数据分析day01
1|0数据分析三剑客
- numpy
- pandas(重点)
- matplotlib
2|0numpy模块
2|1numpy的创建
- 使用 array()创建一个一维数组
- 使用array创建一个多维数组
- 数组和列表的区别是什么?
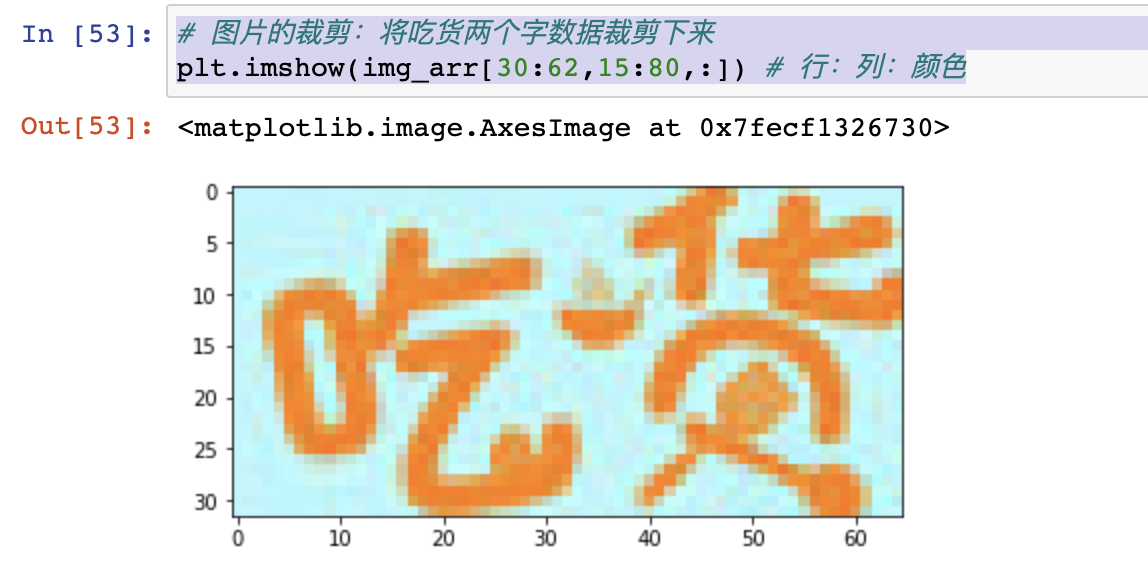
- 将外部的一张图片读取加载到numpy数组中,然后尝试改变数组元素的数值查看对原始图片的影响

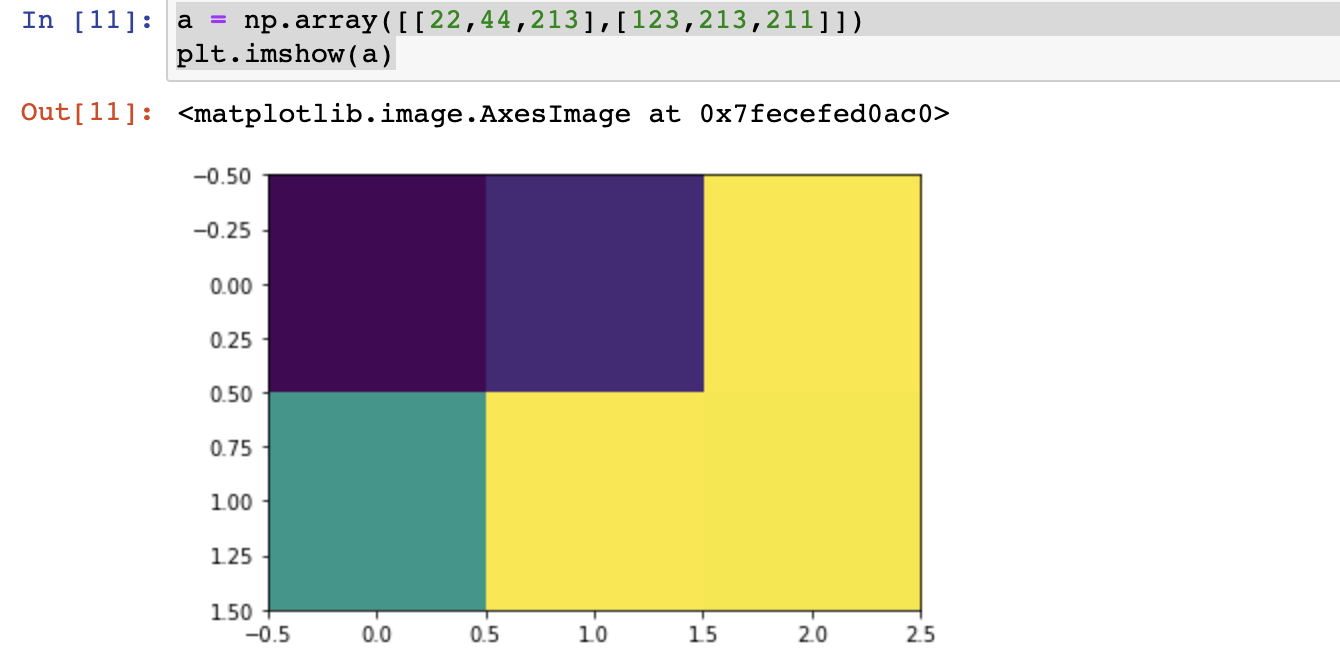

- ones()


- zeros()


- linespace()

- arange()

- random.randint()

- random.random()

2|2numpy的常用属性
- shape
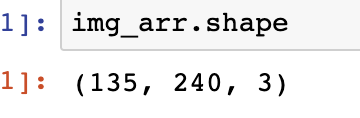
- ndim

- size

- dtype

2|3numpy的数据类型

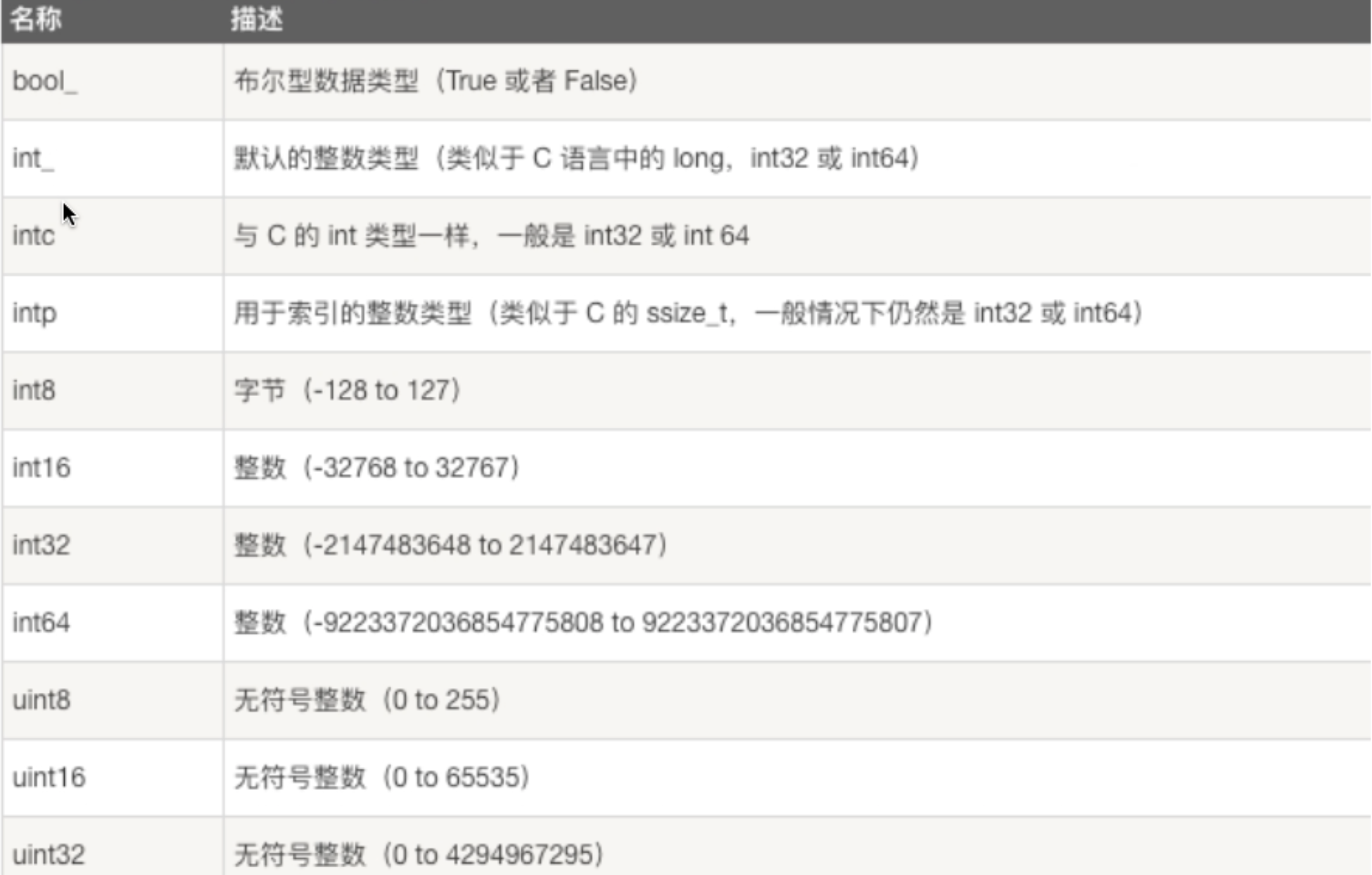

numpy的数值类型实际上是dtype对象的实例,并对应唯一的字符,包括np.bool,np.int32,np.float32....等
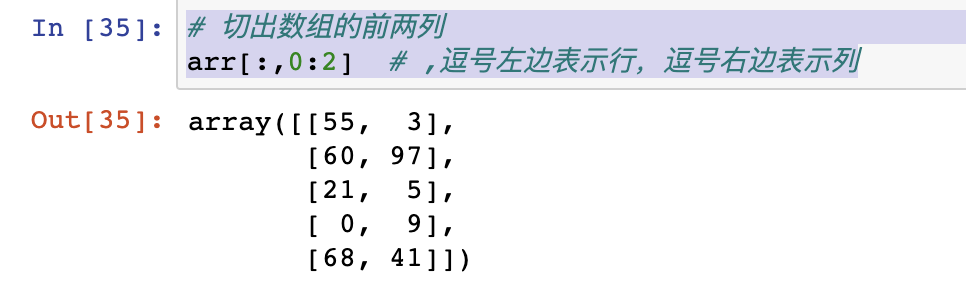
2|4numpy的索引和切片操作(重点)
- 索引操作和列表同理



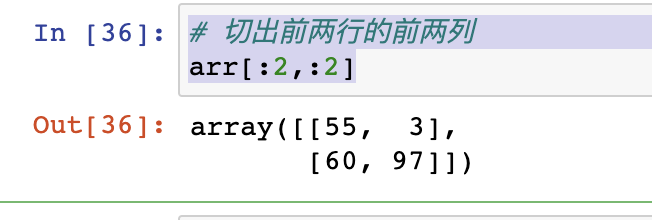
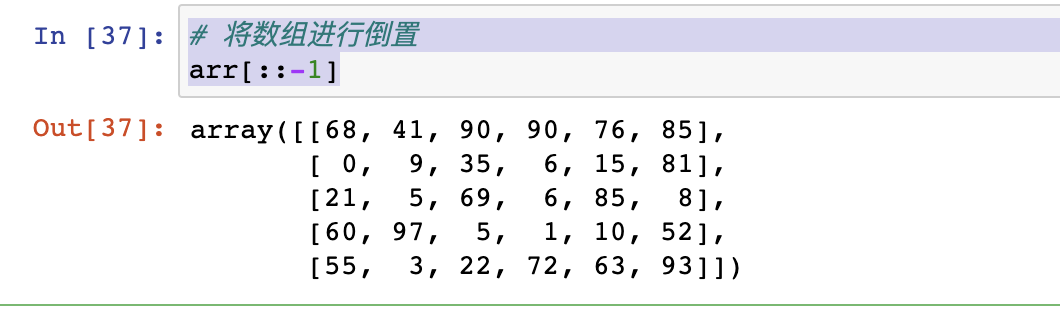



2|5变形reshape
2|6级联操作
- 将多个numpy数组进行横向或者纵向的拼接



2|7常用的聚合操作
- sum,max,min,mean
2|8常用的数学函数
- NumPy提供了标准的三角函数:sin()、cos()、tan()
- numpy.around(a,decimals)函数返回指定数字的四舍五入值。



2|9函数的统计函数
- numpy.amin()和numpy.amax(),用于计算数组中的元素沿指定轴的最小 ,最大值
- numpy.ptp():计算数组中元素最大值与最小值的差(最大值-最小值)
- numpy.median() 函数用于计算数组a中元素的中位数(中值)
- 标准差std():标准差是一组数据平均值分散程度的一种度量。
- 方差var():统计中的方差(样本方差)是每个样本值与全体样本值的平均数之差的平方值的平均数,即mean((x-x.mean())**2).换句话说 ,标准差是方差的平方根。
3|0矩阵相关
- NumPy中包含了一个矩阵库 numpy.matlib,该模块中的函数返回的是一个矩阵,而不是ndarry对象,一个的矩阵是一个由行(row)列(column)元素排列成的矩形阵列
- numpy.matlib.identity()函数返回给定大小的单位矩阵。单位矩阵是个方阵,从左上角到右下角的对角线(称为主对角线)上的元素均为1,除此以外都为0。
3|1转置矩阵
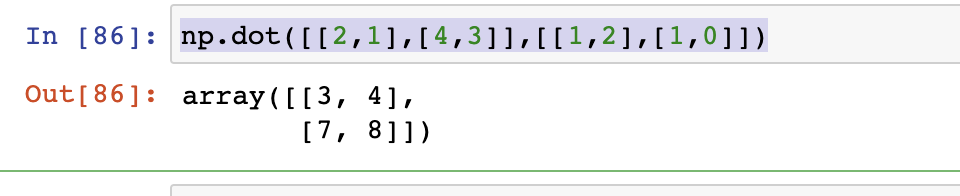
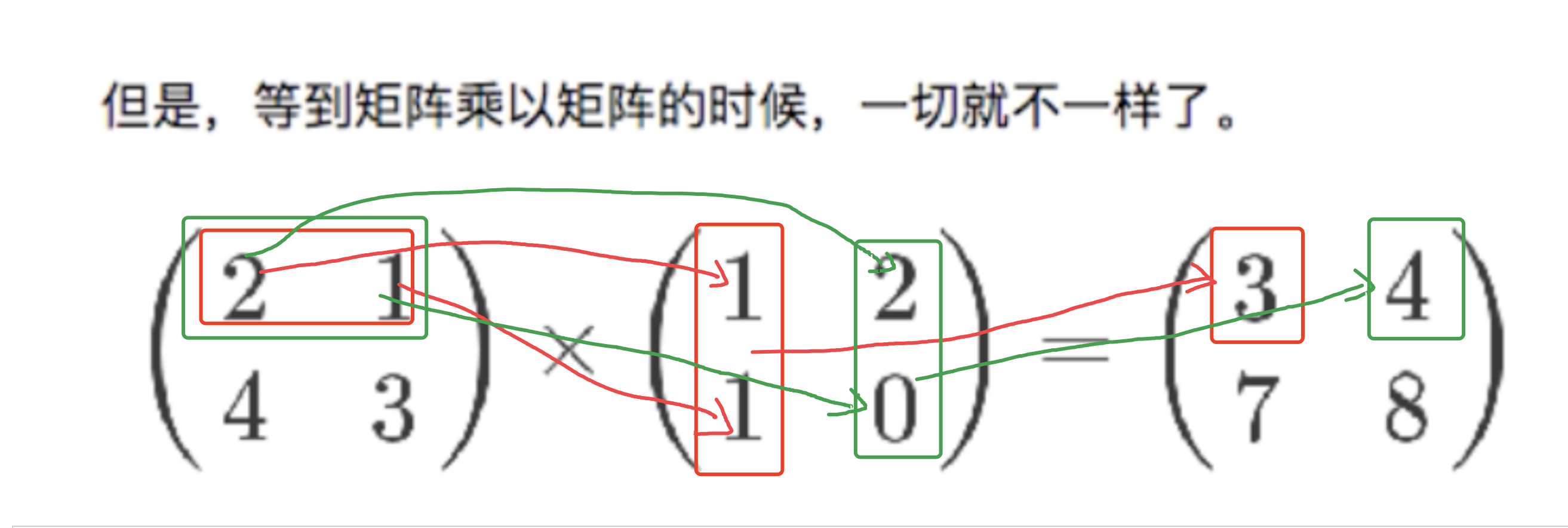
3|2矩阵相乘
- numpy.dot(a,b,out=None)


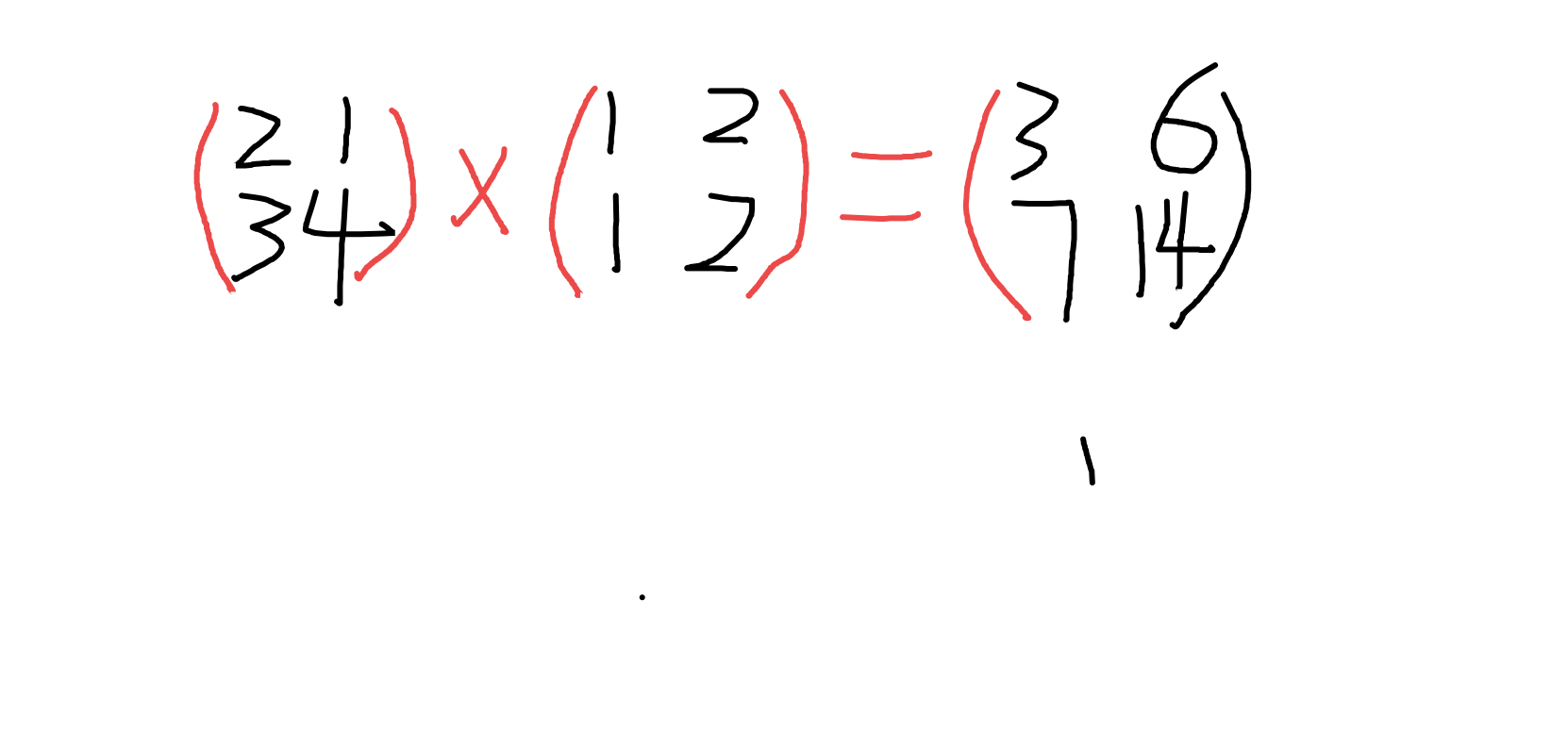

4|0pandas基础操作
4|1为什么学习pandas
4|2什么是pandas
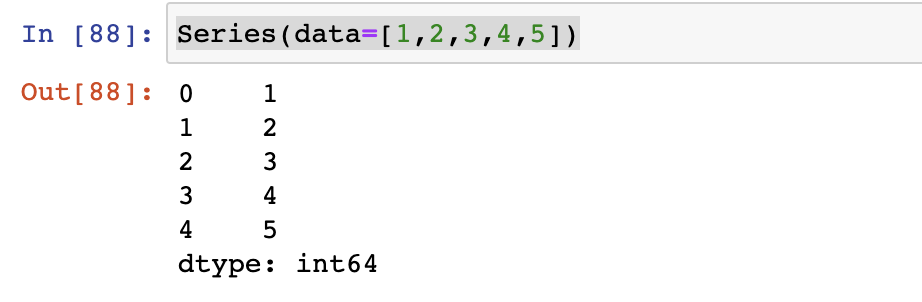
- 首先来认识pandas的两个常用的类
- Series
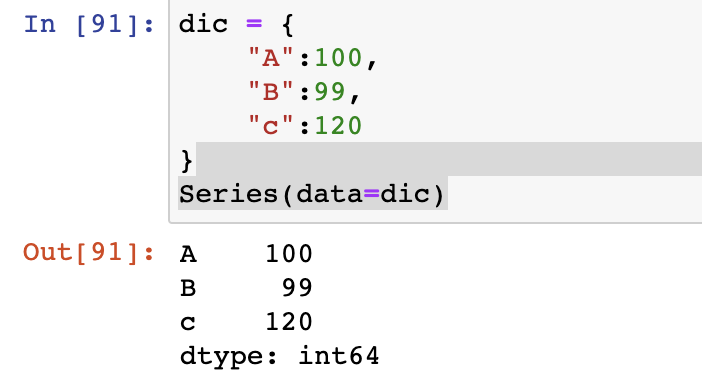


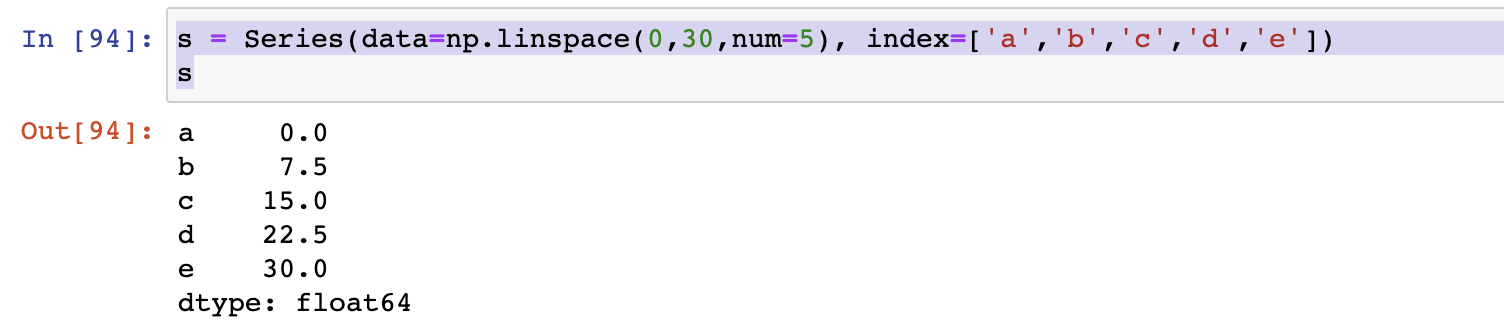

- DataFrame


5|0练习
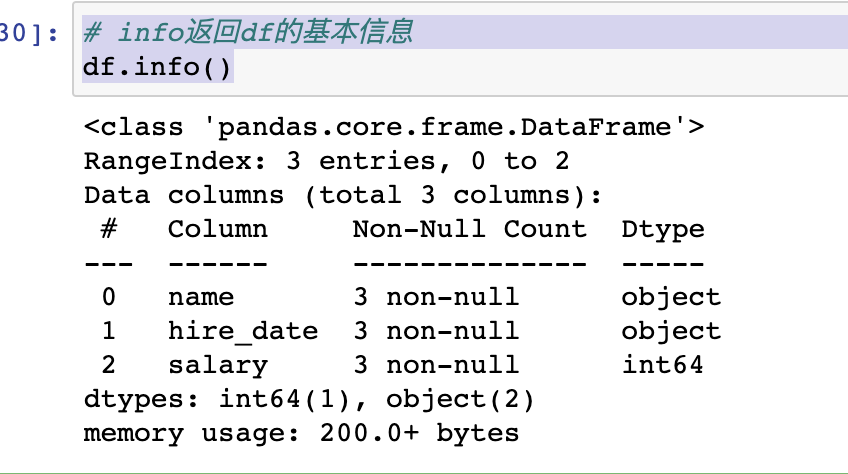
5|1时间数据类型转换


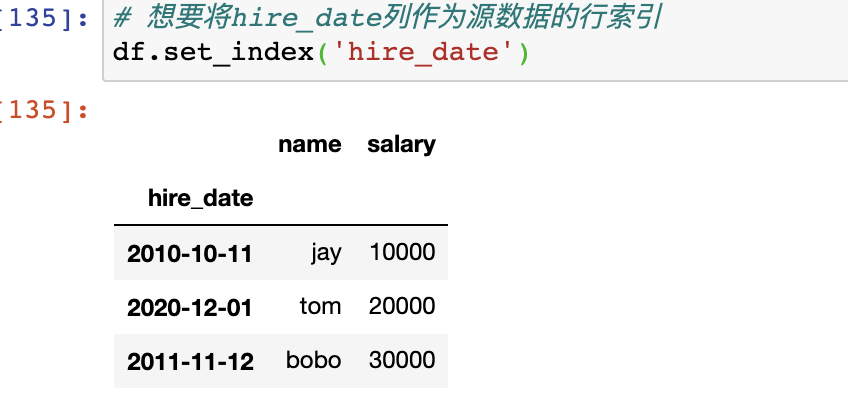
5|2将某一列设置为行索引
5|3案例
__EOF__

本文作者:404 Not Found
本文链接:https://www.cnblogs.com/weiweivip666/p/14214350.html
关于博主:可能又在睡觉
版权声明:转载请注明出处
声援博主:如果看到我睡觉请喊我去学习
本文链接:https://www.cnblogs.com/weiweivip666/p/14214350.html
关于博主:可能又在睡觉
版权声明:转载请注明出处
声援博主:如果看到我睡觉请喊我去学习
-------------------------------------------
个性签名:代码过万,键盘敲烂!!!
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个“推荐”哦,博主在此感谢!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人