XDocument读取xml的所有元素以及XPath语法[转]
http://www.cnblogs.com/xxyishutong/archive/2013/09/17/3326375.html

<?xml version="1.0" encoding="utf-8" ?> <bookstore> <book category="COOKING"> <title lang="en">Everyday Italian</title> <author>Giada De Laurentiis</author> <year>2005</year> <price>30.00</price> </book> <book category="CHILDREN"> <title lang="en">Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> </book> <book category="WEB"> <title lang="en">XQuery Kick Start</title> <author>James McGovern</author> <author>Per Bothner</author> <author>Kurt Cagle</author> <author>James Linn</author> <author>Vaidyanathan Nagarajan</author> <year>2003</year> <price>49.99</price> </book> <book category="WEB"> <title lang="en">Learning XML</title> <author>Erik T. Ray</author> <year>2003</year> <price>39.95</price> </book> </bookstore>
以上是BookStore.xml文件
接着开始处理
XDocument xdoc = XDocument.Load("../../BookStore.xml");//加载xml文件 XElement xroot = xdoc.Root;//获取根节点 Console.WriteLine(xroot.Name);//输出根节点的名字 IEnumerable<XElement> elements = xroot.Elements();//获得根节点下的元素集合 foreach (XElement item in elements) {
Console.WriteLine(item.Name); DiGuiNode(item); //递归获得此元素下的子元素 }
private static void DiGuiNode(XElement xroot) { if (xroot!=null) { foreach (var item in xroot.Elements()) { Console.WriteLine(item.Name);//获得元素名 Console.WriteLine(item.Value);//获得元素的基本值 DiGuiNode(item); } } }
运行结果: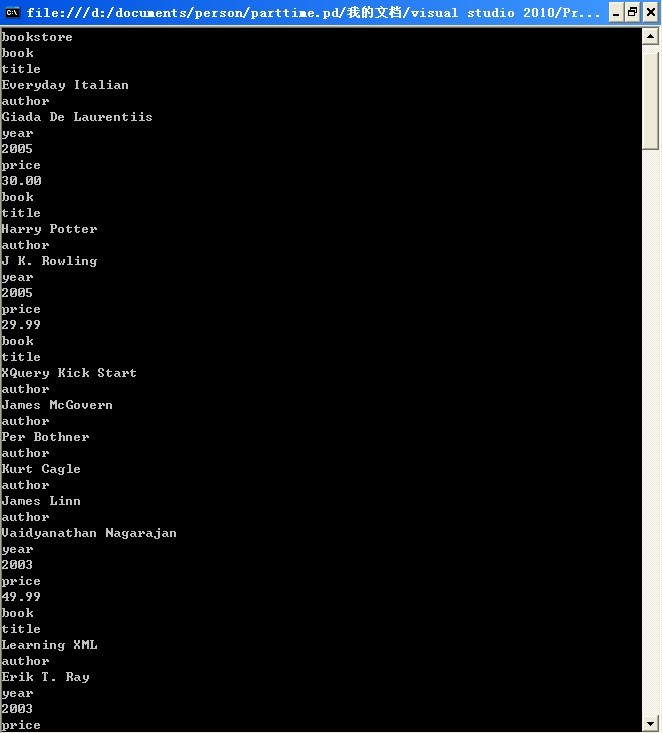
2.XPath语法:
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有直接子nodename节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
2.1
XDocument xdoc = XDocument.Load("../../BookStore.xml");//加载xml文件 XElement xroot = xdoc.Root;//获取根节点 Console.WriteLine(xroot.Name);//输出根节点的名字 IEnumerable<XElement> elements = xroot.XPathSelectElements("book");//找根节点的直接book子节点 foreach (XElement item in elements) { Console.WriteLine(item.Name); }
运行结果: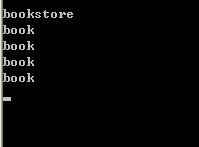
2.2 假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径!
XDocument xdoc = XDocument.Load("../../BookStore.xml");//加载xml文件 XElement xroot = xdoc.Root;//获取根节点 IEnumerable<XElement> elements = xroot.XPathSelectElements("/bookstore/book/price");//假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! foreach (XElement item in elements) { Console.WriteLine(item.Name); }
运行结果:
2.3 // 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。
XDocument xdoc = XDocument.Load("../../BookStore.xml");//加载xml文件 XElement xroot = xdoc.Root;//获取根节点 Console.WriteLine(xroot.Name);//输出根节点的名字 IEnumerable<XElement> elements = xroot.XPathSelectElements("//author"); foreach (XElement item in elements) { Console.WriteLine(item.Name); }
运行结果:
2.4 .表示选取当前节点。
XDocument xdoc = XDocument.Load("../../BookStore.xml");//加载xml文件 XElement xroot = xdoc.Root;//获取根节点 Console.WriteLine(xroot.Name);//输出根节点的名字 IEnumerable<XElement> elements = xroot.XPathSelectElements(".");//.表示当前节点,此处表示根节点 foreach (XElement item in elements) { Console.WriteLine(item.Name); }
运行结果: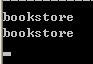
2.5 ..表示选取当前节点的父节点。
XDocument xdoc = XDocument.Load("../../BookStore.xml");//加载xml文件 XElement xroot = xdoc.Root;//获取根节点 Console.WriteLine(xroot.Name);//输出根节点的名字 IEnumerable<XElement> elements = xroot.XPathSelectElements("book");//找根节点的直接book子节点 foreach (XElement item in elements) { XElement element = item.XPathSelectElement("..");//..表示选取当前节点的父节点,此处获得的是item表示book节点,所以element就表示bookstore节点 Console.WriteLine(element.Name); }
运行结果:
2.6 @表示选取带此属性的元素
XDocument xdoc = XDocument.Load("../../BookStore.xml");//加载xml文件 XElement xroot = xdoc.Root;//获取根节点 Console.WriteLine(xroot.Name);//输出根节点的名字 IEnumerable<XElement> elements = xroot.XPathSelectElements("//book[@category='WEB']");//表示选择出含有值为WEB的category属性的book元素 foreach (XElement item in elements) { Console.WriteLine(item.Name); }
运行结果:
谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
谓语被嵌在方括号中。
实例
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()<3] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang='eng'] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素节点。 |
| @* | 匹配任何属性节点。 |
| node() | 匹配任何类型的节点。 |
实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/* | 选取 bookstore 元素的所有子元素。 |
| //* | 选取文档中的所有元素。 |
| //title[@*] | 选取所有带有属性的 title 元素。 |
选取若干路径
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| //book/title | //book/price | 选取 book 元素的所有 title 和 price 元素。 |
| //title | //price | 选取文档中的所有 title 和 price 元素。 |
| /bookstore/book/title | //price | 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 |
以上表格信息摘自http://www.w3school.com.cn/xpath/xpath_syntax.asp

 浙公网安备 33010602011771号
浙公网安备 33010602011771号