浅析MySQL使用 GROUP BY 分组聚合与细分聚合
原创文章,转载请注明出处:http://www.cnblogs.com/weix-l/p/7521278.html;
若有错误,请评论指出,谢谢!
1. 聚合函数(Aggregate Function)
MySQL(5.7 ) 官方文档中给出的聚合函数列表(图片)如下:
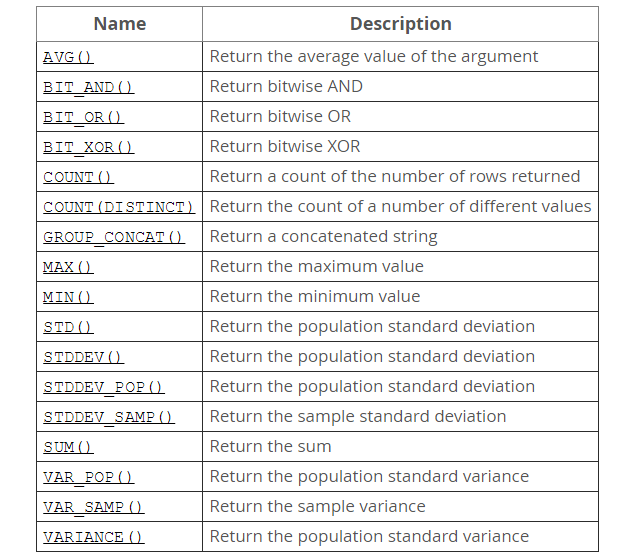
详情点击https://dev.mysql.com/doc/refman/5.7/en/group-by-functions.html 。
除非另有说明,否则聚合函数都会忽略空值(NULL values)。
2. 聚合函数的使用
聚合函数通常对 GROUP BY 语句进行分组后的每个分组起作用,即,如果在查询语句中不使用 GROUP BY 对结果集分组,则聚合函数就对结果集的所有行起作用。为说明聚合函数的使用,现创建测试表 member 进行测试,member 的数据结构如下(使用 SELECT * FROM member 查询所得):
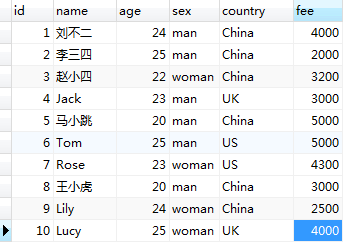
1)对结果集直接使用聚合函数
例如,使用聚合函数SUM () 计算所有会员(member) 的会费总和,则可使用:
SELECT SUM(fee) AS total_fee FROM member #计算所有会员会费总和
查询结果为:
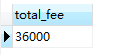
SUM 函数会对全部字段列 fee 进行求和。当然,也可以求平均值、最大值等。
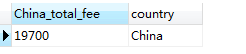
此外,也可以使用 WHERE 语句进行限定条件的聚合查询。例如,如果要查询 country 为 China 的会员会费之和,则为:
SELECT SUM(fee) AS China_total_fee, country FROM member WHERE country = 'China'
结果显示如下:
2)GROUP BY 对结果集分组后使用聚合函数——组内聚合
- GROUP BY 如何分组?
——将字段值相同的记录归为一组,可用COUNT(*) 统计组内成员个数;
- “组内聚合”为何意?
——以分组为单位,对组内每个成员使用聚合函数进行统计,即聚合函数是关于分组成员的函数。
试想,如果要从测试表中查询每个国家的会费总和呢?每个国家的会费,即先将所有结果集按 country 字段进行分组,country 值相同的行归为一组,然后以组为单位进行求和,这样查询的结果记录数等于分组字段不同值的个数。总共有来自三个国家(China, US, UK)的会员,所以分组聚合查询的结果记录数为3:
#查询每个国家的会费之和
SELECT SUM(fee) AS country_group_total_fee, country FROM member GROUP BY country
该查询语句会计算每个国家的会费之和,然后展示按每个国家分组的查询结果:
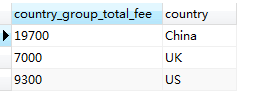
标准SQL( standard SQL) 和 MySQL 都提供 HAVING 语句对使用 GROUP BY 分组之后的结果进行条件筛选并产生新的结果集。例如,对于前述 1)中查询中国会员会费总和的问题,可以使用HAVING 语句:
#使用HAVING语句查询中国会员会费总和
SELECT SUM(fee) AS country_group_total_fee, country FROM member GROUP BY country HAVING country = 'China'
结果和上面一样:
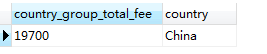
这种方法与前述 1)中直接使用WHERE进行限定相比有些画蛇添足,为什么呢?因为 country 在此是分组字段(group column),对分组字段使用 HAVING 再次进行限定则就显得分组毫无意义,因为这时完全可以通过使用 WHERE 进行筛选后直接求和实现。那么,能使用非聚合列(nonaggregated column) 为限定条件吗?答案是,不仅没有意义,而且不允许。非聚合列指的是没有用聚合函数而是要查询的表本身的字段,因为使用 GROUP BY 分组查询后的聚合结果列中根本就不包含非聚合字段列,所以在解析SQL语句时根本找不到这个字段。比如,当你想获取每个国家性别为 man 的会员的会费之和时可能尝试在上面这个语句中使用 HAVING 对 sex 进行限定,像下面这样:
#错误:尝试使用HAVING 语句对非聚合字段进行限定
SELECT SUM(fee) AS country_group_total_fee FROM member m GROUP BY country HAVING m.sex = 'man'
执行后会报错 Err 1054:
[Err] 1054 - Unknown column 'm.sex' in 'having clause',提示未知的列m.sex,即使此处使用别名进行说明也不行。那么如何实现查询每个国家性别为 man 的会员的会费之和呢?当然还是使用WHERE 语句在 GROUP BY 进行分组之前就进行限定:
#在分组之前使用 WHERE 进行条件筛选
SELECT SUM(fee) AS country_group_total_fee, country FROM member WHERE sex = 'man' GROUP BY country
产生下面结果:
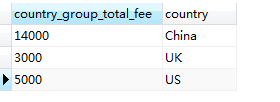
所以,HAVING 不能对分组本身起作用,但可以对分组后的结果进行查询限定,而限定的条件只能为聚合列(aggregated column),聚合列指的是在 SELECT 列 (SELECT list)中使用聚合函数产生的列,例如,此处的SUM(fee) 就是聚合列。在HAVING 中对聚合列进行限定,可以获取满足一定条件的聚合列结果。例如,在上面获取每个国家会员费用之和后再限定查询哪些会员费用之和超过10000,则可以使用下面的SQL 语句:
#查询会员费总和超过10000 的国家
SELECT SUM(fee) country FROM member GROUP BY country HAVING SUM(fee) > 10000
其结果就只剩下中国了:)
这是在标准SQL语句中的语法。在MySQL中扩展了HAVING 的用法,使其可以接受聚合列的别名作为限定条件,例如上面的要求使用别名的查询语句为:
#在HAVING 中使用别名
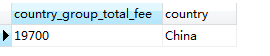
SELECT SUM(fee) AS country_group_total_fee, country FROM member GROUP BY country HAVING country_group_total_fee > 10000
其结果仍为:

3)GROUP BY 按多个分组字段分组后使用聚合函数——细分组内聚合
如果使用一个分组字段分组后的聚合结果记录数等于该分组字段不同值的个数,那么,使用多个分组字段以后呢?例如,在上面的查询的基础上,如果想要查询每个国家男、女分别的会费总和时,可以使用下面的语句:
#查询每个国家男、女会员的总和会费
SELECT SUM(fee) AS sex_and_country_group_total_fee, country, sex FROM member GROUP BY country,sex
结果如下:
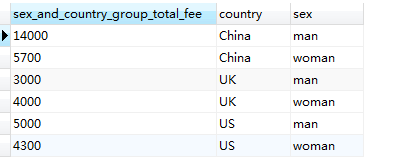
从上面的结果可以看出来,“中国的男性会员出的总会费最多,而英国的男性会员的总会费最少”。总共三个国家,如果只按国家(country) 进行分组,只有三条记录,如果再按性别 (sex) 分,则会在分组后的每个组(也即每一行、每一条记录)里按性别的不同再进行细分,因为性别值只有两种,所以每个国家的分组又被分成两小组,则三个国家总共就有6小组(6 = 3 × 2),这样最终也就会有6条记录,如上图示。
为了解每个细分小组的个数,在SELECT 查询列的最后加上计算分组个数的聚合函数 COUNT(*):
#多分组字段分组,并统计每组个数
SELECT SUM(fee) AS sex_and_country_group_total_fee, country, sex, COUNT(*) AS row_num FROM member GROUP BY country, sex
结果如下:
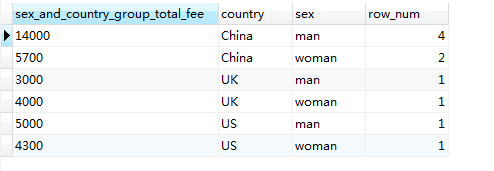
上面的结果默认按靠近GROUP BY 的顺序进行排序,但如果要指定排序一句,则可使用ORDER BY ,例如,对上面的结果按 sex 排序:
#将分组结果按sex 排序
SELECT SUM(fee) AS sex_and_country_group_total_fee, country, sex, count(*) AS row_num FROM member GROUP BY country, sex ORDER BY sex
结果如下:
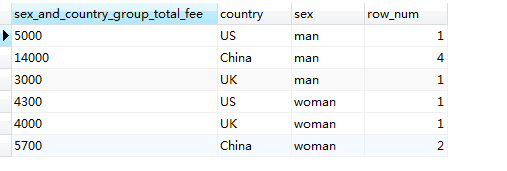
如果用其他字段对结果再进行细分呢?原理与上述两个字段进行分组时一样的,只是分组的深度越多,很明显结果的记录行数也越多,但不管怎样,你会发现每一条分组后的结果都是不一样的,这正是分组结果的特征,因为ORDER BY 本身就具有聚合功能,每个聚合列的结果是通过分组归类的结果,所以只有一条记录。
那么,如果用表的 主键 或 非空唯一性字段 进行分组,结果会怎样呢?比如,在本测试表中,id 是其主键,name 是非空的具有唯一性约束的字段,下面分别是以 id 和 name 进行分组的MySQL 语句和结果:
#以主键id进行分组
SELECT SUM(fee) AS sex_and_country_group_total_fee, id, COUNT(*) AS row_num FROM member GROUP BY id
结果如下:
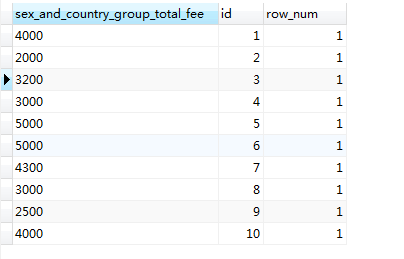
#以非空唯一性约束字段进行分组
SELECT SUM(fee) AS sex_and_country_group_total_fee, name, COUNT(*) AS row_num FROM member GROUP BY name
结果如下:
很显然,这两种分组的结果中聚合函数结果列是一样的,每组的结果记录行数也一样,而且都为1,这说明按主键或非空唯一性约束字段进行分组其结果相同,且结果就是表的全部每一行记录。这样做可能没有太大意义,但有助于理解 GROUP BY 分组的原理。
3. 总结
1) 可直接对某个字段使用聚合函数,也可用 WHERE 语句筛选后对某个字段使用聚合函数;
2) 聚合函数通常作用于使用 GROUP BY 分组后的分组成员,用于统计每个分组的数据;
3) 不能对没有使用 GROUP BY 分组的聚合函数使用 HAVING 进行限定;
4) 可对使用 GROUP BY 分组查询后的结果使用 HAVING 进行限定,其限定条件最好为聚合函数列(本身或其他聚合函数);
5) 可在使用 GROUP BY 分组前使用 WHERE 对结果进行筛选,在分组后使用 HAVING 对聚合函数列进行限定;
6) 可使用 ORDER BY 对结果按照某个字段(任意字段或列,使用 GROUP BY 分组时也可使用聚合函数列)进行排序;
7) 当按照主键或非空唯一性约束字段进行分组时,其结果为整个表的全部记录。
4. 参考文献
[1]. MySQL 官方文档 URL: https://dev.mysql.com/doc/refman/5.7/en/group-by-functions.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号