Hbase的读写过程
Hbase的读写过程
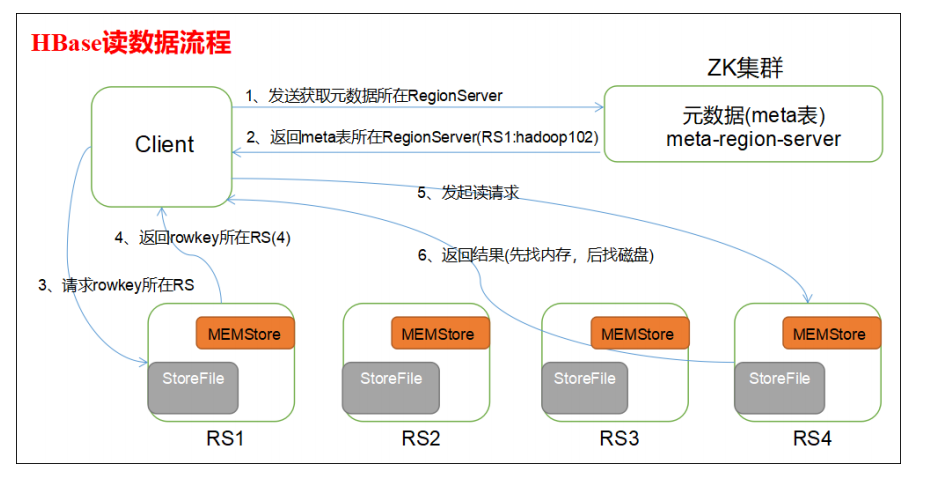
Hbase的读过程
1、客户端通过ZooKeeper以及-ROOT-表和.META.表找到目标数据所在的RegionServer(就是数据所在的
Region的主机地址)
2、联系RegionServer查询目标数据
3、RegionServer定位到目标数据所在的Region,发出查询请求
4、Region先在Memstore中查找,命中则返回
5、如果在Memstore中找不到,则在Storefile中扫描
1、先从memstore找数据,如果没找到
2、从blockcache找数据, 如果也没找到(布隆过滤器)
3、从HFile当中,HFile也是一种精妙设计的结果,扫描起来也不会特别的慢
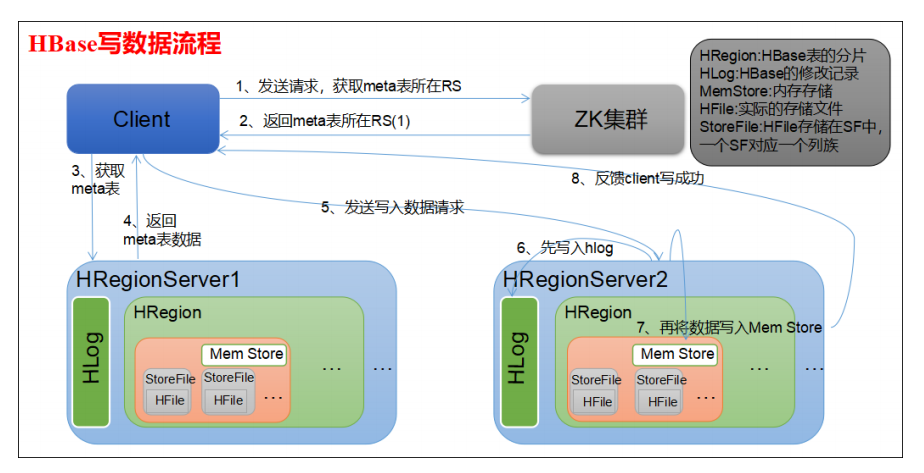
Hbase的写过程
1、Client先根据RowKey找到对应的Region所在的RegionServer
2、Client向RegionServer提交写请求
3、RegionServer找到目标Region
4、Region检查数据是否与Schema一致
5、如果客户端没有指定版本,则获取当前系统时间作为数据版本
6、将更新写入WAL Log
7、将更新写入Memstore
8、判断Memstore的是否需要flush为StoreFile文件。
Region的Split和Compact
当一个Store中的StoreFile达到一定的阈值后,就会进行一次合并(minor_compact, major_compact),将
对同一个key的修改合并到一起,形成一个大的StoreFile,当StoreFile的大小达到一定阈值后,又会对
StoreFile进行split,等分为两个StoreFile。
split 分裂
大的StoreFile分裂成两个
compact 合并
把同一个key的修改合并到一起
Minor_Compact 和 Major_Compact 的区别:
(1)Minor操作只用来做部分文件的合并操作以及包括minVersion=0并且设置ttl的过期版本清理,不做任何删除数据、多版本数据的清理工作。
(2)Major操作是对Region下的HStore下的所有StoreFile执行合并操作,最终的结果是整理合并出一个文件。
HBase只是增加数据,所有的更新和删除操作,都是在Compact阶段做的
