
python Scrapy 从零开始学习笔记(一)
 python Scrapy 从零开始学习笔记(一)初识 Scrapy 框架,安装及目录的介绍
python Scrapy 从零开始学习笔记(一)初识 Scrapy 框架,安装及目录的介绍
在之前我做了一个系列的关于 python 爬虫的文章,传送门:https://www.cnblogs.com/weijiutao/p/10735455.html,并写了几个爬取相关网站并提取有效信息的案例:https://www.cnblogs.com/weijiutao/p/10614694.html 等,从本章开始本人将继续深入学习 python 爬虫,主要是基于 Scrapy 库展开,特此记录,与君共勉!
Scrapy 官方网址:https://docs.scrapy.org/en/latest/
Scrapy 中文网址:https://scrapy-chs.readthedocs.io/zh_CN/latest/index.html
Scrapy 框架
-
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
-
框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
-
Scrapy 使用了 Twisted
['twɪstɪd](其主要对手是Tornado)异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
Scrapy架构图(绿线是数据流向):

-
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。 -
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。 -
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理, -
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器), -
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方. -
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。 -
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
以上是 Scrapy 的架构图,从流程上看还是很清晰的,我就只简单的说一下,首先从红色方框的 Spider 开始,通过引擎发送给调度器任务,再将请求任务交给下载器并处理完后返回结果给 Spider,最后将结果交给关到来处理我们的结果就可以了。
上面的话可能还是会有些拗口,在接下来我们会一点点进行剖析,最后会发现利用 Scrapy 框架来做爬虫是如此简单。
Scrapy的安装
windows 安装 pip install scrapy
Mac 安装 sudo pip install scrapy
pip 升级 pip install --upgrade pip
本人目前使用的是Mac电脑,目前使用的是 python3 版本,内容上其实都大同小异,如遇系统或版本问题可及时联系,互相学习!
安装完成后我们在终端输出 Scrapy 即可安装是否成功:
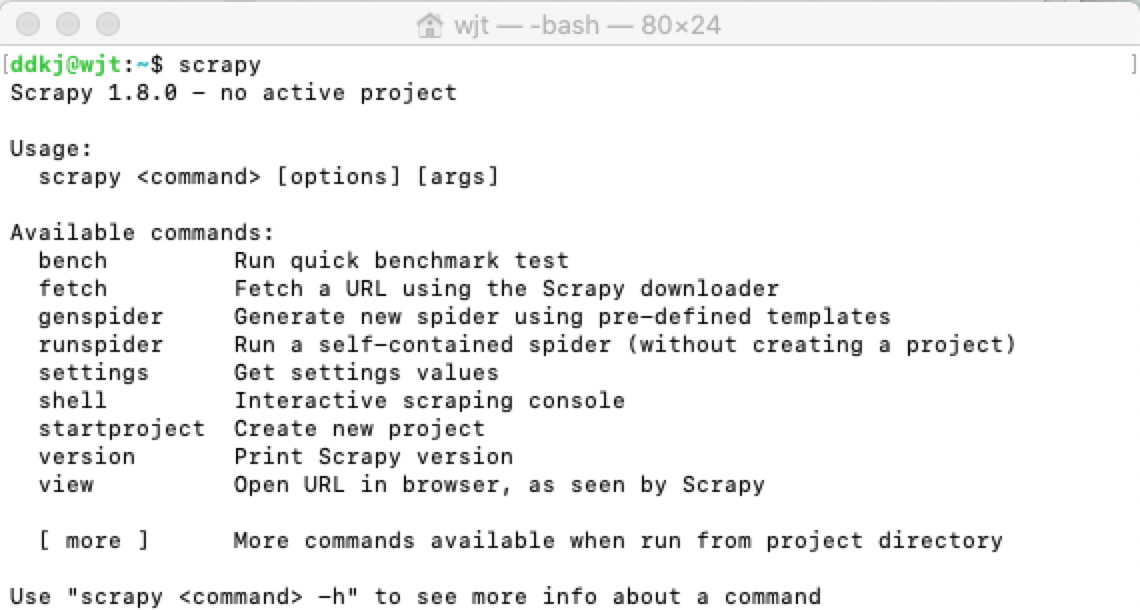
新建项目
在 Scrapy 安装成功之后,我们就需要用它来开发我们的爬虫项目了,进入自定义的项目目录中,运行下列命令:
scrapy startproject spiderDemo
运行上面的命令行就会在我们项目目录下生成一下目录结构:
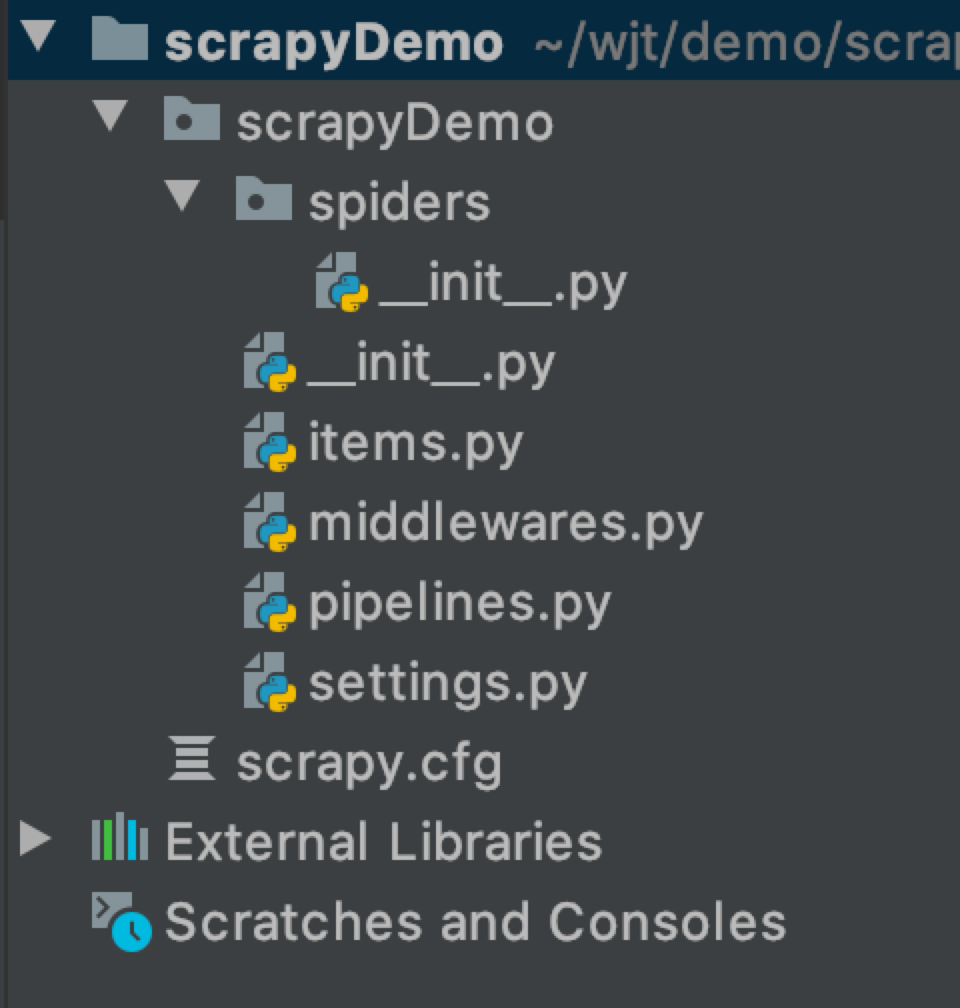
下面来简单介绍一下各个主要文件的作用:
scrapy.cfg :项目的配置文件
scrapyDemo/ :项目的Python模块,将会从这里引用代码
scrapyDemo/items.py :项目的目标文件
scrapyDemo/middlewares.py :项目的中间件文件
scrapyDemo/pipelines.py :项目的管道文件
scrapyDemo/settings.py :项目的设置文件
scrapyDemo/spiders/ :存储爬虫代码目录
接下来我们对各文件里的内容简单说一下,里面的代码目前都是最简单的基本代码,在接下来做案例的时候我们会再有针对地对文件做一下解释。
其中的 __init_.py 文件内容都是空的,但是却不能删除掉,否则项目将无法启动。
spiderDemo/items.py
1 # -*- coding: utf-8 -*- 2 3 # Define here the models for your scraped items 4 # 5 # See documentation in: 6 # https://docs.scrapy.org/en/latest/topics/items.html 7 8 import scrapy 9 10 11 class ScrapydemoItem(scrapy.Item): 12 # define the fields for your item here like: 13 # name = scrapy.Field() 14 pass
该文件是用来定义我们通过爬虫所获取到的有用的信息,即 scrapy.Item
scrapyDemo/middlewares.py
1 # -*- coding: utf-8 -*- 2 3 # Define here the models for your spider middleware 4 # 5 # See documentation in: 6 # https://docs.scrapy.org/en/latest/topics/spider-middleware.html 7 8 from scrapy import signals 9 10 11 class ScrapydemoSpiderMiddleware(object): 12 # Not all methods need to be defined. If a method is not defined, 13 # scrapy acts as if the spider middleware does not modify the 14 # passed objects. 15 16 @classmethod 17 def from_crawler(cls, crawler): 18 # This method is used by Scrapy to create your spiders. 19 s = cls() 20 crawler.signals.connect(s.spider_opened, signal=signals.spider_opened) 21 return s 22 23 def process_spider_input(self, response, spider): 24 # Called for each response that goes through the spider 25 # middleware and into the spider. 26 27 # Should return None or raise an exception. 28 return None 29 30 def process_spider_output(self, response, result, spider): 31 # Called with the results returned from the Spider, after 32 # it has processed the response. 33 34 # Must return an iterable of Request, dict or Item objects. 35 for i in result: 36 yield i 37 38 def process_spider_exception(self, response, exception, spider): 39 # Called when a spider or process_spider_input() method 40 # (from other spider middleware) raises an exception. 41 42 # Should return either None or an iterable of Request, dict 43 # or Item objects. 44 pass 45 46 def process_start_requests(self, start_requests, spider): 47 # Called with the start requests of the spider, and works 48 # similarly to the process_spider_output() method, except 49 # that it doesn’t have a response associated. 50 51 # Must return only requests (not items). 52 for r in start_requests: 53 yield r 54 55 def spider_opened(self, spider): 56 spider.logger.info('Spider opened: %s' % spider.name) 57 58 59 class ScrapydemoDownloaderMiddleware(object): 60 # Not all methods need to be defined. If a method is not defined, 61 # scrapy acts as if the downloader middleware does not modify the 62 # passed objects. 63 64 @classmethod 65 def from_crawler(cls, crawler): 66 # This method is used by Scrapy to create your spiders. 67 s = cls() 68 crawler.signals.connect(s.spider_opened, signal=signals.spider_opened) 69 return s 70 71 def process_request(self, request, spider): 72 # Called for each request that goes through the downloader 73 # middleware. 74 75 # Must either: 76 # - return None: continue processing this request 77 # - or return a Response object 78 # - or return a Request object 79 # - or raise IgnoreRequest: process_exception() methods of 80 # installed downloader middleware will be called 81 return None 82 83 def process_response(self, request, response, spider): 84 # Called with the response returned from the downloader. 85 86 # Must either; 87 # - return a Response object 88 # - return a Request object 89 # - or raise IgnoreRequest 90 return response 91 92 def process_exception(self, request, exception, spider): 93 # Called when a download handler or a process_request() 94 # (from other downloader middleware) raises an exception. 95 96 # Must either: 97 # - return None: continue processing this exception 98 # - return a Response object: stops process_exception() chain 99 # - return a Request object: stops process_exception() chain 100 pass 101 102 def spider_opened(self, spider): 103 spider.logger.info('Spider opened: %s' % spider.name)
该文件为中间件文件,名字后面的s表示复数,说明这个文件里面可以放很多个中间件,我们用到的中间件可以在此定义
spiderDemo/pipelines.py
1 # -*- coding: utf-8 -*- 2 3 # Define your item pipelines here 4 # 5 # Don't forget to add your pipeline to the ITEM_PIPELINES setting 6 # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html 7 8 9 class ScrapydemoPipeline(object): 10 def process_item(self, item, spider): 11 return item
该文件俗称管道文件,是用来获取到我们的Item数据,并对数据做针对性的处理。
scrapyDemo/settings.py
1 # -*- coding: utf-8 -*- 2 3 # Scrapy settings for scrapyDemo project 4 # 5 # For simplicity, this file contains only settings considered important or 6 # commonly used. You can find more settings consulting the documentation: 7 # 8 # https://docs.scrapy.org/en/latest/topics/settings.html 9 # https://docs.scrapy.org/en/latest/topics/downloader-middleware.html 10 # https://docs.scrapy.org/en/latest/topics/spider-middleware.html 11 12 BOT_NAME = 'scrapyDemo' 13 14 SPIDER_MODULES = ['scrapyDemo.spiders'] 15 NEWSPIDER_MODULE = 'scrapyDemo.spiders' 16 17 18 # Crawl responsibly by identifying yourself (and your website) on the user-agent 19 #USER_AGENT = 'scrapyDemo (+http://www.yourdomain.com)' 20 21 # Obey robots.txt rules 22 ROBOTSTXT_OBEY = True 23 24 # Configure maximum concurrent requests performed by Scrapy (default: 16) 25 #CONCURRENT_REQUESTS = 32 26 27 # Configure a delay for requests for the same website (default: 0) 28 # See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay 29 # See also autothrottle settings and docs 30 #DOWNLOAD_DELAY = 3 31 # The download delay setting will honor only one of: 32 #CONCURRENT_REQUESTS_PER_DOMAIN = 16 33 #CONCURRENT_REQUESTS_PER_IP = 16 34 35 # Disable cookies (enabled by default) 36 #COOKIES_ENABLED = False 37 38 # Disable Telnet Console (enabled by default) 39 #TELNETCONSOLE_ENABLED = False 40 41 # Override the default request headers: 42 #DEFAULT_REQUEST_HEADERS = { 43 # 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 44 # 'Accept-Language': 'en', 45 #} 46 47 # Enable or disable spider middlewares 48 # See https://docs.scrapy.org/en/latest/topics/spider-middleware.html 49 #SPIDER_MIDDLEWARES = { 50 # 'scrapyDemo.middlewares.ScrapydemoSpiderMiddleware': 543, 51 #} 52 53 # Enable or disable downloader middlewares 54 # See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html 55 #DOWNLOADER_MIDDLEWARES = { 56 # 'scrapyDemo.middlewares.ScrapydemoDownloaderMiddleware': 543, 57 #} 58 59 # Enable or disable extensions 60 # See https://docs.scrapy.org/en/latest/topics/extensions.html 61 #EXTENSIONS = { 62 # 'scrapy.extensions.telnet.TelnetConsole': None, 63 #} 64 65 # Configure item pipelines 66 # See https://docs.scrapy.org/en/latest/topics/item-pipeline.html 67 #ITEM_PIPELINES = { 68 # 'scrapyDemo.pipelines.ScrapydemoPipeline': 300, 69 #} 70 71 # Enable and configure the AutoThrottle extension (disabled by default) 72 # See https://docs.scrapy.org/en/latest/topics/autothrottle.html 73 #AUTOTHROTTLE_ENABLED = True 74 # The initial download delay 75 #AUTOTHROTTLE_START_DELAY = 5 76 # The maximum download delay to be set in case of high latencies 77 #AUTOTHROTTLE_MAX_DELAY = 60 78 # The average number of requests Scrapy should be sending in parallel to 79 # each remote server 80 #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 81 # Enable showing throttling stats for every response received: 82 #AUTOTHROTTLE_DEBUG = False 83 84 # Enable and configure HTTP caching (disabled by default) 85 # See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings 86 #HTTPCACHE_ENABLED = True 87 #HTTPCACHE_EXPIRATION_SECS = 0 88 #HTTPCACHE_DIR = 'httpcache' 89 #HTTPCACHE_IGNORE_HTTP_CODES = [] 90 #HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
该文件为我们的设置文件,一些基本的设置需要我们在此文件中进行配置,如我们的中间件文件当中的两个类 ScrapydemoSpiderMiddleware,ScrapydemoDownloaderMiddleware 在 settings.py 中就能找到。
在 settings 文件中,我们常会配置到如上面的字段 如:ITEM_PIPELINES(管道文件),DEFAULT_REQUEST_HEADERS(请求报头),DOWNLOAD_DELAY(下载延迟)
,ROBOTSTXT_OBEY(是否遵循爬虫协议)等。
本章我们就先简单的介绍一下 scrapy 的基本目录,下一章我们来根据 scrapy 框架实现一个爬虫案例。

