机器学习
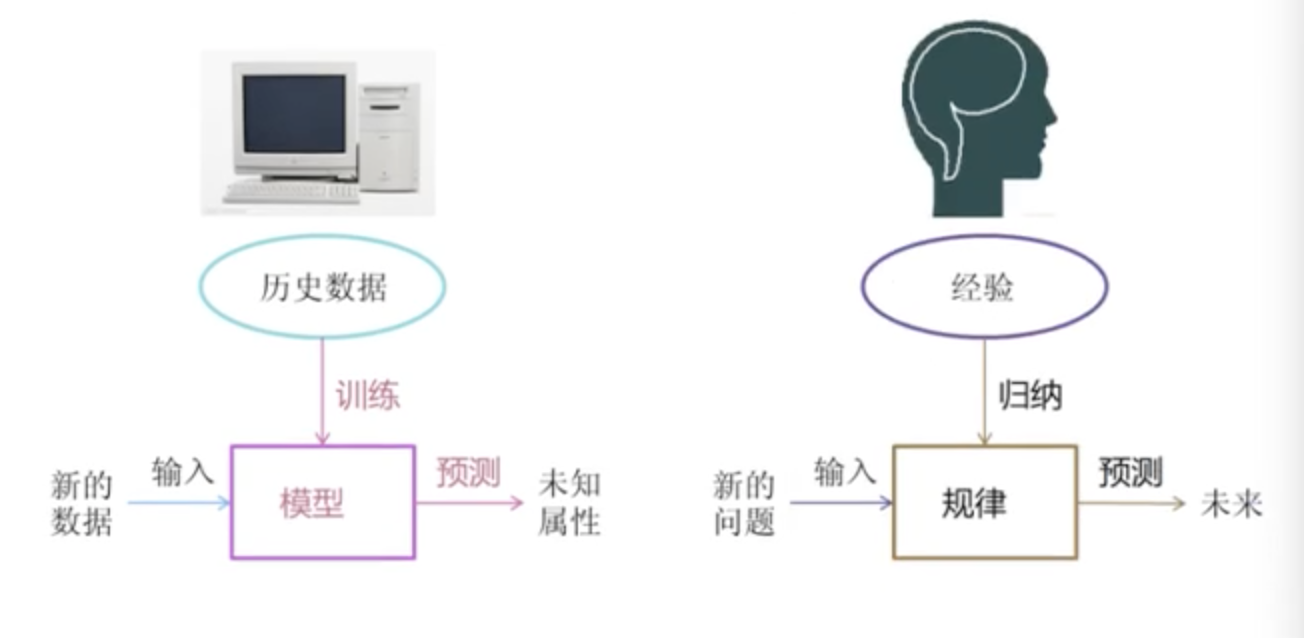
1|0什么是机器学习
2|0机器学习工作流程
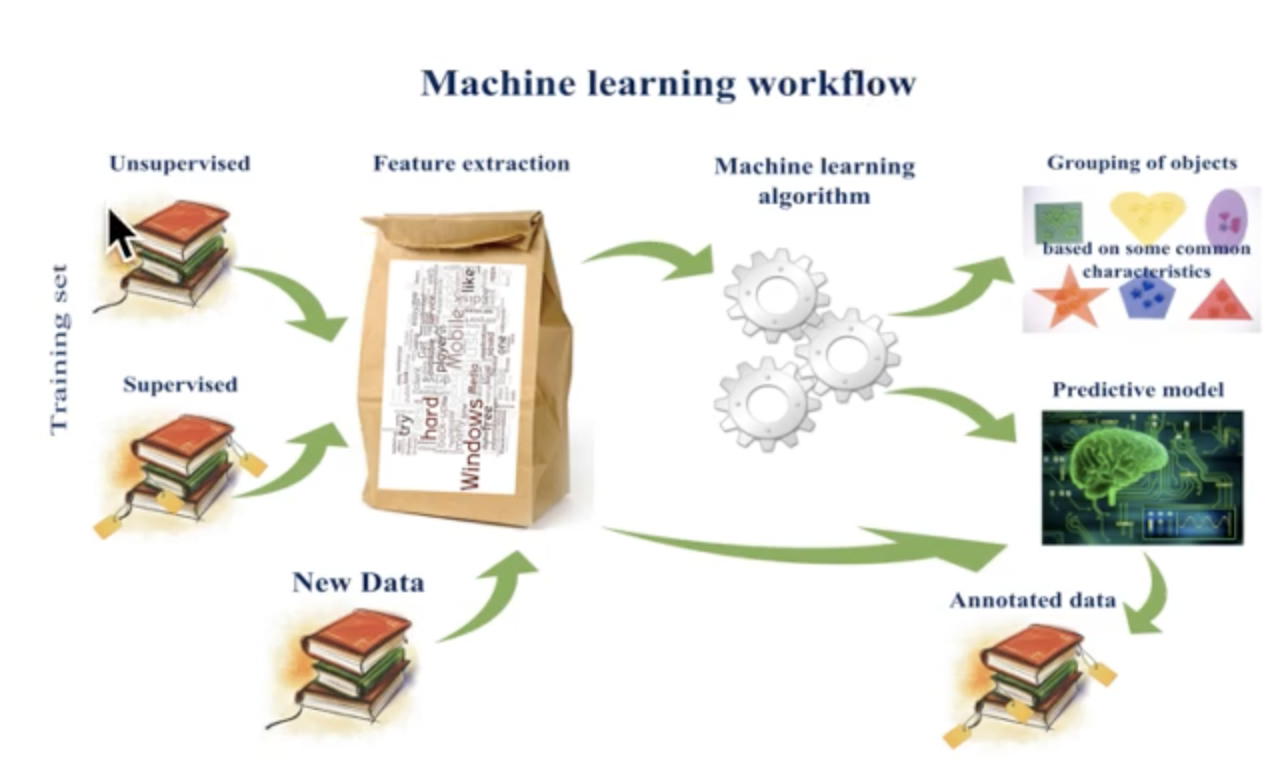
2|1获取到的数据集介绍
2|2特征工程
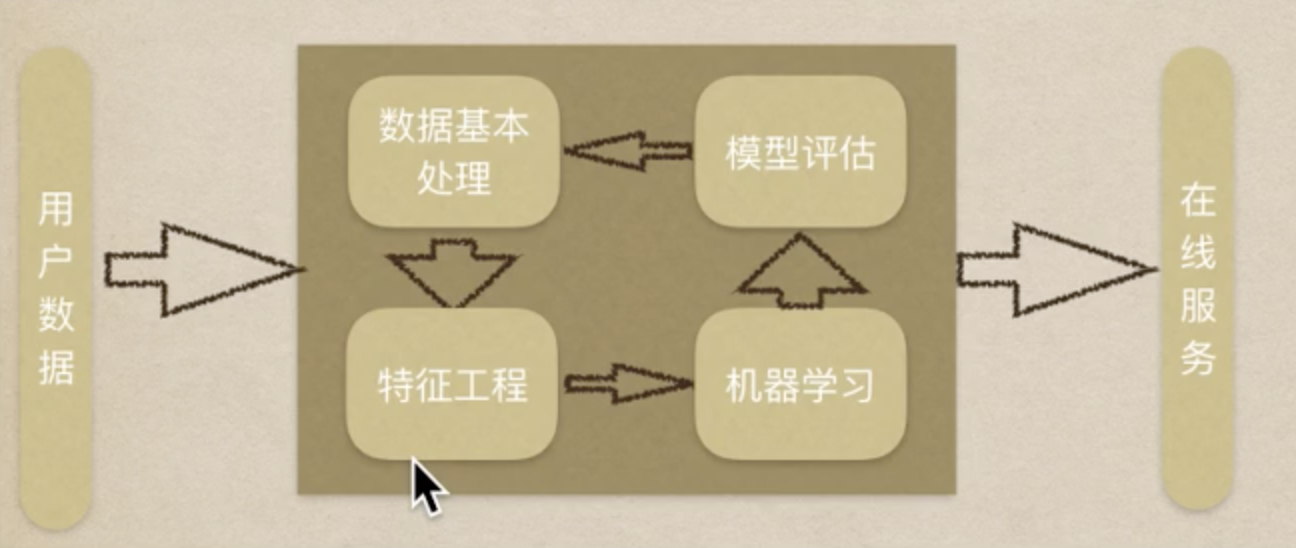
3|0完整机器学习流程
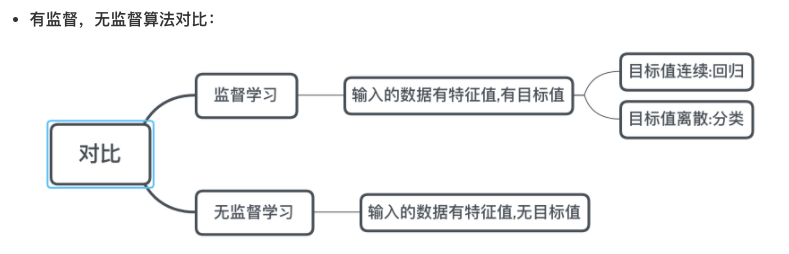
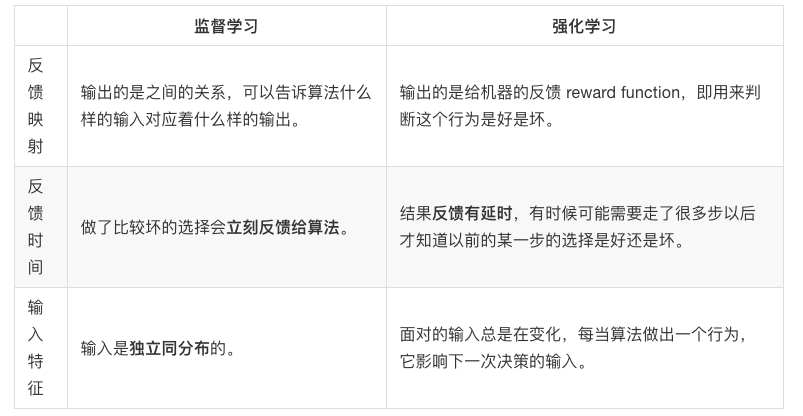
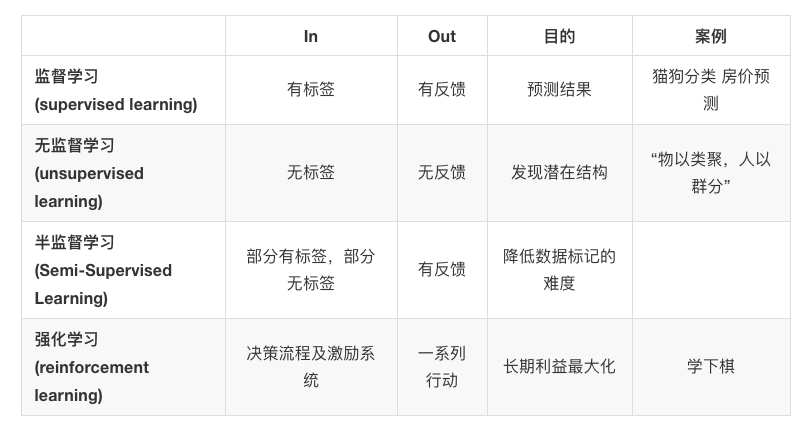
4|0机器学习算法分类
- 监督学习
- 无监督学习
- 半监督学习
- 强化学习
__EOF__

本文作者:404 Not Found
本文链接:https://www.cnblogs.com/weiweivip666/p/14214388.html
关于博主:可能又在睡觉
版权声明:转载请注明出处
声援博主:如果看到我睡觉请喊我去学习
本文链接:https://www.cnblogs.com/weiweivip666/p/14214388.html
关于博主:可能又在睡觉
版权声明:转载请注明出处
声援博主:如果看到我睡觉请喊我去学习
-------------------------------------------
个性签名:代码过万,键盘敲烂!!!
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,博主在此感谢!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人