Learning from Easy to Complex: Adaptive Multi-curricula Learning for Neural Dialogue Generation
论文信息:地址, [代码](https://github.com/hengyicai/Adaptive Multi-curricula Learning for Dialog)
概述
许多最新的对话生成方法都遵循数据驱动的范式:通过大量查询-响应对训练后,使模型模仿人类对话。因此,数据驱动方法严重依赖于用于训练的问答对。
但是,由于人类对话的主观性和开放性,训练对话的复杂性差异很大。它们中有些容易学习,有些过于复杂,甚至可能还含有噪声。问答对伴随的噪声和不均匀的复杂性阻碍了学习效率和学习效果。
受到人类从易到难进行学习的启发,该文决定引入课程学习(curriculum learning)到对话生成模型中,让模型首先学习简单对话,然后逐渐学习复杂对话。要做到这样,还是有两个问题需要解决:1)如何自动评估对话的复杂性;2)对话复杂性不能只由单属性决定,而是由多属性决定。
总的来说,该文提出了一个基于强化学习范式的自适应多课程学习(multi-curricula learning)框架,可以根据神经对话生成模型的学习状态在不同的学习阶段自动选择不同的课程。
课程合理性(Curriculum Plausibility)
论文从五个方面考虑对话的复杂性,同时对PersonaChat,DailyDialog,OpenSubtitle三个数据集的对话进行了分析。
对话属性
特异性,为了避免产生通用无意义的回复,回复中生词越多则认为特异性越强。对于每个单词\(w\),首先计算其Normalized Inverse Document Frequency(NIDF)值:
其中,\(IDF(w)\)是逆文档频率,\(idf_{\max},idf_{\min}\)是为了做最大最小归一化的变量。最终一条回复的特异性通过其中所有单词的平均NIDF衡量。
重复性,顾名思义就是回复中是否包含很多重复的词,回复\(r\)的重复性定义为:
其中,\(I(\cdot)\)是指示函数。
问句相关性,通过问句和对应答复的余弦相似度来衡量:
其中,\(c,r\)分别是问句和回复,\(sent_{emb}\)通过基于smooth inverse frequency(SIF)加权的词向量平均得到。
连续性,在多轮对话中,当前回复还会触发下一个问句。因此除了计算回复与之前问句的相关性,还应该计算它与后续对话的相关性。
模型置信度,使用模型学习能力区分易学习样本和学习不足样本。论文采用预训练模型下的对话样本的负损失值作为模型置信度度量。
对话分析
依据上面提到的五个属性,从两方面对三个数据集中的对话进行分析。一个方面是利用小提琴图(violin plot)对五个属性进行密度分布分析,另一方面是通过Kendall相关系数分析属性之间的独立性。最终论文得出了一些有趣的结论,这里就直接上图表。

课程对话学习
单课程对话学习
首先以单课程对话学习为例,数据集中所有样本按照一个属性进行排序。在训练时间步\(t\)时,从已排序的训练样本的顶部\(f(t)\)部分中抽取mini-batch用于训练,其中函数\(f(t)\)确定课程的采样范围。该论文受到别的论文启发,将\(f(t)\)设置为:
其中\(c_0 \gt 0\)设置为0.01,\(T\)是课程学习持续步数。开始时,\(t\)比较小,因此模型只从训练集首部取相对简单的样本进行学习。随着\(t\)增大,选取范围扩大,样本难度也增大。\(T\)个batch之后,每个batch将会从整个训练集抽取数据,这已经和其它非课程学习一样了。
自适应多课程学习
论文根据对话的五个属性,将训练集分别排序成五组,也就是所谓的五个不同的学习课程。自适应多课程学习就是要在不同学习阶段自动选择不同课程。下图展示了基于强化学习的整个学习过程,在时间步\(t\),课程策略(cirriculum policy)挑选一个课程进行学习,progressing function定义了在选定课程上的学习过程。
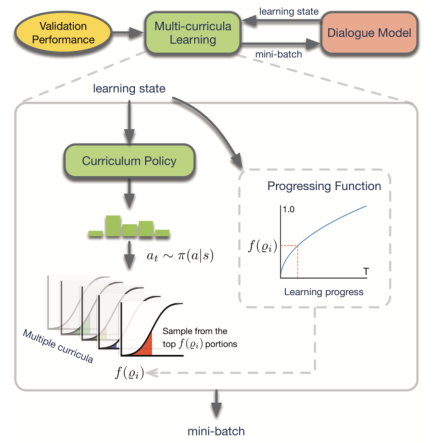
课程的选择依据的是验证集指标。调度策略\(\pi\)与对话模型交互从而获得学习状态\(s\),如果动作\(a_t\)选择出的样本能够改进模型性能,则可以获得正反馈\(m_t\)。模型基于这些样本学习,从而产生新的状态\(s_{t+1}\)。自适应多课程学习框架的目标就是最大化反馈,直到模型收敛。
具体而言,模型的学习状态包括mini-batch序号、历史平均训练损失、当前训练损失、预测概率与验证集度量的间隔,学习状态构成强化学习的状态。为了感知在每个课程\(i\)上的学习进度\(\varrho_i\),总体状态表示为\(\varrho=\{\varrho_0,\varrho_1,\dots,\varrho_4\}\)。在每一步,系统首先通过策略\(\Phi_{\theta}(a|s)\)采样一个动作\(a_t \in \{0,1,2,3,4\}\)用于选择一个课程。然后模型再从选定课程的前\(f(\varrho_i)\)部分采样一个mini-batch用于训练。对话模型每\(\Gamma\)步进行一次验证并根据奖励\(m_{\Gamma}\)更新策略\(\Phi_{\theta}\)。为了加速学习,\(m_{\Gamma}\)被定义为验证集上两个连续指标偏差的比率。即:
其中\(\delta_{\Gamma}\)由13个自动评估指标计算:
其中\(\xi_i^{\Gamma}\)是当前在第\(i\)个评估指标上的分数,所有分数都被归一化到\([0,1]\)。
课程策略通过最大化奖励进行训练,论文使用REINFORCE方法进行优化:
其中\(M(s_t,a_t)\)是状态-动作值函数,\(v_t\)是从策略\(\Phi_{\theta}(a|s)\)的一次执行中获得的奖励\(M(s,a)\)的采样估计。在实现时,\(v_t\)就等于最终的奖励\(m_{\Gamma}\)。
实验
改论文选用了多个对话生成模型进行实验,包括:SEQ2SEQ,CVAE,Transformer,HRED,DialogWAE。同时论文还选取了多个评价指标,包括BLEU,基于嵌入的指标,基于熵的指标等。具体的实验细节参见原文,实验结果如下图。其中a,b,c分别代表三个数据集,实心三角表示论文提出的方法。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号