

传输层协议
1.不同主机进程间通信
数据包只需要具备了网络层的IP地址,就能被路由到目标主机上实现主机与主机的通信,但是这个数据包此时也仅能找到目标主机,却不知道应该交给目标主机上的哪个进程去处理。换句话说,网络层只能保证主机与主机间的通信,不能提供主机间某进程和某进程的通信。
在网络层之上还提供了传输层。当数据从OSI上层传递到传输层后,在传输层将为数据封装TCP或UDP首部,其中会包括源端口和目标端口,源端口和目标端口可分别用来确定源进程和目标进程。如此一来,数据包传输到目标主机上之后,目标主机解封到TCP或UDP的首部之后,就能看到目标端口,于是可以将该数据包交付给监听在此端口上的对应进程。于是,就实现了不同主机上进程与进程的通信。
2.理解UDP和TCP通信的特点
不同主机上进程与进程之间的数据传输,根据数据的大小可分为两种可能的情形:
1.待发送数据较短,单个数据包即可发送完成。
2.待发送数据较长,需要划分成多个数据包发送。
这两种不同的数据传输情形,正应对于UDP和TCP两种协议:一个数据包能完成发送的使用UDP协议,分包发送的使用TCP协议。但注意,这里的划分方式并不严谨,UDP发送的数据并不一定短(不管有多长数据,UDP都会整体原封不动地当一个包传输),TCP发送的数据也并不一定长,之所以如此划分是为了稍后方便解释这两个协议的特性。
如果采用分包传输的机制,也就是TCP协议,就需要将待发送的数据划分成多个数据包来发送,一边划分一边放入TCP套接字的Send Buffer,同时还会对划分的每个数据包进行编号,以便校验数据包的先后顺序,同时还能根据序号检测是否需要丢失重传数据包。Send Buffer中有数据包之后,就可以进入下一层网络层,然后通过网络发送给目标主机。所以采用TCP通信来传输数据时,就像是水流一样,数据包从源端的应用层到目标端,中间的任何一个层次都可能已经有了数据。所以,TCP数据传输是数据流模式。
因为有很多数据包要发送,所以在划分数据包之前就需要在两端主机之间建立好一个TCP连接,以便让后续所有的数据包都通过这个连接来传输。所以,TCP通信是面向连接的。
既然是面向连接的,那么源端和目标端都可以借此连接来发送数据,所以TCP通信是双向的,或者说是全双工的。既然是双向通信,那么连接的每一端都需要有发送者(Sender)和接收者(Receiver),一端的发送者发送的数据被另一端的接收者接收。
为了保证每一端的收、发都互不影响,每端都采用两个TCP套接字的缓存:读缓存和写缓存,也称为发送缓存(Send Buffer)或接收缓存(Recv Buffer)。某端发送数据时,将划分的数据包放入Send Buffer,通过网络发送给目标主机后,放入对方的Recv Buffer,另一端发送数据也一样如此。
有了连接,双方就可以根据这个连接来做出一些控制,协商一些连接的属性,比如一个包最大多少个字节。而且,发送方可以根据连接来判断是否比较阻塞(拥塞)或者不太稳定从而调整发送速度,这是拥塞控制。接收方如果发现接收速度或数据处理速度跟不上对方的发送速度,可以通知对方降低发送速度甚至短暂停止发送。
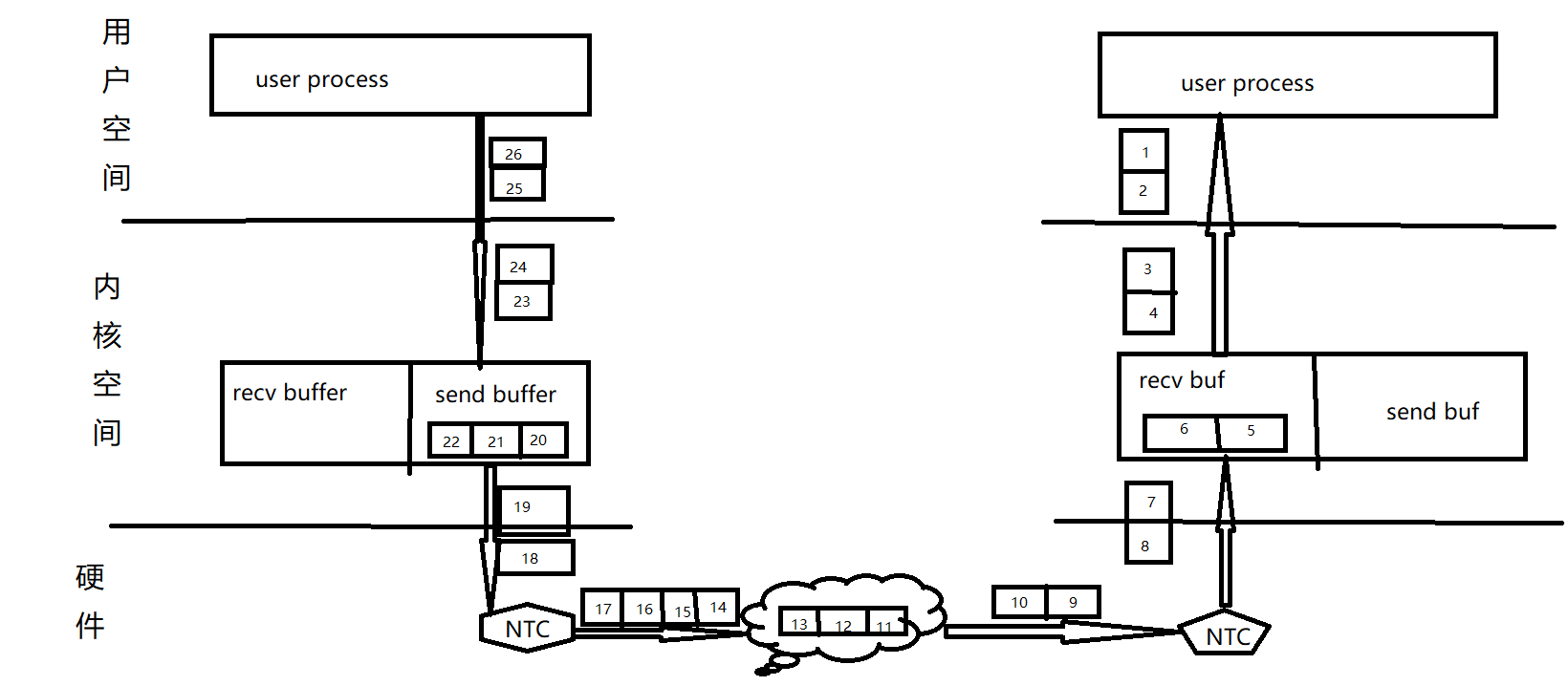
上图展示了基于TCP连接进行通信时的大致过程,图中只考虑了分包的数据部分(即小方块),没有考虑各层次封装的首部。图中非常形象地展现了TCP分包按序传输和流式传输的特性。
如果待发送数据只想用一个数据包发送,那么采用UDP传输协议。UDP传输时不会对数据进行分包,当然也就不需要编号,因为只有一个包,只需发送一次,所以UDP不需要建立连接。因为没有连接,所以只能单向传输,且无法很好地判断数据包是否到达目标。因为没有连接,也无法像TCP一样可以借此来做拥塞控制。但也正因为UDP不需要连接,不需要分包,所以UDP传输效率比TCP的要高,且传输期间占用的系统资源也要远小于TCP。
3.UDP协议
UDP(User Datagram Protocol)是用户数据报协议,是OSI传输层协议。它只是比IP数据包多提供了很少一些功能,比如添加端口标识不同的应用层协议、差错检测等。
UDP的主要特点包括:
(1).UDP是无法连接的,即发送数据之前不需要和对方建立好连接(所以也没有关闭连接的过程),因此效率比较高。
(2).UDP只能尽量保证数据可到达对方,但无法保证可靠的交付。主要还是因为没有建立连接,数据丢失后无法重传。
(3).UDP是面向数据报的。当应用层采用UDP协议时,UDP将对数据添加首部后直接给网络层,它不会合并也不会拆分,而是应用层给多少数据,UDP就包装多少数据,包装后的数据称为数据报。传输时以数据报为单位,一次传输一个报文。接收到UDP报文时,UDP解封后直接将整个数据交给应用层。所以,对于使用UDP协议的程序,必须选择大小合适的报文,如果报文太大,则在IP层会对其进行分片,这会导致IP层的效率降低。
(4).UDP首部开销小,只有8字节,而TCP的首部有20字节,相比TCP而言,UDP的效率要更高一些。
(5).UDP没有拥塞控制,在网络出现拥塞的时候,源主机不会因此而降低发送速率,所以UDP的实时性比较好。所以,对于允许丢失一些数据,但又要求高实时性的场景,UDP更为适合。
(6).差错校验功能有限,在校验后发现不一致,将直接丢弃数据报。
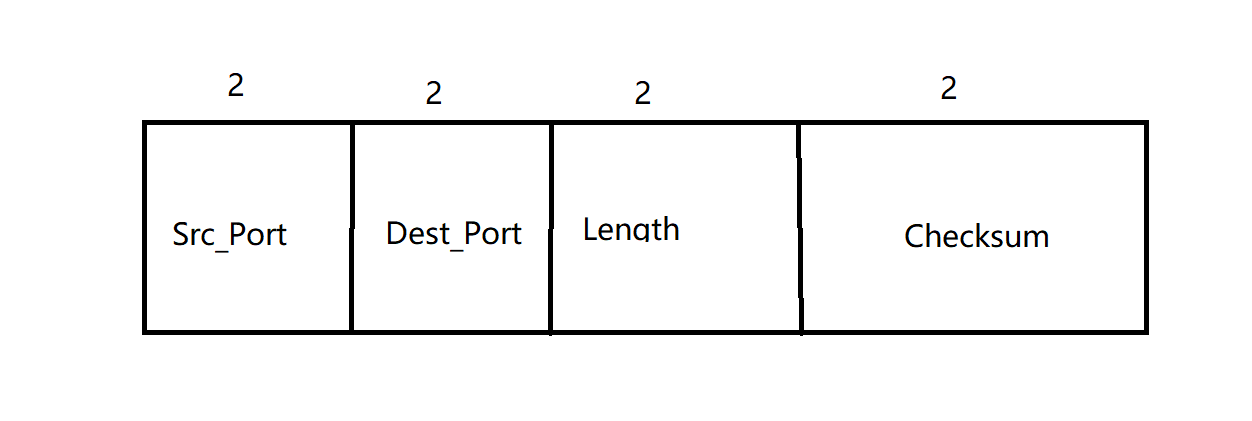
UDP数据报包含两部分:数据部分和首部部分。首部部分非常简单,共8字节4字段,每个字段2字节。如下图所示:
4.TCP协议
TCP协议是个非常复杂的协议,理解这个协议的前提条件就是理解它首部的各个字段的含义。
5.TCP协议的首部
下图就是TCP协议的首部、TCP数据以及它们在网络层被封装后的示意图。这里重点关注的是TCP首部部分。
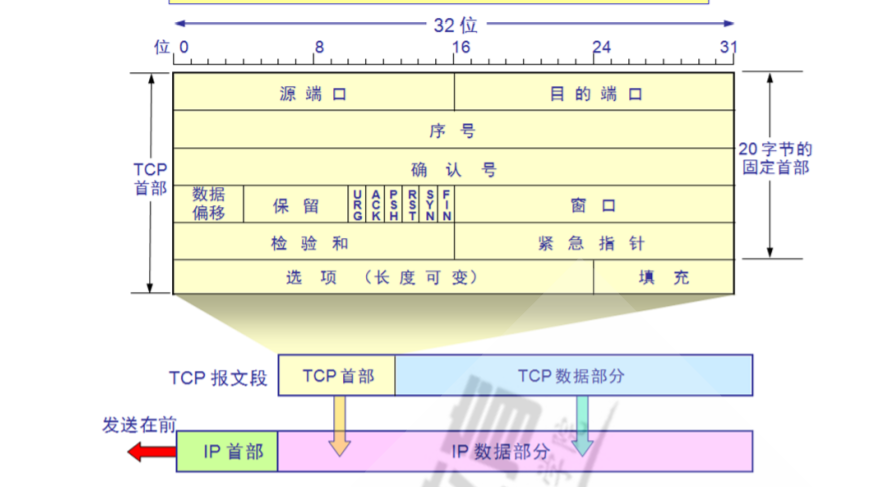
TCP协议首部前20个字节是固定的一些字段,20字节之后有一段可选字段也称为选项,长度可变。
1.前4个字节是源端口字段和目标端口字段,每个字段两字节。
2.序号(seq)占用4字节。
因为序号是4字节,所以它能编号的范围是[0,2^32-1],即4294967296。当序号增加到2^32-1之后,下一个序号将又回到0开始编号。编号的方式是每个分包的起始字节号,例如,第一次要发送的数据分包编号是seq=1,如果这次发送的数据的长度是len=10字节,则下个分包的编号将是seq=1,以此类推。
3.确认号(ack)占用4字节。它是等待发送方发送下个数据包的起始字节。
接收方收到分包(可能是一个也可能是多个分包)之后,将会给发送方发送一个确认ack包,用于告知发送方下一个要发送的分包将从此序号开始。例如,接收方收到了前100字节,此时如果要发送确认包,则ack=101。另一方面,当发送确认包的ack=101,这已经表明了接收方已经明确接收到了前100字节。
接收方接收到的数据首先是放在Recv Buffer中的,从缓存中接收时将根据分包中的序号进行排序,组合成连续的字节数据。
4.数据偏移占4个bit位,它用来确认TCP数据段距离首部多长,换句话说,可以根据该字段知道TCP的数据部分起始位置。之所以有这个字段,主要是因为TCP首部前20个字节之后还有可选字段,这个可选字段的长度是不确定的。由于数据偏移量最大是4比特位,所以它能描述的范围是0-15,所以最大值是60字节,去掉固定的20字节,也就说明可选字段最多只能是40字节。
5.保留字段,目前还未定义功能的字段,占用6个比特位。
6.URG位,占用一个比特位,其值为0或1,URG=1表示这是紧急数据,需要尽快发送,而不是按照原来的编号顺序传输。
7.ACK位,占用1个比特位,其值为0或1,ACK=1时才表明前面的ack确认号字段才是有效的,当ACK=0时,确认号字段无效。TCP要求,连接建立完成之后,ACK字段总是设置为1。
8.PSH位,占用1个比特位,其值为0或1。由于接收方有Recv Buffer,有时候可能会等待填充一些数据包之后才会从Recv Buffer中去接收数据。如果发送方想要让对方尽快从Recv Buffer中接收数据,可以发送一个PSH=1的包出去,这样接收方接收到这个PSH=1的信号之后,就会立即从Recv Buffer中将数据向上推给应用进程。实际情况中,PSH位用的非常少。
9.RST位,占用1个比特位,其值为0或1。当RST=1时,表明需要重新建立TCP连接,所以这会导致先释放连接。当RST=1时,这可能是因为连接出了差错,或者其他一些原因。
10.SYN位,占用一个比特位,其值为0或1。用于同步编号。当SYN=1而ACK=0时,说明连接尚未建立,所以这是一个TCP的连接请求,如果对方接收连接请求,则回复将设置SYN=1且ACK=1。SYN会在连接建立后设置为0,所以SYN=1表示这是TCP连接建立前的请求或响应包,此时结合ACK即可判断是请求还是响应。
11.FIN位(finish),占用一个比特位,其值为0或1。当FIN=1时,表明请求释放TCP连接。
12.窗口,2字节,所以其值范围为[0,2^16-1],即最大值为65535。窗口值用于告知对方:从本TCP报文中的确认号开始,允许发送方发送发送多少数据。这个字段的意义是为了保证接收速度较慢时,让发送速度也缓下来,否则接收方的Recv Buffer存放不下。接收方可能随时会动态调整窗口值,从而让发送方也能动态按需发送一定量的数据。有些地方也将这种控制称为流量控制。
13.校验和,2字节。该字段会对TCP首部和TCP数据部分都做校验。
14.紧急指针,2字节。紧急指针只有在URG位设置为1时才有意义,该字段指出紧急数据的字节数(紧急数据之后就是普通数据)。
15.可选字段。这部分是固定20字节之后的,长度可变,根据前面数据偏移字段的分析,可选字段的最大长度是40字节。
根据网络层IP数据包最大长度是1500字节,IP首部固定部分20字节,TCP首部固定20字节,那么剩下的就是TCP数据部分,它最大是1460个字节。
6.可靠传输:丢失重传和窗口滑动
基于TCP连接传输数据是可靠的,它保证数据不丢失,且能按照正确的顺序被对方接收。这里面涉及到一些比较重要的机制,这里简单描述下。
首先假设只有一个数据包需要传输,如果这个包没有丢失,也没有出现差错,那么一切都正常,但如果传输的这个包丢失了或者出现了差错,那么就要求发送方重传这个包。
为了能够重传这个包,发送方需要遵守一些简单的规则:
1.保留这个包不删除,以便出现问题时直接重传。
2.发送这个包之后停止,等待接收方回复确认包。
3.设置一个定时器,在指定时间内如果没有收到接收方的恢复,则认为包丢失了,于是重传该包。
4.如果收到确认包之后,开始传输下一个包。
遵守这几个规则可以保证基于TCP连接传输数据是可靠的,不会丢失任何数据。
于是,改进这种方案,不是一次发送一个包就等待,而是一次性发多个包,然后进入等待。现在规则改进:
1.一次发送4个包(这是假设的值),发送后保留这4个包,以便出现问题时重传。
2.发送这4个包之后停止,等待接收方恢复确认包。
3.设置一个定时器,在指定时间内没有收到确认,则重传4个包。
4.接收方收到包之后,如果4个包都一切正常,则回复,让发送方发送后续数据包。
5.如果接收方发现中间第3个包出现问题,则发送确认,确认号是第3个包的起始字节。也就是说,接收方只就收前两个包,后两个包需要重传。
6.发送方根据接收到的确认号,知道要重传第三个包,于是将保留下来的4个包中的前两个包踢出去,并加入两个新的包,于是本次再次发送4个包。本次发送的4个包中,前两个是重传包,后两个是新包。
7.接收方收到新的4个包后。如果一切正常,则确认给发送方。
根据这种规则传输数据,比之前每发送一个包就停下来等待,效率要高很多。而且,一次发多少个包是可以更改的,这取决于窗口的大小。假如一个包的大小是100字节,窗口大小是400字节,那么一次就能发送4个包,如果窗口大小是1000字节,一次就能发送10个包。每次发送一个窗口中的包之后,如果接收到接收方的确认信息,那么窗口中的所有包都将滑出窗口,并存放新的数据包。如果中间某个包出错了,则只滑出那部分已确认接收的包,并放入对应个数的新数据包。
TCP连接建立时,接收方会和发送方协商窗口设置为多大,这样发送方就会根据这个窗口大小决定一次发送多少个包。并且,接收方可以随时动态调整窗口大小,从而限制发送方发送包的速度,实现流量的控制。
这种窗口滑动的模式虽然已经足够高效了,但是仍有不足。比如窗口大小是4个包的大小,接收方发现第2个包出错,会导致发送方重传这4个包中的3个,效率较低。更佳的处理方式是只重传那个出错的包。这就是改进的传输模式,实现方式是在接收方回复确认信息给发送方时,在其回复包的TCP首部可选字段中加入一个选项,来指明已经接收到字节的起始和接收位置。
7.建立TCP连接:三次握手
TCP在传输数据之前,首先需要建立好TCP连接,后续所有数据都基于这个已建立的连接来传输。
建立TCP连接的过程通常被描述为三次握手。如下图:
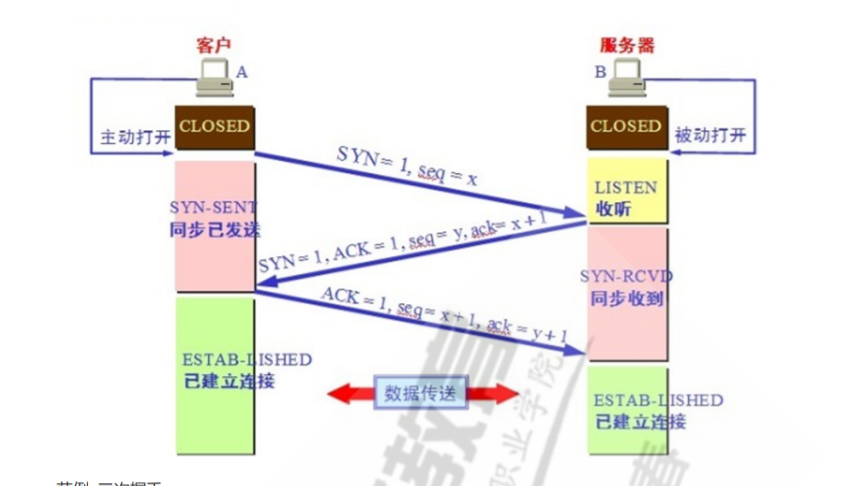
首先服务端B的服务进程已经监听在某个端口上,监听之后就可以一直等带客户端请求建立TCP连接。
1.当客户端A想要和B建立TCP连接时,首先会发送一个连接请求报文给服务端B。在这个请求报文中,TCP首部中的SYN位设置为1,ACK位设置为0,假设此时的序号是X(序号不一定是1),即SYN=1、ACK=0、seq=x。这个包也常称为SYN包,当客户端发送完SYN包后,它将进入SYN_SENT状态。
2.当B收到该报文后,发现其中的SYN=1、ACK=0,便知道这是一个TCP连接的请求包。如果B确认与A建立连接,那么B需要回复A。回复时,SYN=1、ACK=1、ack=x+1、seq=y。注意区分这里的ACK和ack,ACK表示的是占用一个比特位的ACK设置位,ack是确认号。这个包通常被称为ACK包,当服务端发送完ACK包之后,它将进入SYN_RECV状态。
3.当A收到B的回复报文后,发现里面的SYN=1、ACK=1,于是也会向B回复一个ACK包,回复时,SYN=0、ACK=1、seq=x+1、ack=y+1。这里的SYN=0、ACK=1表示这不是建立连接的请求包,而是回复包。A发送完之后,就进入ESTABLSHED状态,表示连接在A这端已经建立完成了。
4.B最终收到A的ACK包之后,也将进入ESTABLISHED状态。到此,TCP连接就建立完成。
需注意的是,B回复A的时候,也发送了一个SYN=1的包,相当于也是在请求A去建立TCP连接,所以A最后回复了一个ACK包。
另一方面,A最后回复一个ACK包是为了避免无效连接请求再次重生的问题。因为A首先发送SYN包之后,可能因为某些原因导致很长一段时间都没有被B接收到,于是A在超时之后会重传这个包,于是网络上就有了两个SYN包。假设B收到了其中一个SYN包,并就这个SYN包和B建立了连接。当数据传输完成,TCP连接释放之后,如果此时另一个SYN包突然被B接收到,B会认为A又在请求建立TCP连接,如果B在回复之后就立即建立TCP连接而不等待A的回复,那么基于这个SYN包就会再次建立一个TCP连接,但这个连接并不是A要想建立的。而如果要求A也发送ACK包就可以避免这个问题,因为A知道这不是它想要建立的连接。
注意:广泛使用的三次握手的概念并不合理,RFC文档中建立TCP连接的过程称为three way handshark,按字面翻译,它应该被称为三路握手,对应于建立TCP连接过程中的三个包传输,应该被称为三包握手或三报文握手,而不应该是三次握手。三包握手是只有一次握手,但这次握手过程传输了三个包,从handshark是单数角度上也可以确定它只有一次握手。
8.断开TCP连接:四次挥手
建立TCP连接需要三次握手过程,在TCP连接断开(或释放)的时候则需要四次挥手的过程。
如下图是四次挥手过程的示意图。
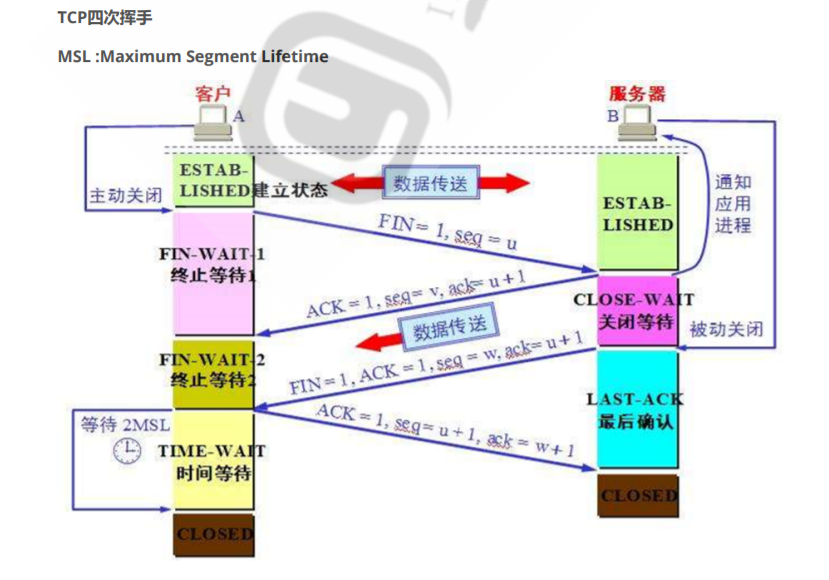
首先两端在开始释放TCP连接之前,都已经处于ESTABLISHED状态,假设现在在A端开始请求释放连接(当然,B端也可以主动释放连接)。
1.A首先发送一个TCP首部中FIN位置为1的包给B端,假设此时序号是u,即seq=u。FIN=1意味着这是一个请求关闭TCP连接的数据包,这种包也称为FIN包。当发送FIN包之后,A将从ESTABLISHED状态转变为FIN-WAIT-1状态。
2.B收到FIN包之后,发现其中FIN=1,知道A端请求关闭,于是发一个回复包给A。回复时,设置ACK=1,ack=u+1,同时还设置序号seq=v(假设B现在发送到的数据序号是v),发送完这个回复包之后,服务端进入CLOSE-WAIT状态。到了这个阶段,A(主动请求关闭方)到B(被动方)方向的连接就已经释放了,A不能再发送传输数据给B,但是B到A方向的连接还没有关闭,它可以继续发送数据给A,A也会接收,因为在这个阶段只有一个方向的连接被释放,所以close-wait状态也称为半关闭(half-close)状态。
3.当A收到B的ACK包之后,它将进入FIN-WAIT-2,等待B发起从B到A方向的连接关闭请求。
4.当B确认已经没有数据发送给A后,B开始主动关闭从B到A方向的TCP连接,这时会发送一个FIN包,同时ACK设置为1,ack仍然保持不变,是u+1,而seq则为一个新值w,因为进入CLOSE-WAIT之后,B可能还发送了一些数据。B发送完这个FIN+ACK包之后,将进入LAST-ACK(最后确认)状态。
5.当A收到B的FIN+ACK包之后,需要对B发送的关闭请求做出回复。回复时,ACK=1,seq=u+1不变,ack=w+1。当发送完这个ACK包之后,A不会立即就关闭,而是进入TIME-WAIT阶段等待一段时间(2倍的MSL时长)。
6.当B收到A的回复ACK包之后,意味着B到A方向的连接关闭已经确认了,于是B端关闭连接。
7.当A等待了2MSL的时长之后,将真正关闭连接。
在RFC793中,建议MSL值设置为2分钟,但是对于现在的网络来讲,2分钟的时间太长了,这意味着A在回复ACK包之后还要等待4分钟才真正关闭连接。实际上,是允许不同的TCP协议设置不同的MSL值的。在这里,不管MSL的值具体为多少比较合适,需要关注的是为什么A在回复ACK之后不直接关闭而是需要等待2MSL时长才关闭。
这主要是为了保证A发送的最后一个ACK回复包能够被B收到。如果不等待2MSL而是直接关闭连接,那么B可能在超时时间内无法收到回复包,于是重传FIN+ACK包给A,但是A已经关闭了,不可能再接收到重传的包,于是最终B按照非正常状态退出连接。如果A等待一段时间,则可以保证在B重传FIN+ACK之后,A能够重新回复一个ACK包给B(A此时重置定时器为2MSL),使得B能够正常关闭连接。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
· 25岁的心里话