
python -第七节课之redis操作
数据库分为两种类型,一种是关系型数据库 mysql oracle sqlserver sqlite 这种数据库需要建表 有校验 速度比较慢 现在大数据时代 mysql 数据放到硬盘里
一种是非关系型数据库 nosql 没有sql语句只有key value 没有表没有sql 语句速度比较快,有数据往里面塞就行拉
redis 就是个非关系型数据库 数据存在内存里,一般用来做缓存,每秒支持十万个数据
自动化时候有些数据需要去缓存里面去取
redis默认有十六个数据库
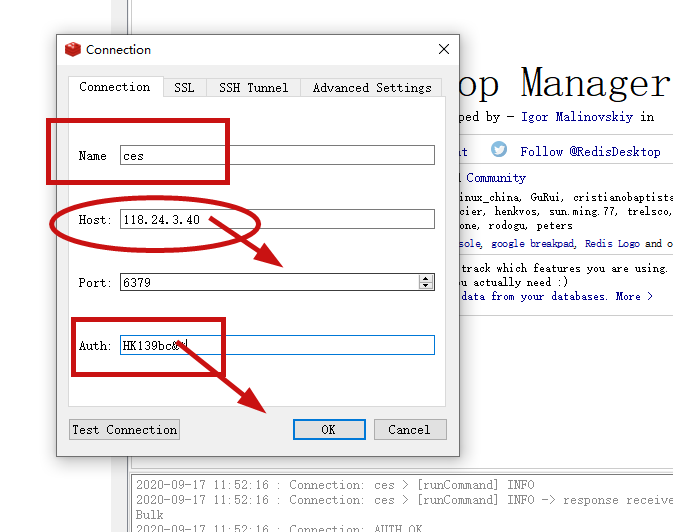
连接成功redis就要进行redis的操作了
当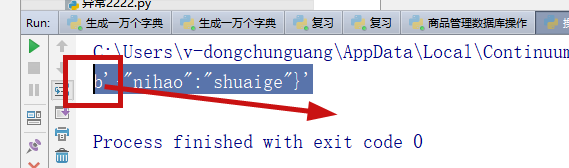
当redis获取数据显示有b的类型时候就是bytes字节类型,需要转化成字符串类型
转换有两种方法
第一种方法
r.set('你好','{"nihao":"shuaige"}')#插数据
data = r.get('你好').decode()#获取数据
第二种方法
r = redis.Redis(host='118.24.3.40',
password='Hxxxx*',
port=6379,
db=14,
decode_responses=True
)
第二种方法在连接时候加decode_responses=True ,这时候就会将bytes类型转化成字符串类型
反转将字符串转成bytes类型也可以这样操作
s='ces你好'
print(s.encode())
redis 也支持设置一个key他的有效期也就是过期时间是多少时间 这是为了设置session用的
redis里面ttl是-1代表永久生效
time=60*60*24
r.set('session','xxxxassdaasd',time)#传一个sessoin 和内容,后面加一个过期时间的操作
时间一到key就会从内存里面消失不在了,以上讲的是redis string类型的操作
r.set('session','xxxxassdaasd',time,5)#传一个sessoin 和内容,后面加一个参数代表过期时间的操作,如果再传一个参数就是过期时间
#到了时间之后key就会在内存里消失
总结string方法的增删改查
r.set('矿泉水','{"price":111,"count":11}') 增加
r.delete('矿泉水') 删除
r.set('矿泉水','xxxx')修改
data = r.get('你好').decode()#查
r.set('session','xxxxassdaasd',time,5)设置过期时间
#传一个sessoin 和内容,后面加一个过期时间的操作,如果再传一个参数就是过期时间
下面讲哈希类型的增删改查
r.hset('stude','fd','{"ces":"dsass"}')#哈希类型的增加
r.hdel('stude')删除操作
r.delete('stude')#删除操作
r.hset()修改操作
r.expire('stude',10)#指定某个key的过期时间
r.hget('stude')获取数据
set 是k/v 格式
hset是 name k v格式
set和hset不能改k改key 需要rename 修改 都能改value字典形式的key和value

print(r.hget('stude','fd'))#获取大key里面的单个key
print(r.hgetall('stude'))#获取大key里面的所有内容
获取后的也是bytes类型
实际场景
如果金融产品需要分红,需要把每天的数据推送过来,放到redis里面,但是redis这个机子要被回收了,回收了要把这些数据存起来,要解析redis存到mysql里面
这个时候要怎么把数据处理放到表里呢
第一步redis里面是一个字典,是bytes类型,key和value都是bytes类型要先转成字典
print(r.hget('stude','fd'))#获取大key里面的单个key
print(r.hgetall('stude'))#获取大key里面的所有内容
d=r.hgetall('stude')
new={}#将返回的内容转换成字典
for k,v in d.items():
new[k.decode()]=v.decode()
print(new)
第二种方法
r = redis.Redis(host='118.24.3.40',
password='HK139bc&*',
port=6379,
db=14,
decode_responses=True
)
默认就是转换了,返回的数据就不是bytes类型了就自动转换成字符串类型了
#获取数据库当前多少key
print(r.keys())
print(r.keys('s*'))#获取s开头相关的key
print(r.type('stude'))#获取key的类型
# print(r.flushdb())#清空当前数据库里面的所有Key
redis的数据迁移之管道操作
#建立管道意思把这些操作记录下来,会把你的操作统一执行,内存只交互一次,不用管道每次都会交互一次
# p=r.pipeline()#建立管道
# p.exists('stude')#检查key是否存在
# p.hgetall('stude')
# s=p.execute()#执行管道,返回每一个命令的结果,返回一个List这个list是每个命令执行的结果
# print(s)
# print(r.exists('stude'))#检查有几个key
#建立管道意思把这些操作记录下来,会把你的操作统一执行,内存只交互一次,不用管道每次都会交互一次
start=time.time()#使用set的时间
for i in range(1000):
r.set('key%s'%i,'%s'%i)
print(time.time()-start)
start=time.time() #使用管道的时间
p=r.pipeline()
for i in range(1000):
p.set('key%s'%i,'%s'%i)
p.execute()#执行管道,返回每一个命令的结果,返回一个List这个list是每个命令执行的结果
print(time.time()-start)
结果是管道的时候比平时set的时间快
r.set('ces:ceses','nihao')#如果加多层文件
r.hset('cess:cesesss','zxx','121')#哈希必须是三个类型,字符串可以是两个类型
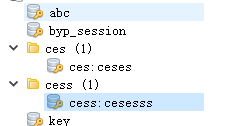
如果你a服务器装了一个redis,这时候a服务器的机子要迁移要将a服务器的数据迁移到b服务器如何操作呢?
#从a里判断所有key判断是哈希还是字符串类型
p=r1.pipeline()#创建管道
for k in r.keys():#循环a里面的所有key
key_type=r.type(k)#判断类型
if key_type=='string':#字符串类型的操作,写进去通过管道
value=r.get(k)
p.set(k,value)
elif key_type=='hash':
hash_data=r.hgetall(k)#获取哈希类型的key key value
for filed,data in hash_data.items(): #循环哈希的小字典
p.hset(k,filed,data)#写进去p2
p.execute()#执行管道,一起往里塞

