
Google Guava 中布隆过滤器的介绍和使用
一、简介
布隆过滤器(Bloom Filter)是非常经典的,以空间换时间的算法。布隆过滤器由布隆在 1970 年提出。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
二、实现原理
布隆过滤器的核心实现是一个超大的位数组和几个哈希函数。假设位数组的长度为 m,哈希函数的个数为 k。
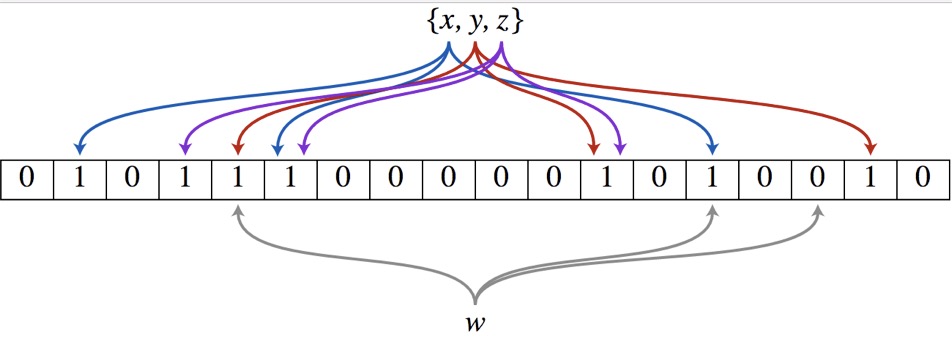
以上图为例,具体的操作流程:假设集合里面有 3 个元素 {x, y, z},哈希函数的个数为 3。首先将位数组进行初始化,将里面每个位都设置位 0。对于集合里面的每一个元素,将元素依次通过 3 个哈希函数进行映射,每次映射都会产生一个哈希值,这个值对应位数组上面的一个点,然后将位数组对应的位置标记为 1。查询 W 元素是否存在集合中的时候,同样的方法将 W 通过哈希映射到位数组上的 3 个点。如果 3 个点的其中有一个点不为 1,则可以判断该元素一定不存在集合中。反之,如果 3 个点都为 1,则该元素可能存在集合中。注意:此处不能判断该元素是否一定存在集合中,可能存在一定的误判率。可以从图中可以看到:假设某个元素通过映射对应下标为 4、5、6 这 3 个点。虽然这 3 个点都为 1,但是很明显这 3 个点是不同元素经过哈希得到的位置,因此这种情况说明元素虽然不在集合中,也可能对应的都是 1,这是误判率存在的原因。
1、布隆过滤器添加元素
- 将要添加的元素给 k 个哈希函数
- 得到对应于位数组上的 k 个位置
- 将这 k 个位置设为 1
2、布隆过滤器查询元素
- 将要查询的元素给 k 个哈希函数
- 得到对应于位数组上的 k 个位置
- 如果 k 个位置有一个为 0,则肯定不在集合中
- 如果 k 个位置全部为 1,则可能在集合中
3、布隆过滤器的优缺点
优点
相比于其它的数据结构,布隆过滤器在空间和时间方面都有巨大的优势。布隆过滤器存储空间和插入/查询时间都是常数。另外,Hash 函数相互之间没有关系,方便由硬件并行实现。布隆过滤器不需要存储元素本身,在某些对保密要求非常严格的场合有优势。
布隆过滤器可以表示全集,其它任何数据结构都不能。
缺点
但是布隆过滤器的缺点和优点一样明显。误算率(False Positive)是其中之一。随着存入的元素数量增加,误算率随之增加(误判补救方法是:再建立一个小的白名单,存储那些可能被误判的信息)。但是如果元素数量太少,则使用散列表足矣。
另外,一般情况下不能从布隆过滤器中删除元素。我们很容易想到把位列阵变成整数数组,每插入一个元素相应的计数器加 1, 这样删除元素时将计数器减掉就可以了。然而要保证安全的删除元素并非如此简单。首先我们必须保证删除的元素的确在布隆过滤器里面. 这一点单凭这个过滤器是无法保证的。另外计数器回绕也会造成问题。
三、使用 Guava 的布隆过滤器
1、添加依赖
Maven:
1 2 3 4 5 | <dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>22</version></dependency> |
Gradle:
1 2 | // https://mvnrepository.com/artifact/com.google.guava/guavacompile group: 'com.google.guava', name: 'guava', version: '22' |
2、使用方法
创建 BloomFilter 对象,需要传入 Funnel 对象,预估的元素个数,误判率。
1 | BloomFilter<String> filter = BloomFilter.create(Funnels.stringFunnel(Charset.defaultCharset()), 1000,0.01); |
使用 put 方法添加元素:
1 | filter.put("test"); |
使用 mightContain 方法判断元素是否存在:
1 | filter.mightContain("test"); |
3、例子
这个例子中我向布隆过滤器中添加了 10000000 条数据,将 fpp(误判率)设置为 0.001(0.1%)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 | public class BloomFilterTest { private static int insertions = 10000000; public static void main(String[] args) { BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charset.defaultCharset()), insertions, 0.001); Set<String> sets = new HashSet<String>(insertions); List<String> lists = new ArrayList<String>(insertions); for (int i = 0; i < insertions; i++) { String uid = UUID.randomUUID().toString(); bloomFilter.put(uid); sets.add(uid); lists.add(uid); } int right = 0; int wrong = 0; for (int i = 0; i < 10000; i++) { String data = i % 100 == 0 ? lists.get(i / 100) : UUID.randomUUID().toString(); if (bloomFilter.mightContain(data)) { if (sets.contains(data)) { right++; continue; } wrong++; } } NumberFormat percentFormat = NumberFormat.getPercentInstance(); percentFormat.setMaximumFractionDigits(2); float percent = (float) wrong / 9900; float bingo = (float) (9900 - wrong) / 9900; System.out.println("在 " + insertions + " 条数据中,判断 100 实际存在的元素,布隆过滤器认为存在的数量为:" + right); System.out.println("在 " + insertions + " 条数据中,判断 9900 实际不存在的元素,布隆过滤器误认为存在的数量为:" + wrong); System.out.println("命中率为:" + percentFormat.format(bingo) + ",误判率为:" + percentFormat.format(percent)); }} |
经过我多次测试,执行结果中的误判率基本保持在 0.1% 左右,误差不会太大。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | 在 10000000 条数据中,判断 100 实际存在的元素,布隆过滤器认为存在的数量为:100在 10000000 条数据中,判断 9900 实际不存在的元素,布隆过滤器误认为存在的数量为:8命中率为:99.92%,误判率为:0.08%在 10000000 条数据中,判断 100 实际存在的元素,布隆过滤器认为存在的数量为:100在 10000000 条数据中,判断 9900 实际不存在的元素,布隆过滤器误认为存在的数量为:9命中率为:99.91%,误判率为:0.09%在 10000000 条数据中,判断 100 实际存在的元素,布隆过滤器认为存在的数量为:100在 10000000 条数据中,判断 9900 实际不存在的元素,布隆过滤器误认为存在的数量为:10命中率为:99.9%,误判率为:0.1%在 10000000 条数据中,判断 100 实际存在的元素,布隆过滤器认为存在的数量为:100在 10000000 条数据中,判断 9900 实际不存在的元素,布隆过滤器误认为存在的数量为:15命中率为:99.85%,误判率为:0.15%在 10000000 条数据中,判断 100 实际存在的元素,布隆过滤器认为存在的数量为:100在 10000000 条数据中,判断 9900 实际不存在的元素,布隆过滤器误认为存在的数量为:10命中率为:99.9%,误判率为:0.1% |
四、应用场景
利用布隆过滤器减少磁盘 IO 或者网络请求,因为一旦一个值必定不存在的话,我们可以不用进行后续昂贵的查询请求,比如以下场景:
1、大数据去重;
2、网页爬虫对 URL 的去重,避免爬取相同的 URL 地址;
3、反垃圾邮件,从数十亿个垃圾邮件列表中判断某邮箱是否垃圾邮箱;
4、缓存击穿,将已存在的缓存放到布隆中,当黑客访问不存在的缓存时迅速返回避免缓存及数据库挂掉。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架