Java——重写hashCode()和euqals()方法
1.顺序表的问题
查找和去重效率较低
对于这样的顺序表来说,如果需要查找元素,就需要从第一个元素逐个检查,进行查找。对于需要去重的存储来说,每次存入一个元素之前,就得将列表中的每个元素都比对一遍,效率相当低。
1.1.解决思路
我们注意到在这里的顺序表中列表中的每个元素都有一个与之对应的索引,不过这里的索引只是与元素所在的位置有对应关系,也就是说:
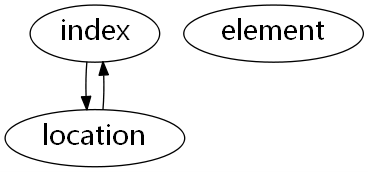
索引与顺序表中的位置有一一对应关系,但是与位置中的元素没有必然的联系。如果有某种方式能够建立这样的一个关系:

如图中所示,也就是说每个元素与其在顺序表中的索引,以及位置都有一个必然的对应关系,如此一来,每个元素在被存入数据结构之前,其位置就已经被确定了。这样无论是要查找,还是去重都会机器方便。
2.散列表
2.1.哈希函数的作用
如前面提出的这种解决思路,给每一个元素在表中找一个唯一确定的位置的这种解决方案被称为散列表。
那么,问题又来了,如何确定要存入数组的元素在表中的位置呢?这就是哈希函数的作用。
哈希函数的作用就是利用要存入表的元素的属性信息,生成一个唯一的整型值,这个值被称为哈希值,利用哈希值在表中确定一个固定的位置,用来存储这个元素。
2.2.字符串转整型的问题
一般来说存储元素的属性无外乎就两种类型,一种是数值型的,要转成整型没什么好说的;另外就主要是字符串型的,对于字符串如何将其转成整型呢?
我们知道字符串是由一个个的字符组成的,而我们可以根据ASCII码表将字符转换成对应的整型编码,这样只需要将字符串中的每个字符转成整型,然后进行相应的计算即可。
2.3.BKDR哈希算法
哈希算法有很多种,此处我们介绍一种比较常用的哈希算法,下面是这种算法的C语言实现版本。
// BKDR Hash Function unsigned int BKDRHash(char *str) { unsigned int seed = 131; // 31 131 1313 13131 131313 etc.. unsigned int hash = 0; while (*str) { hash = hash * seed + (*str++); } return (hash & 0x7FFFFFFF); }
观察这个函数,其实其内部的逻辑就是遍历一个字符数组,将每个元素对应的ASCII码值乘以一个数,然后累加起来的结果,可以转换成如下表示的一个结果:

3.重写hashCode()
3.1.重写hashCode()的原因
public class Student { private String num; private String name; public Student(String num, String name) { this.num = num; this.name = name; } public static void main(String[] args) { Student stu1 = new Student("10001", "赤骥"); Student stu2 = new Student("10001", "赤骥"); Student stu3 = new Student("10002", "白义"); System.out.println("赤骥的HashCode:" + stu1.hashCode()); System.out.println("赤骥的HashCode:" + stu2.hashCode()); System.out.println("白义的HashCode:" + stu3.hashCode()); } }
这段代码执行的结果是:
赤骥的HashCode:366712642 赤骥的HashCode:1829164700 白义的HashCode:2018699554
这段代码中,我们打印出三个对象的哈希值,我们看到Student这个类中并没有hashCode()方法,因为在Java的继承体系中,Object类是所有类的超类,也就是说实际上Student类是继承了Object类的,因此这里没有写hashCode()方法,那么调用的就是Object类的hashCode()方法了。
而根据我们之前对哈希函数的定义,这个Object类中继承的hashCode()方法显然不适用于这个Student类。因为stu1和stu2这两个对象的属性值是完全一样的,那么从业务角度来说,这两个对象应该就是重复的,那么他们生成的哈希值也应该是一致的,而现在显然并不一致,因此我们需要为这个Student类重写hashCode()方法。
3.2.如何重写hashCode()方法
@Override public int hashCode() { StringBuilder sb = new StringBuilder(); sb.append(num); sb.append(name); char[] charArr = sb.toString().toCharArray(); int hash = 0; for(char c : charArr) { hash = hash * 131 + c; } return hash; }
将所有需要参与计算的属性值都合并成一个字符串,然后转换成一个字符数组:
char[] charArr = sb.toString().toCharArray();
然后遍历这个字符数组进行计算。
4.Java中常用的哈希表
4.1.hashCode()在HashSet和HashMap中的作用
现在以及编写好了hashCode()方法,我们到实际的案例中去使用一下。在Java中常用的哈希表有HashSet和HashMap。
此处我们先以HashSet为例:
import java.util.HashSet; import java.util.Set; public class Student { private String num; private String name; public Student(String num, String name) { this.num = num; this.name = name; } @Override public int hashCode() { StringBuilder sb = new StringBuilder(); sb.append(num); sb.append(name); char[] charArr = sb.toString().toCharArray(); int hash = 0; for(char c : charArr) { hash = hash * 131 + c; } return hash; } public static void main(String[] args) { Student stu1 = new Student("10001", "赤骥"); Student stu2 = new Student("10001", "赤骥"); Student stu3 = new Student("10002", "白义"); Set<Student> students = new HashSet<>(); students.add(stu1); students.add(stu2); students.add(stu3); System.out.println(students.size()); } }
观察这段代码,根据我们之前重写的哈希函数,stu1和stu2应该是在相同位置的,并且他们的值是一样的,那么应该是只能够存放其中一个到这个set中,因此最终打印输出的结果应该是2。
而实际测试的结果为3。这是为什么?
我们来查看一下HashSet的源码:
public boolean add(E e) { return map.put(e, PRESENT)==null; }
我们找到HashSet中的这个add方法,看它是怎么实现的,可以看到这里调用了一个map对象的put方法来存放元素,可以才想到,实际上HashSet真正的实现是另外一个类,这个HashSet只是对其的一个封装,我们找到这个map,看看它到底是哪个类:
private transient HashMap<E,Object> map;
在HashSet前面的属性声明中可以看到这样一行代码,根据这个我们看出来实际上Java中的HashSet是依托于HashMap的实现的。那么接下来到HashMap中去找这个添加元素的方法看看:
public V put(K key, V value) { return putVal(hash(key), key, value, false, true); }
这里真正存放元素的逻辑是在putVal()这个方法中,这里面代码较多就不贴上来了,这里简述一下其中的关键逻辑。它会调用存入元素的hashCode()方法,计算出元素所对应在表中的位置,然后判断这个位置上是否已经有内容了。如果这个位置上以及有了一个元素,那么就调用传入元素的equals()方法与已有的元素进行对比,以此来判断两个元素是否相同,如果不相同,就将这个元素也存入表中。
4.2.equals()方法的作用
也就是说,使用hashCode()方法确定元素在数据结构中存放的位置。而使用equals()来确认当两个元素存放的位置发生冲突时,是应该将两个元素都存入数据结构,还是说只需要存放其中一个。
如果equals()方法判断两个元素是一样的,那么当然只需要存放其中一个既可;但如果equals()方法判断两个对象是不同的,那么当然两个都需要存放到数据结构中。
5.重写equals()方法
重写equals()从逻辑上来说就比较简单了,先看下实例:
@Override public boolean equals(Object obj) { if (this == obj) { return true; } if (obj instanceof Student) { if (((Student) obj).num.equals(this.num) && ((Student) obj).name.equals(this.name)) { return true; } } return false; }
首先判断是否是自己和自己比较,如果是那么肯定是相同的,因为是同一个对象。
然后再逐个比较对象的属性,如果属性值都相同,那么说明就是相同的对象。
在重写了equals()方法之后,重写再进行之前的测试,就可以发现结果是正确的了,在该集合中三个对象只能放入其中的两个,还有一个因为重复而无法放入。
6.String类的hashCode()方法和equals()方法
在前面的一系列介绍过程中,我们都是介绍自己定义的类的hashCode()方法和equals()方法。除了这些自定义的类,我们在平时编写代码过程中经常会用到一个系统的类,并且这个类也经常被用在HashMap中作为key来使用,那就是String类,我们可以看看这个类的hashCode()方法和equals()方法是如何编写的。
6.1.hashCode()方法
public int hashCode() { int h = hash; if (h == 0 && value.length > 0) { char val[] = value; for (int i = 0; i < value.length; i++) { h = 31 * h + val[i]; } hash = h; } return h; }
观察这个hashCode()方法,基本上我们实现哈希函数的思路与这个是一致的。
6.2.equals()方法
public boolean equals(Object anObject) { if (this == anObject) { return true; } if (anObject instanceof String) { String anotherString = (String)anObject; int n = value.length; if (n == anotherString.value.length) { char v1[] = value; char v2[] = anotherString.value; int i = 0; while (n-- != 0) { if (v1[i] != v2[i]) return false; i++; } return true; } } return false; }
观察代码,可以发现对于String类来说,如果要判断两个String的实例相同,需要逐一判断这两个字符串中的字符是否相同。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号