A Probabilistic Formulation of Unsupervised Text Style Transfer
概述
文本序列转换(transduction)将给定的文本序列从一个领域域转换为另一个领域,比如机器翻译。但这通常需要平行语料的支撑,因此不需要平行语料的无监督序列转换方法逐渐受到研究者们的关注。
最近的无监督文本风格迁移工作主要有两种做法,一种是基于非生成或者非概率的方法,比如使用生成对抗网络,但容易导致训练不稳定。另一种是直接设计无监督训练的损失,比如回译(backtranslation)损失,但可能的无监督目标的空间非常大,设计此类系统的过程通常是启发式的。
受到一些变分推断技术的启发,该论文直接定义一个生成概率模型,将两个域中的非平行语料库视为部分可观察的平行语料库,并且减弱了独立性假设。
无监督文本风格迁移
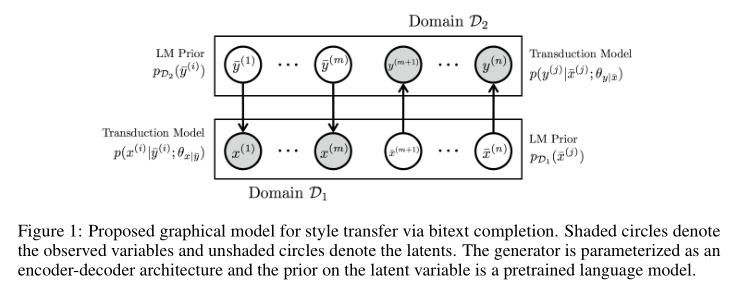
假设\(X=\{x^{(1)}, x^{(2)},\dots,x^{(m)}\}\)是属于领域\(\mathcal{D}_1\)的可观测数据,\(Y=\{y^{(m+1)}, y^{(m+2)},\dots,y^{(n)}\}\)是属于领域\(\mathcal{D}_2\)的可观测数据,相同的上标表示是对应的平行语句。因此,现有数据集中完全没有对应的平行语句。
该文引入隐语句(latent sentence)将语料补充为平行语料库,也就是引入\(\bar{X}=\{\bar{x}^{(m+1)}, \bar{x}^{(m+2)},\dots,\bar{x}^{(n)}\}\)表示\(\mathcal{D}_1\)中不可见的部分,\(\bar{Y}=\{\bar{y}^{(1)}, \bar{y}^{(2)},\dots,\bar{y}^{(m)}\}\)表示\(\mathcal{D}_2\)中不可见的部分。加入这些隐语句之后,就构成了平行语料库,因此模型的目标就变成了基于可观测的\(X,Y\)推断不可观测的\(\bar{X},\bar{Y}\),也就是\(p(\bar{y}|x),p(\bar{x}|y)\)。
模型
模型架构
直接学习\(p(\bar{y}|x),p(\bar{x}|y)\)是非常难的,因为根本就没有平行语料。因此论文转而求解联合概率\(p(X,Y,\bar{X},\bar{Y})\)。模型假设每个可观测语句都是由另一个领域对应的隐语句生成的,也就是上图表示的那样。因此联合概率可以表示为:
其中\(p(x^{(i)}|\bar{y}^{(i)};\theta_{x|\bar{y}}),p(y^{(j)}|\bar{x}^{(j)};\theta_{y|\bar{x}})\)是从\(\mathcal{D}_2\)到\(\mathcal{D}_1\)和从\(\mathcal{D}_1\)到\(\mathcal{D}_2\)的转换模型,\(\theta\)是它们对应的参数。\(p_{\mathcal{D}_1}\)和\(p_{\mathcal{D}_2}\)是两个领域的先验信息。
训练时使用对数概率:
上述推导只是给出了模型框架,论文选用基于注意力机制的Seq2Seq模型作为上述转换模型,并选用循环语言模型建模先验信息以减弱独立性假设。
模型学习
理想情况下,模型应该直接优化上述对数概率进行学习。然而,神经网络模型无法像HMM一样通过动态规划计算概率。因此,该论文采用Amortized变分推断得到对数概率下界(ELBO):

\(q(\bar{y}|x^{(i)};\phi_{\bar{y}|x})\)和\(q(\bar{x}|y^{(i)};\phi_{\bar{x}|y})\)表示对模型真实后验\(p(\bar{y}|x^{(i)};\theta_{x|\bar{y}})\)和\(p(\bar{x}|y^{(i)};\theta_{y|\bar{x}})\)的近似。
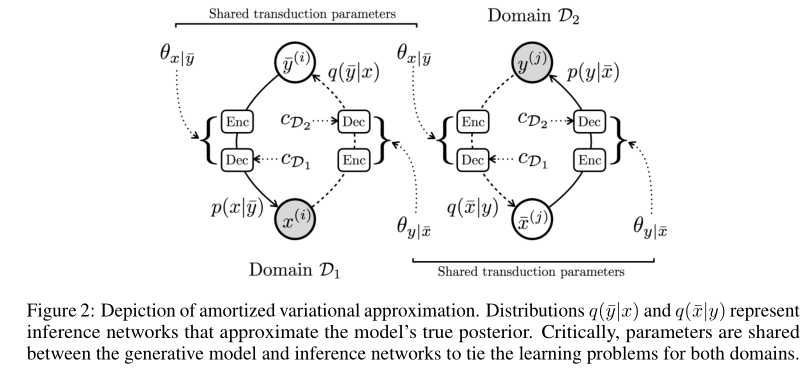
注意到一个域上的近似后验旨在学习反向风格转移分布,这恰好是相反域中生成分布的目标。比如,\(q(\bar{y}|x^{(i)};\phi_{\bar{y}|x})\)和\(p(y|\bar{x}^{(i)};\theta_{y|\bar{x}})\)都是从\(\mathcal{D}_1\)向\(\mathcal{D}_2\)迁移,因此其参数可以共享。也就是\(\phi_{\bar{x}|y}=\theta_{x|\bar{y}}\),\(\phi_{\bar{y}|x}=\theta_{y|\bar{x}}\)。这意味着整体上只需要学习两个翻译网络用来进行两个方向的转换,而不是四个。
此外,受到其它工作使用一个通用Seq2Seq模型在不同语言对之间翻译的启发,该论文进一步使用同一个编码器编码\(x,y\),然后为解码器提供一个领域向量\(c\)来表示迁移方向。如下图所示。
ELBO中的重构项和KL散度项无法直接求梯度,因此该论文又对ELBO进一步近似。由于文本是离散的,因此使用Gumbel-softmax技术进行梯度估计。并且在实验中,使用贪心解码而不记录梯度的方式近似重构项。
另外,由于在刚开始训练时,编解码框架往往难以生成比较好的结果。因此该论文在模型训练初始阶段还加入了自重构(self-reconstruction)损失:
其中,\(e(\cdot)\)和\(p_{dec}\)分别是编码器和解码器分布,\(c_x\)和\(c_y\)分别是\(x,y\)的领域向量,\(\alpha\)在\(k\)个epoch中从1线性递减到0,\(k\)一般为3。
实验
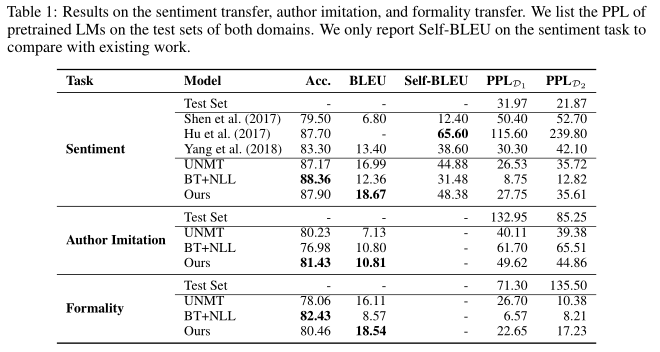
该论文在六个风格迁移任务上进行了实验,分别是:sentiment transfer, word substitution decipherment, formality transfer, author imitation, and related language translation和unsupervised machine translation。下图是实验结果的一部分。
扫码关注公众号


 浙公网安备 33010602011771号
浙公网安备 33010602011771号