BERT-Of-Theseus: Compressing BERT by Progressive Module Replacing
概述
随着深度学习的发展,许多大型的神经网络被提出并且获得了非常好的效果。尤其在NLP领域,预训练加微调几乎已经成为了一种新的范式。超大的参数量使得这些模型所向披靡,但同样也使得它们需要消耗大量计算资源。
有一系列模型压缩的方法被提出以解决这个问题,其中最著名的就是知识蒸馏。知识蒸馏构建一个大的教师网络和一个较小的学生网络,目标是让学生网络学会模拟教师网络并替换教师网络。但这种方式最终的性能取决于知识蒸馏损失函数的设计,也就是如何教学生网络学会教师网络的行为。
本论文受到哲学领域著名的“Ship of Theseus”实验的启发,提出了一种逐步使用小模块替换BERT中模块的模型压缩方式,取名为Theseus压缩方法。在这种方法中,被替换模块和替换模块被称为前驱模块(predecessor)和后继模块(successor),对应于知识蒸馏方法中的教师网络和学生网络。
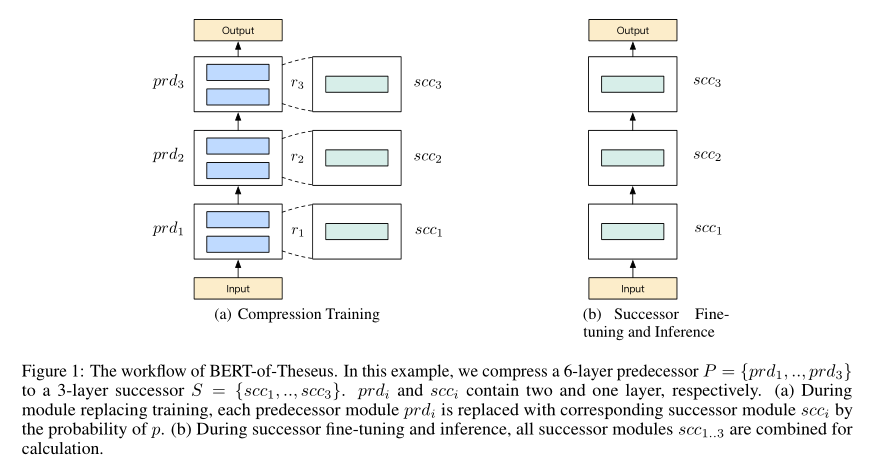
Theseus压缩方法的主要过程如上图所示。首先为每个前驱模块指定一个后继模块,然后在训练阶段以一定概率使用后继模块替换对应的前驱模块。当训练收敛后,再把所有后继模块串起来作为新模型用于预测。这样之后,前驱模块就被压缩成了后继模块。
Theseus压缩方式和知识蒸馏的思想是类似的,但拥有三个优点:1)不需要手动设计额外的知识蒸馏损失函数;2)不使用Transformer特定的特征进行压缩,是一种通用的做法;3)允许前驱模块和后继模块充分交互(具体可以参考方法部分)。
本文论文的创新点可以总结如下:
- 提出了Theseus压缩方法,只使用一个损失函数和一个超参数就能够进行模型压缩。
- 使用Theseus压缩的BERT模型在保证98%性能的基础上比原模型快1.94倍,优于知识蒸馏方法。
方法
Theseus压缩方法的基本思想和知识蒸馏方法类似,但是只需要一个任务特定的损失函数,而且这种方式是一种通用的模型压缩方式。
模块替换
假设前驱模型\(P\)和后继模型\(S\)都含有\(n\)个模块,即\(P=\{prd_1,\dots,prd_n\}\),\(S=\{scc_1,\dots,scc_n\}\),其中\(scc_i\)是用来替换\(prd_i\)的。假设第\(i\)个模块输入为\(y_i\),前驱模型的前向过程可以表示为:
压缩时,对于第\(i+1\)个模块,\(r_{i+1}\)是一个独立的从伯努利分布采样的变量,即以概率\(p\)取值为1,以概率\(1-p\)取值为0:
那么第\(i+1\)个模块的输出变成
其中\(\odot\)表示逐元素乘操作,\(r_{i+1} \in \{0,1\}\)。通过这种方式,前驱模块和后继模块在训练时一起运作。并且由于引入了类似Dropout的随机性,也相当于为训练过程添加了正则化。
训练的损失函数就是任务特定的损失函数,比如分类问题中的交叉熵损失函数:
其中\(x_j\)是训练集的第\(j\)个样本,\(z_j\)是\(x_j\)的标签。\(c\)和\(C\)表示一个类标签和标签集合。在反向传播时,所有前驱模块的权重将会被冻结,只有后继模块参数会被更新。对于前驱模型的嵌入层和输出层除了进行权重冻结外,在训练阶段还会直接当作后继模块。通过这种方式,可以在前驱模块和后继模块之间计算梯度,从而可以进行更深层次的交互。
后继模块微调和推断
当训练收敛时,所有的后继模块将会串起来组成后继模型\(S\):
因为\(scc_i\)比\(prd_i\)小得多,因此整个前驱模型被压缩成了更小的后继模型。然后后继模型将会再次使用损失函数进行微调优化,最后使用微调的后继模型进行推断。
渐进替换策略
尽管设置一个固定的替换概率\(p\)已经可以压缩模型,但本论文还探索了基于课程学习的渐进式替换策略。在这种策略中,替换概率随着时间增加:
其中\(t\)是训练步数,\(k > 0\)是系数,\(b\)是基本的替换概率。非渐进式替换和渐进式替换的替换概率如下图(a),(b)所示:
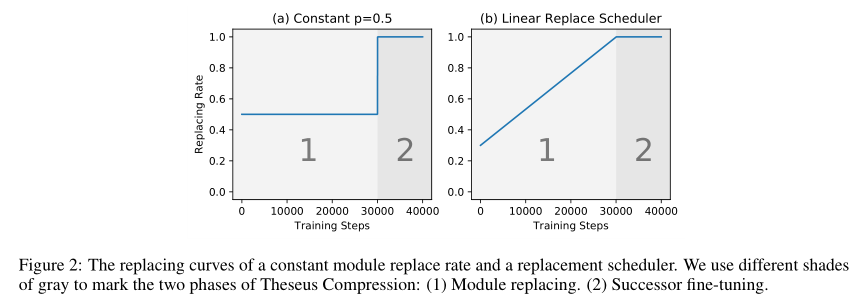
通过渐进式替换策略,之前独立的训练和微调过程可以统一起来,形成一个端到端,从易到难的学习过程。在初始阶段,前驱模块作用仍然较大,使得模型损失能够平滑下降。之后,替换概率增大,逐渐过渡到了后继模块微调阶段。
在压缩的初始阶段,\(\theta(t)<1\),替换模块数量是\(n\cdot p_d\),\(n\)个后继模块的平均学习率为:
其中\(lr\)是初始学习率,\(lr^{'}\)是考虑所有后继模块的等效学习率。因此,当应用渐进替换策略时,同时对学习率使用warm-up机制有助于模型训练。
实验
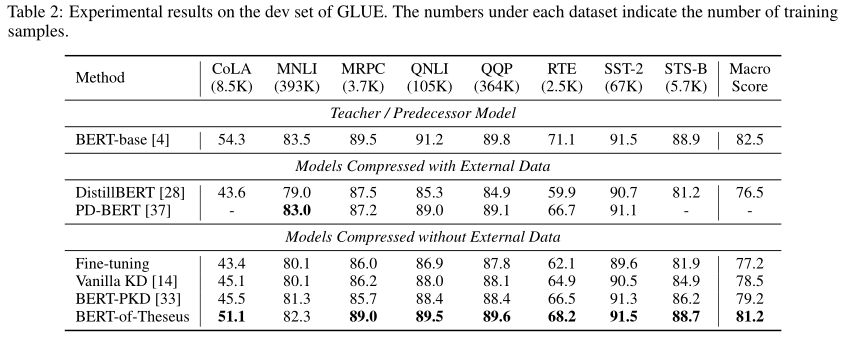
具体的实验细节请参照原文,总之就是模型参数大幅压缩,但是性能却不怎么损失。这里我就放几张实验效果图。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号