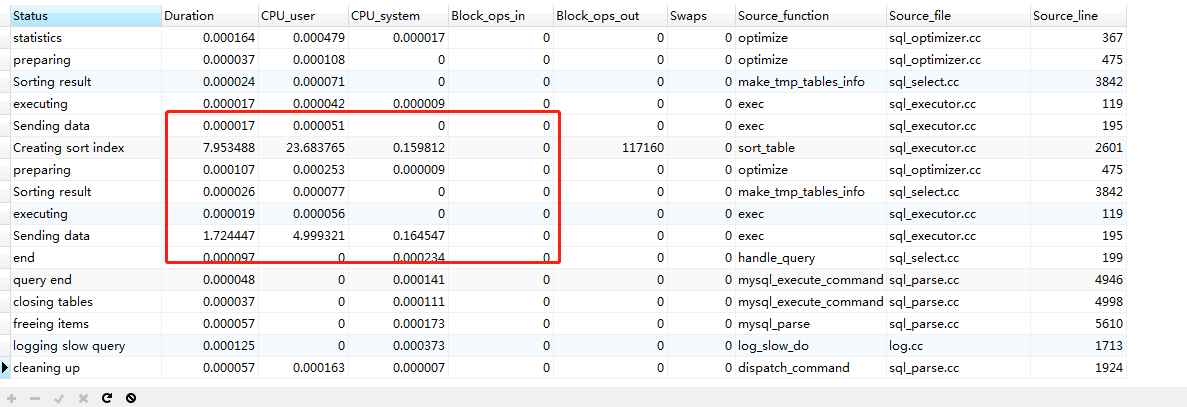
方式3.覆盖索引 + join
20-40万
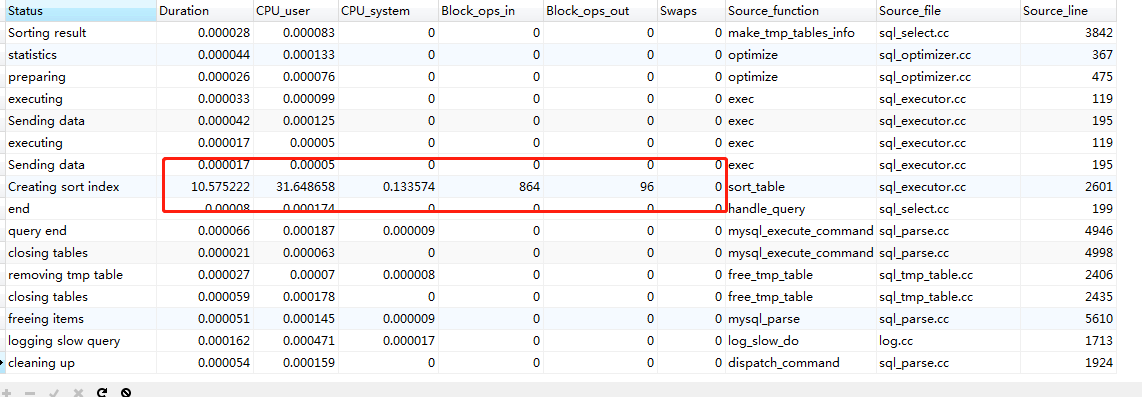
60-80万
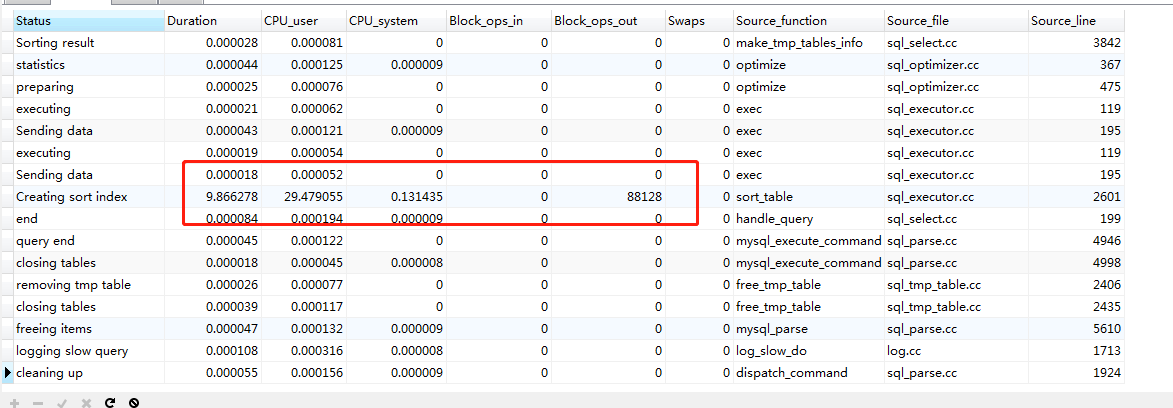
160-180万
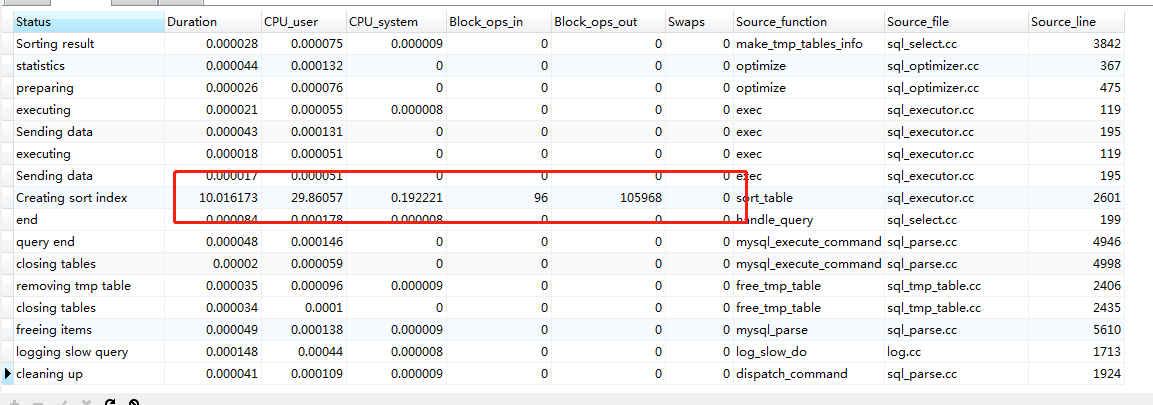
260-280万
结论:
一.查询导出百万以内的数据
方式1->方式2、方式3 。效果不明显:cpu 消耗与io消耗基本一样:稳定在 30左右。优化后性能提升不明显。
三种方式均可以使用,效果差异不大。百万以内的数据没必要优化。
二.查询导出百万以后的数据
方式1:其cpu与io消耗都显著提升(28+->60+ 。offset 越大cpu与io消耗越大)
方式2与方式3:其cpu与io消耗 不明显基本稳定在 30左右。2,3两种方式差异不大
方式1 可优化成:方式2 或 方式3
其中覆盖索引获取起始id :select id from order_table where xxx limit 2600000 ,1; 的耗时会随着offset 的增加而增加。此种方式在查询前200万左右的数据时基本能在10s左右搞定,但是要查询 500万-600万这区间数据时覆盖索引的耗时显著提升。
ps:之前pss 应付单查询优化后就是采用的:覆盖索引 + join 方式。
实战2:数据量千万级别
1.查询导出百万以内的数据 (同上分析,不在重复)
2.查询导出百万甚至千万以后的数据 (利用 offset -> 起始id)
#仅仅查询id #limt 100万,1 耗时 0.671s select id from order_table where company_id = 1 and mark =0 order by id desc limit 1000000 ,1; #limt 200万,1 耗时 600.948s select id from order_table where company_id = 1 and mark =0 order by id desc limit 2000000 ,1; #limit 300万+ 不在考虑 已超过650+s 极力不推荐 select id from order_table where company_id = 1 and mark =0 order by id desc limit 3000000 ,1;
limit 200万,1 的性能分析

结论:
千万级别的数据库的数据查询导出百万甚至以后的数据,上述的三种方式均已不在使用,覆盖索引仅仅查询id就已耗时,耗cpu/IO 极其严重。需要使用后面的两种方式。
3.导出千万以后的数据
不在使用offset(方式3的升级版:省去子查询)
#方式4 仅仅使用 id<max and limit size; #每次查询前获取上一页最小id作为下一页的最大id使用 ##20万-40万:82959503-82620566 60万-80万:82334851 260万-280万:80106996-79887685 660万-680万:76010656-75810657 1660万-1680万:53482458-53240959 3660万-3680万:32532145-32332146 #首页查询 select * from order_table where company_id = 1 and mark =0 order by id desc limit 200000; #非首页查询 #平均耗时:1.539s select * from order_table where company_id = 1 and mark =0 and id <=82543981 order by id desc limit 200000;
#方式5 使用 min<=id<=max #每次查询前获取上一页最小id #首页 select * from order_table where company_id = 1 and mark =0 order by id desc limit 200000; #非首页 # 平均耗时:1.66s select * from order_table where company_id = 1 and mark =0 and id>=82543981 and id <=82878478 order by id desc;
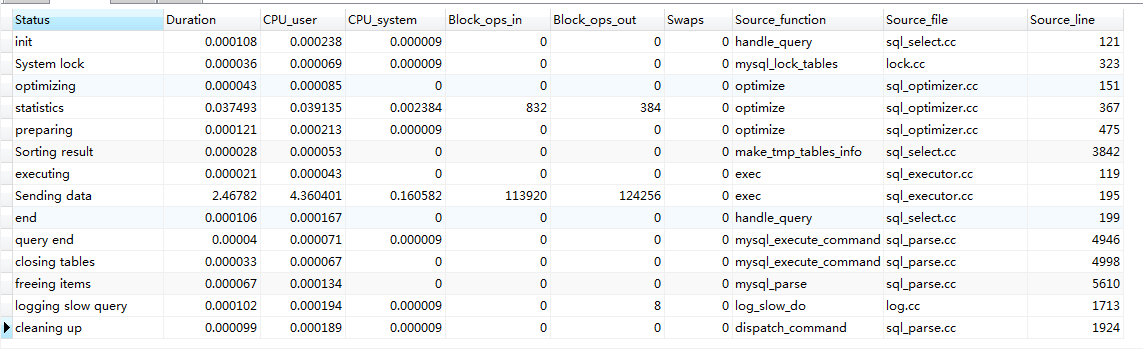
660-680万
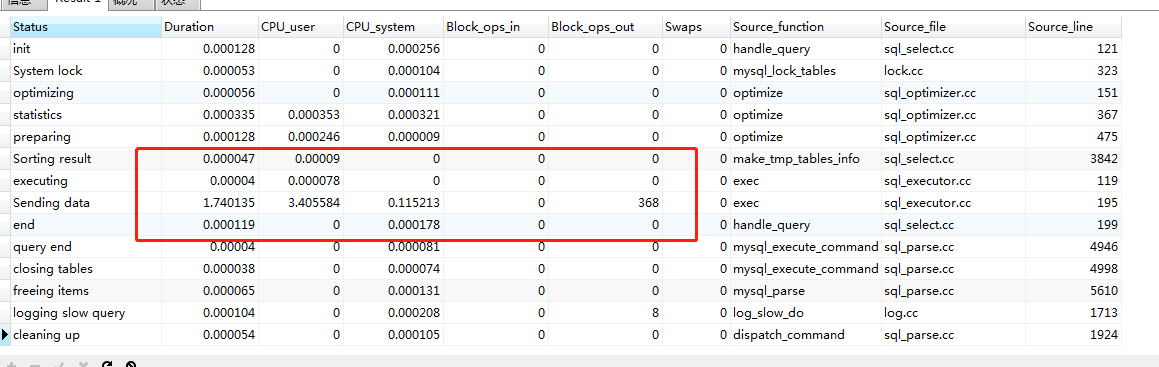
1660-1680万
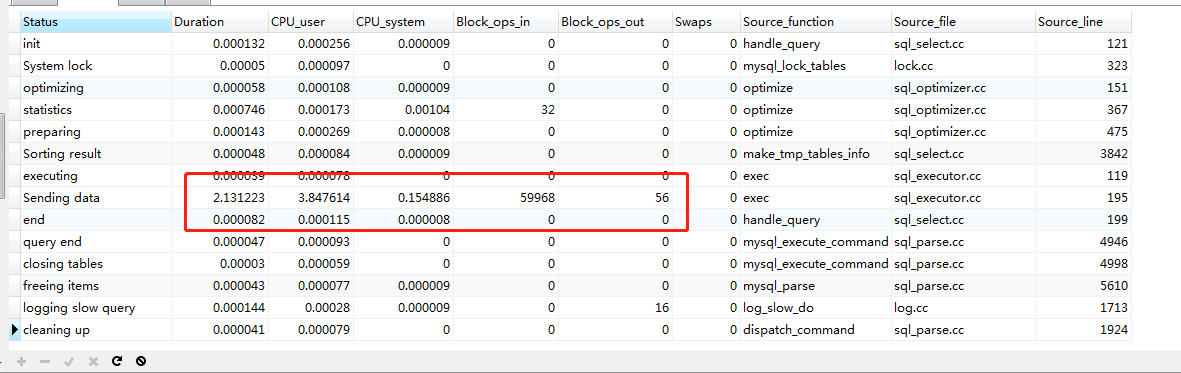
3660-3680万
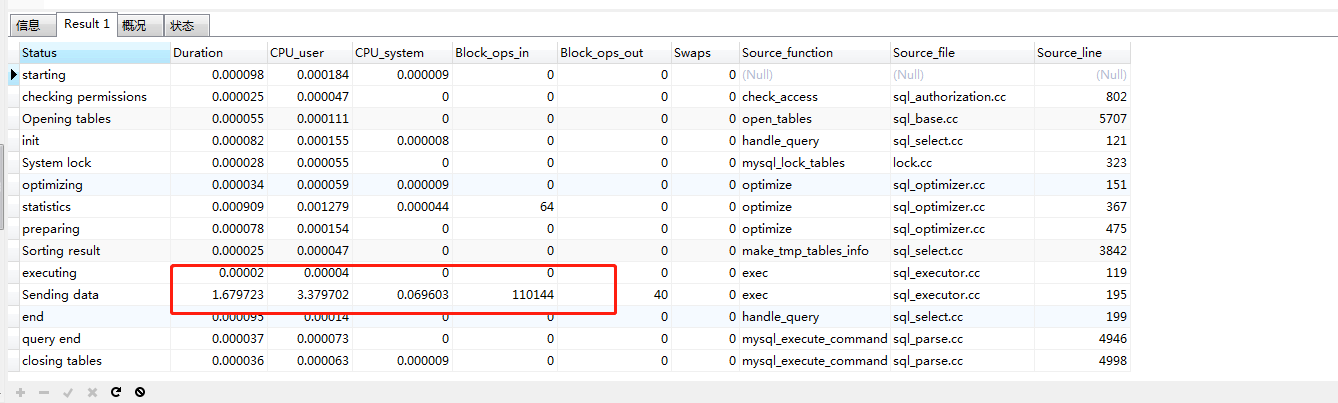
方式5 min<=id<=max
260-280万
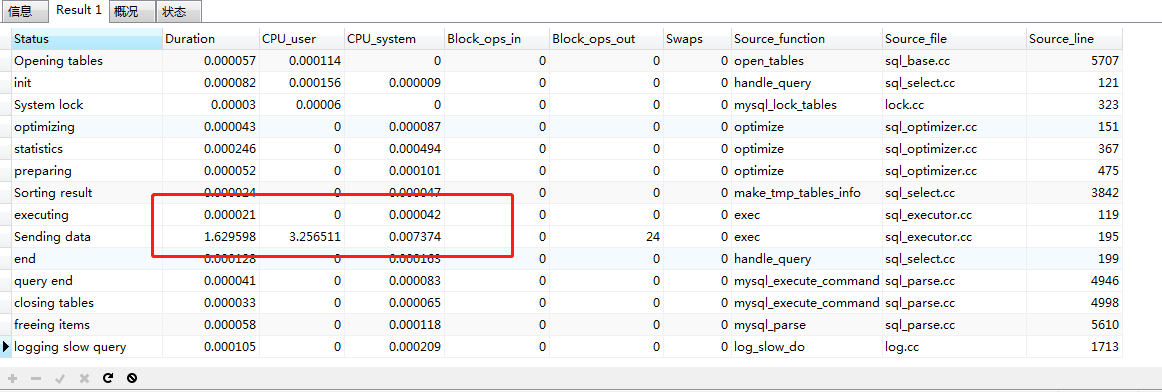
660-680万

1660-1680万
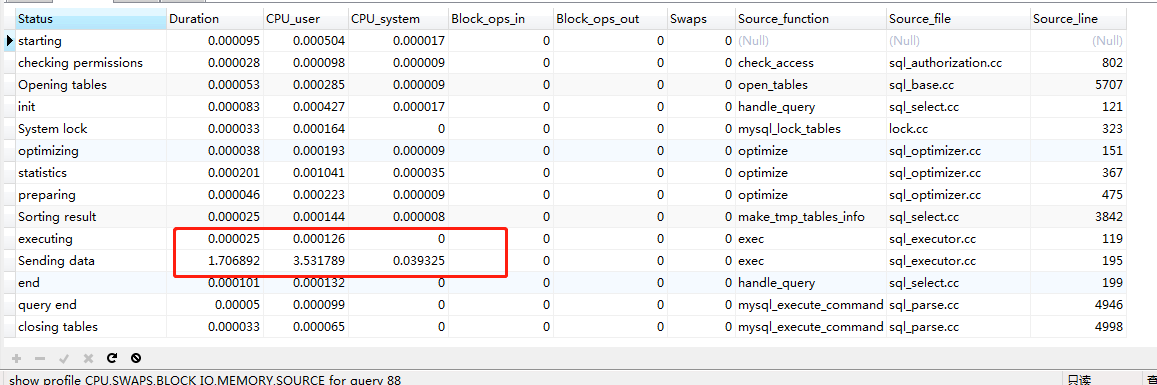
3660-3680万
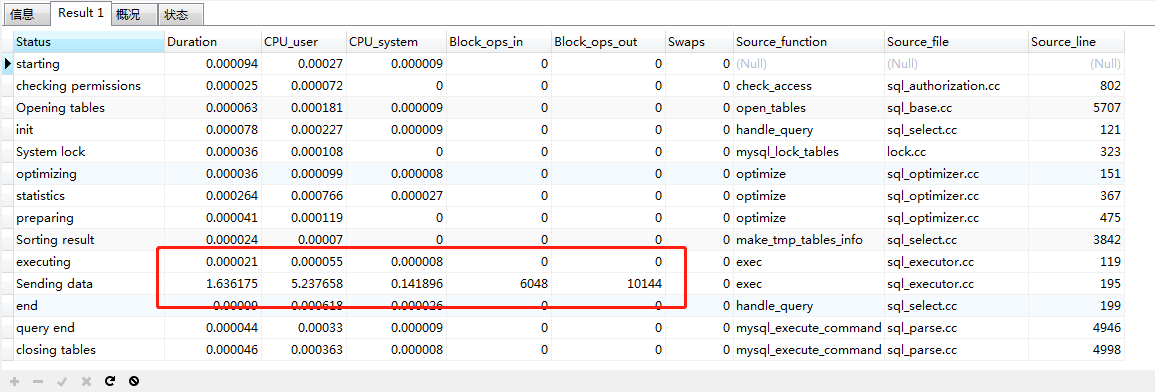
结论:
千万级别的数据库导出
百万以内可以可以使用任意方式。百万甚至千万以后使用方式4或者方式5 无论是sql执行的时间,还是io/cpu的消耗,相对方式1/2/3都有显著的提升。
结论
数据量在百万左右的
查询:可以使用方式2,3优化。导出可以使用方式2,3,4,5优化
数据量在千万以上的
导出可以使用方式4,5优化

