CSV文件分割与列异常处理的python脚本
处理csv文件时经常会遇到下面的问题:
1. 文件过大(需要进行文件分割)
2. 列异常(列不一致,如原始数据的列为10列,但导出的csv文件有些行是11列,或者4列)
本脚本用于解决此问题。
使用说明:
> python csvtoolkit.py -h
usage: csvtoolkit.py [-h] [-f CSV_FILENAME] [-d DELIMITER_CHAR]
[-n SPLIT_FILE_NUMBERS] [-e OUTPUT_ENCODING]
本脚本用来分割处理csv文件,其中解决了csv文件的列异常问题。
使用示例如下:
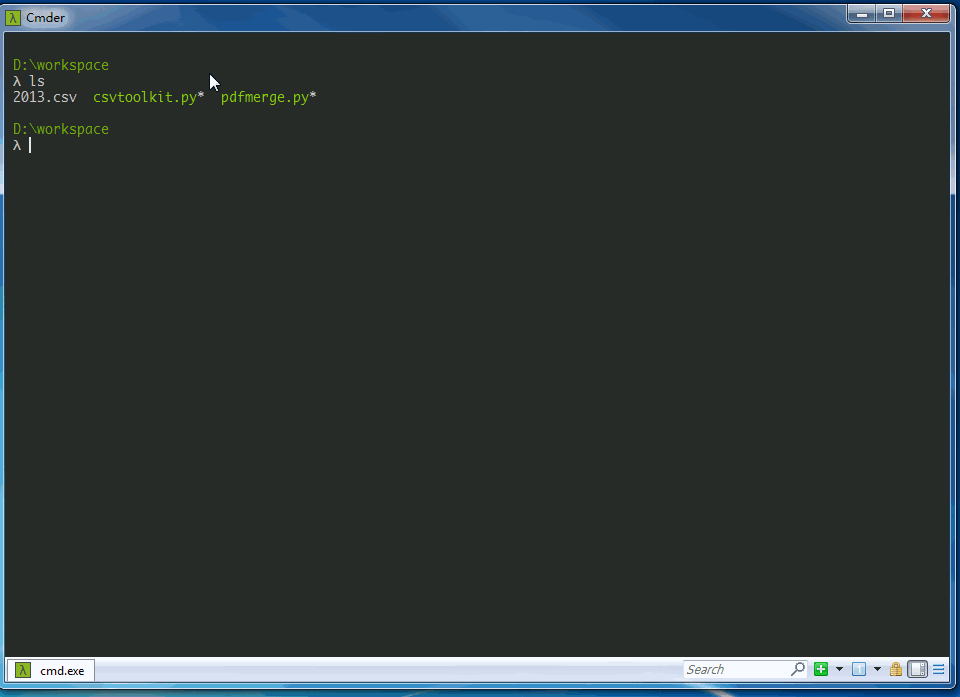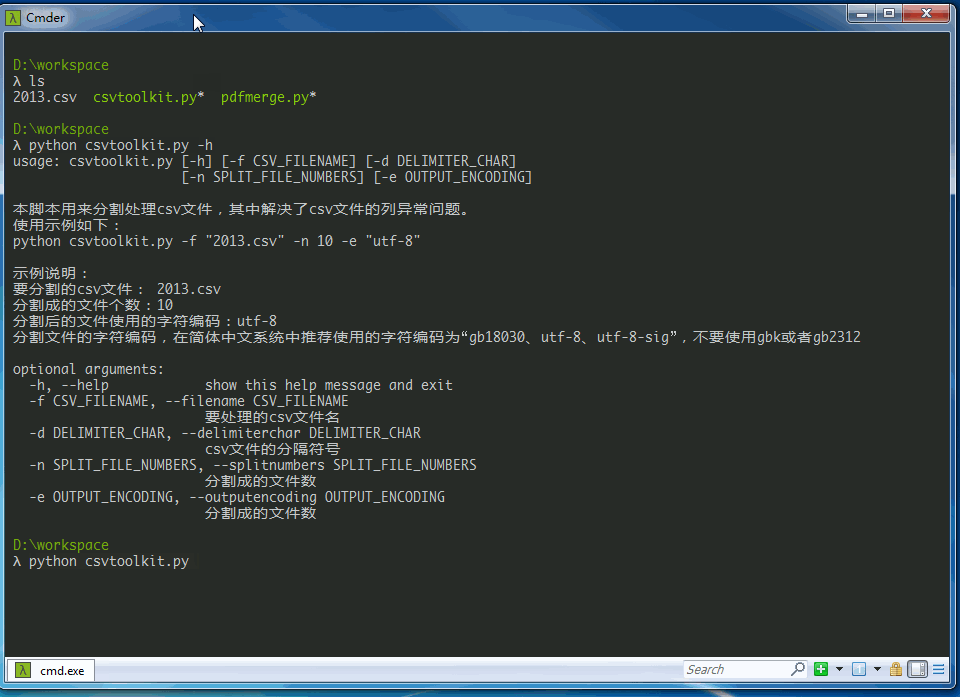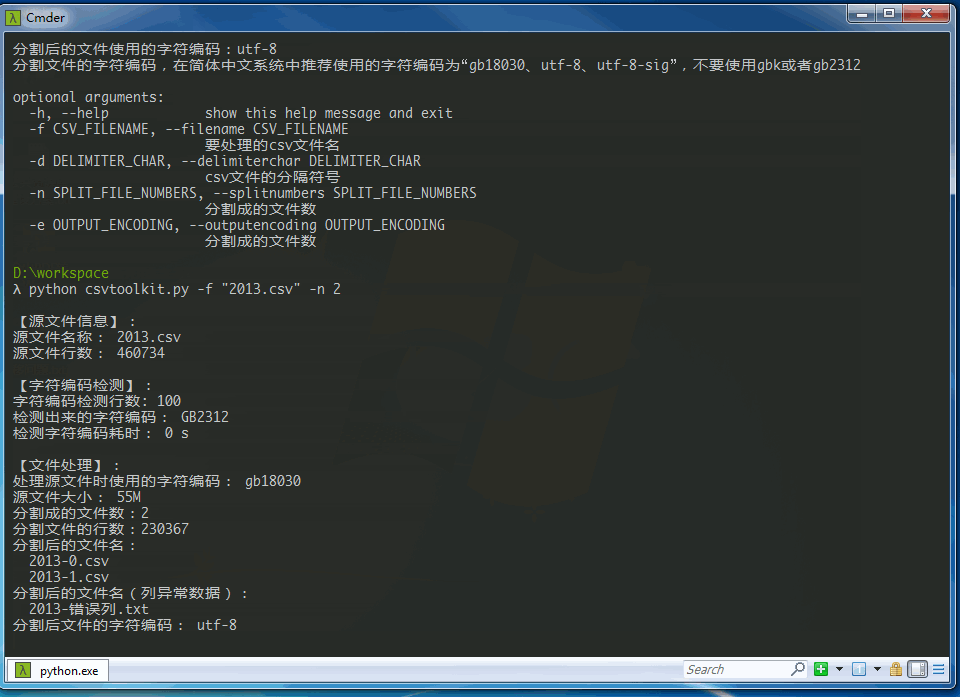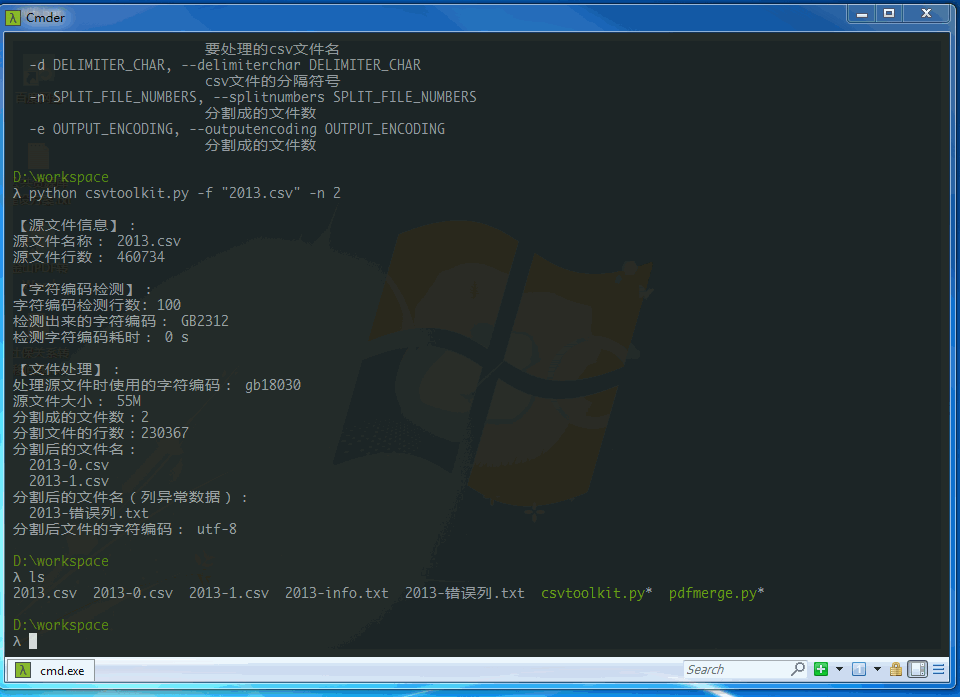
python csvtoolkit.py -f "2013.csv" -n 10 -e "utf-8"
示例说明:
要分割的csv文件: 2013.csv
分割成的文件个数:10
分割后的文件使用的字符编码:utf-8
分割文件的字符编码,在简体中文系统中推荐使用的字符编码为“gb18030、utf-8、utf-8-sig”,不要使用gbk或者gb2312
optional arguments:
-h, --help show this help message and exit
-f CSV_FILENAME, --filename CSV_FILENAME
要处理的csv文件名
-d DELIMITER_CHAR, --delimiterchar DELIMITER_CHAR
csv文件的分隔符号
-n SPLIT_FILE_NUMBERS, --splitnumbers SPLIT_FILE_NUMBERS
分割成的文件数
-e OUTPUT_ENCODING, --outputencoding OUTPUT_ENCODING
分割成的文件数
1 #!/usr/bin/env python3 2 #coding=utf-8 3 4 import os, csv, sys, locale, codecs, chardet, time 5 from argparse import ArgumentParser, RawTextHelpFormatter 6 7 #操作系统中默认的文件编码(当文件编码为中文扩展字符集时,统一使用gb18030编码--比gb2312和gbk支持的汉字多,同时兼容gb2312和gbk) 8 #中文扩展字符集编码列表 9 chinese_charsetstr='|gbk|gb2312|gb18030|cp936|' 10 default_chinese_charset='gb18030' 11 #使用gb18030解决了类似下面的错误:UnicodeDecodeError: 'gbk' codec can't decode byte 0xf8 in position 5902: illegal multibyte sequence 12 defaultencoding = default_chinese_charset if chinese_charsetstr.find(locale.getpreferredencoding().lower())>0 else locale.getpreferredencoding().lower() 13 14 def detectfileencoding(filename, filerowcount=None, info_fileobj=None): 15 #获取文件编码(为空则设置为操作系统默认文件编码,其中中文扩展字符集统一设置为'gb18030'大字符集) 16 time_start=time.time() 17 #编码检测结果 18 detectresult='' 19 with codecs.open(filename, 'rb') as fobj: 20 if filerowcount==None: 21 fcontent = fobj.read() 22 detectresult = chardet.detect(fcontent) 23 else: 24 linenum = 0 25 maxdetectrownum = 100 if filerowcount > 100 else filerowcount 26 #初始化要检测编码的内容 27 fcontent = bytes() 28 for line in fobj.readlines(): 29 linenum += 1 30 if linenum < maxdetectrownum: 31 fcontent += line 32 else: 33 break 34 print_twice("\r\n【字符编码检测】:\r\n字符编码检测行数: %d"%(linenum), fileobj=info_fileobj) 35 detectresult = chardet.detect(fcontent) 36 detectencoding=detectresult.get('encoding') 37 print_twice("检测出来的字符编码: %s"%(detectencoding), fileobj=info_fileobj) 38 if detectencoding is None: 39 fileencoding = defaultencoding 40 else: 41 fileencoding = default_chinese_charset if chinese_charsetstr.find(detectencoding.lower())>0 else detectencoding 42 time_end=time.time() 43 print_twice("检测字符编码耗时: %d s"%(time_end-time_start), fileobj=info_fileobj) 44 return fileencoding 45 46 def getfilerowscount(filename): 47 # 计算文件总行数 48 count=-1 49 #, encoding=fileencoding 50 with codecs.open(filename, 'rb') as fobj: 51 for count,line in enumerate(fobj): 52 pass 53 count += 1 54 return count 55 56 def print_twice(output_string, fileobj): 57 #打印输出两次,“终端输出”和“输出到文件” 58 print(output_string) 59 print(output_string, file=fileobj) 60 61 def spit_csvfile(filename, delimiterchar=",", splitnumbers=0, outputencoding='utf-8' ): 62 if not os.path.isfile(filename): 63 print('不存在文件: %s'%(filename)) 64 #退出脚本 65 sys.exit() 66 file_path = os.path.split(filename)[0] 67 short_filename = os.path.basename(os.path.splitext(filename)[0]) 68 file_ext = os.path.splitext(filename)[1] 69 #日志文件名 70 info_filename = os.path.join(file_path, short_filename+'-info'+'.txt') 71 72 #获取文件行数 73 rowscount = getfilerowscount(filename) 74 #行号,初始值为1 75 rowsnum = 1 76 #列数,初始值为0(处理过程中将以第一行为标准,即以第一行的列数为正确的列数) 77 columncount = 0 78 #列正确的文件,生成正常的分割文件: 源文件-0.csv 源文件-1.csv 79 #列错误的文件: 源文件名-错误列.csv 80 error_filename = os.path.join(file_path, short_filename+'-错误列'+'.txt') 81 #打开日志文件 82 fileobj_info = open(info_filename, 'w+', newline='\r\n', encoding=outputencoding) 83 84 #获取csv文件信息 85 statinfo = os.stat(filename) 86 print_twice('\r\n【源文件信息】: ', fileobj=fileobj_info) 87 print_twice("源文件名称: %s"%(filename), fileobj=fileobj_info) 88 print_twice("源文件行数: %s"%(str(rowscount)), fileobj=fileobj_info) 89 #获取文件编码 90 file_encoding = detectfileencoding(filename, filerowcount=rowscount, info_fileobj=fileobj_info) 91 92 print_twice('\r\n【文件处理】:', fileobj=fileobj_info) 93 print_twice('处理源文件时使用的字符编码: %s'%(file_encoding), fileobj=fileobj_info) 94 print_twice("源文件大小: %s"%(str(statinfo.st_size//1024//1024)+"M"), fileobj=fileobj_info) 95 96 print_twice("分割成的文件数:%s"%(str(splitnumbers)), fileobj=fileobj_info) 97 splitLineCount = rowscount//splitnumbers 98 print_twice("分割文件的行数:%s"%(str(splitLineCount)), fileobj=fileobj_info) 99 100 # 可以用一个list包含文件对象列表 101 # 源文件名-文件序号.csv 102 fileList = [] 103 fileIndex = 0 104 print_twice("分割后的文件名:", fileobj=fileobj_info) 105 while fileIndex < splitnumbers: 106 filename_tmp=os.path.join(file_path, short_filename+'-'+str(fileIndex)+file_ext) 107 print_twice(" "+filename_tmp, fileobj=fileobj_info) 108 file_tmp=codecs.open(filename_tmp, 'w+', encoding=outputencoding) 109 fileList.append(file_tmp) 110 fileIndex=fileIndex+1 111 112 113 fileobj_error=codecs.open(error_filename, 'w+', encoding=outputencoding) 114 print_twice("分割后的文件名(列异常数据):", fileobj=fileobj_info) 115 print_twice(" %s"%(error_filename), fileobj=fileobj_info) 116 117 print_twice("分割后文件的字符编码: %s"%(outputencoding), fileobj=fileobj_info) 118 119 with codecs.open(filename, encoding=file_encoding) as csvfile: 120 spamreader = csv.reader(csvfile,delimiter=delimiterchar) 121 for line in spamreader: 122 # 列数为0时,读取第一行作为准确的列数。 123 if ( columncount == 0 ): 124 columncount = len(line) 125 # 列数不为0时,当前行的列数与其匹配,将匹配的和不匹配的保存到不同的文件。 126 else: 127 #列数和第一行的列数匹配,则输出到分割的文件中 128 if ( columncount == len(line) ): 129 # 输出到对应文件序号的文件中: 行数“整除”分割行数 130 if ( rowsnum//splitLineCount > len(fileList)-1 ): 131 print((','.join(line)), file=fileList[len(fileList)-1]) 132 else: 133 print((','.join(line)), file=fileList[rowsnum//splitLineCount]) 134 else : 135 #列数与第一行的列数不匹配,则输出到异常文件中 136 print((','.join(line)), file=fileobj_error) 137 rowsnum=rowsnum+1 138 139 fileIndex=0 140 #文件列表中的文件处理:刷新缓存区,关闭文件 141 while fileIndex < splitnumbers: 142 if not fileList[fileIndex].closed: 143 fileList[fileIndex].flush() 144 fileList[fileIndex].close() 145 fileIndex=fileIndex+1 146 #关闭文件 147 if not fileobj_error.closed: 148 fileobj_error.flush() 149 fileobj_error.close() 150 if not fileobj_info.closed: 151 fileobj_info.flush() 152 fileobj_info.close() 153 154 if __name__ == "__main__": 155 description="\n本脚本用来分割处理csv文件,其中解决了csv文件的列异常问题。\n使用示例如下:" 156 description=description+'\npython csvtoolkit.py -f "2013.csv" -n 10 -e "utf-8"' 157 description=description+'\n\n'+"示例说明:" 158 description=description+'\n'+"要分割的csv文件: 2013.csv" 159 description=description+'\n'+"分割成的文件个数:10" 160 description=description+'\n'+"分割后的文件使用的字符编码:utf-8" 161 description=description+'\n'+"分割文件的字符编码,在简体中文系统中推荐使用的字符编码为“gb18030、utf-8、utf-8-sig”,不要使用gbk或者gb2312" 162 163 # 添加程序帮助,程序帮助支持换行符号 164 parser = ArgumentParser(description=description, formatter_class=RawTextHelpFormatter) 165 166 # 添加命令行选项 167 168 parser.add_argument("-f", "--filename", 169 dest="csv_filename", 170 default="", 171 help="要处理的csv文件名") 172 parser.add_argument("-d", "--delimiterchar", 173 dest="delimiter_char", 174 default=",", 175 help="csv文件的分隔符号") 176 parser.add_argument("-n", "--splitnumbers", 177 dest="split_file_numbers", 178 default=0, 179 help="分割成的文件数") 180 parser.add_argument("-e", "--outputencoding", 181 dest="output_encoding", 182 default='utf-8', 183 help="分割成的文件数") 184 185 args = parser.parse_args() 186 187 #try: 188 spit_csvfile(args.csv_filename, args.delimiter_char, int(args.split_file_numbers), args.output_encoding) 189 #except: 190 # print('Error to split csv file:') 191 # print(sys.exc_info()[0],sys.exc_info()[1])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号