
C# NetCore使用AngleSharp爬取周公解梦数据 起因和页面数据拆解
起因
最近突然心血来潮想做个小程序,学习一下小程序开发流程,然后新手就想做个查询的就可以了,少点交互能力,这种思来想去还是周公解梦比较靠谱,
网上一搜,还真有小程序源码,但是这里面似乎数据都是取第三方api的或者固定死的演示数据,或者残缺不全的数据,然后csdn上面居然还有积分下载周公
解梦数据的,评论都是说数据不全的,我这个脑子啊,这我就不愿意了,我要就要最全的,搞出来我也分享一下数据。。。。。。(其实是不是还是拖延症啊
不想学习小程序!!!)
然后网上搜了一下周公解梦,目前有一家数据是比较全的,而且页面结构是比较清晰的,可能是有程序员在维护。。。锁定数据源xzw。com 当然,如果
这种行为侵犯了xzw权益,请联系我删除。
言归正传
下面开始访问数据站,结构还是挺清晰的,梦的类别 梦的名称 里面的子项 及简介,我们大致可以设计一个表出来了

我们再点击进去看一下子项的内容,原来子项的内容都是依赖于外层的“孕妇”,这里我使用的是mysql数据库存储,
其实这种结构似乎更适合存储为nosql数据库,不纠结于这个,最多加个外键就OK。

可能初步的表是这样的
Dream表
| Id | 自增列 |
| Name | 梦的名字 例如 “孕妇” |
| Summary | 简介 这是搜索列表最外层的那个简介 |
| CateName | 分类名称 总分类可能就那固定的几个,我们这里只保存名称就好了 |
| CreateTime | 附属属性 |
| Url | 详细页面地址(这个是在下面会做说明) |
DreamInfo表
| Id | 自增列 |
| FkDreamId | Dream表主键 |
| DreamName | Dream表Name 例如 孕妇,为了不重复查询直接id和name都保存 |
| Name | 梦的详细名称,例如 未婚女人梦见孕妇 |
| Content | 梦的详细内容 |
| CreateTime | 附属属性,时间 |
分解页面结构
然后开始我们的页面分解之路,这个页面我们可以拿到 DreamName 还有Dream Summary 后面还要进入详情页绑定内容建立从属关系,
那么保存下这个详细页面的url,供我们第二次爬详细页面的时候使用,所以才会有上面dream表里的url字段,边发现边修改。
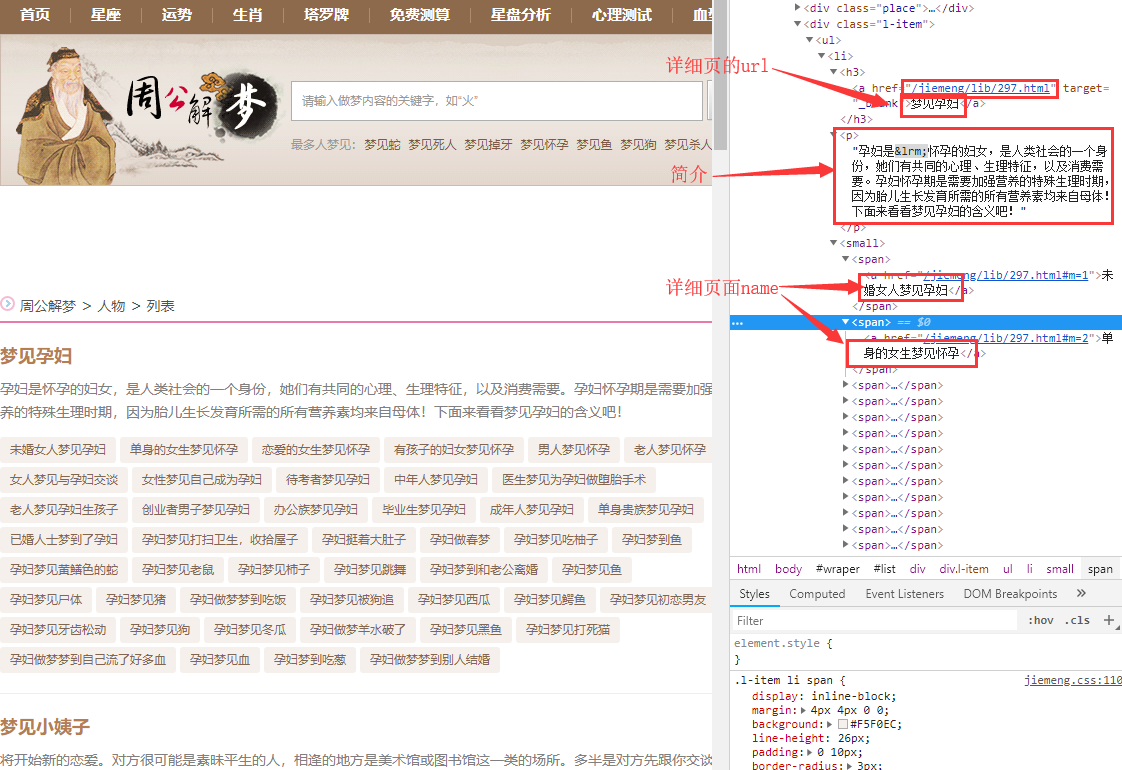
具体思路就有了,先获取分类下的名称信息、简介以及详情页url信息,下面有翻页,还是老规矩 递归翻页直到结束。
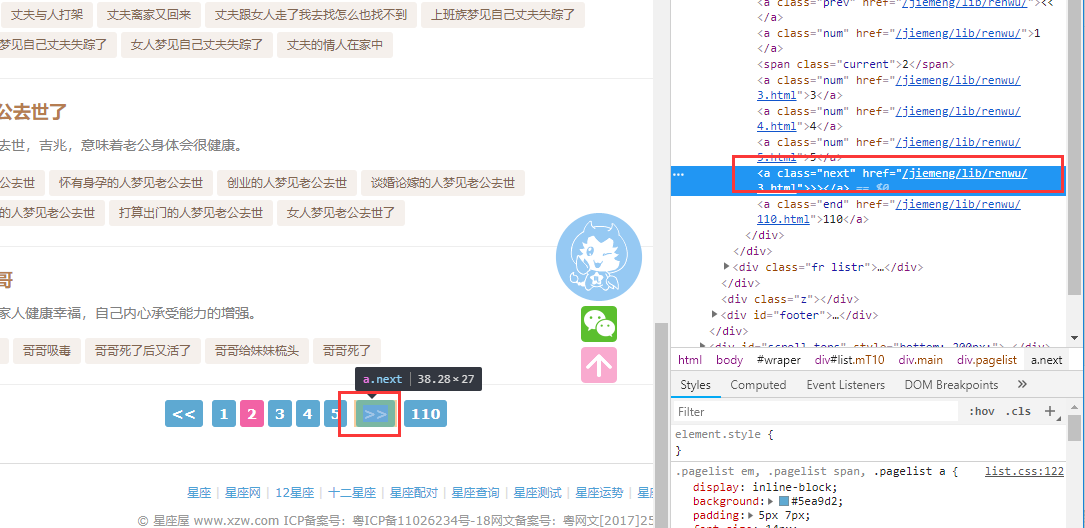
再来看看翻页,发现翻页这个地方,这里有个下一页的按钮,那么这个是不是就可以一直往下翻页了呢,我们就用它了。完美
总结
感觉自己脑袋乱糟糟的,没有固定的想法,可能一个想法牵扯出来多个想法,忘记自己第一个想法是什么了,感觉这种思维很可怕,咸鱼一般的感觉。
下一章开始详细编码。。。

