
决策树与随机森林
一.决策树
决策树原理 : 通过对一系列问题进行if/else的推导,最终实现决策.
1.决策树的构建
############################# 决策树的构建 ####################################### #导入numpy import numpy as np #导入画图工具 import matplotlib.pyplot as plt from matplotlib.colors import ListedColormap #导入tree模型和数据集加载工具 from sklearn import tree,datasets #导入数据集拆分工具 from sklearn.model_selection import train_test_split wine = datasets.load_wine() #只选取数据集的前两个特征 X = wine.data[:,:2] y = wine.target #将数据集拆分为训练集和测试集 X_train,X_test,y_train,y_test = train_test_split(X,y)
#设定决策树分类器最大深度为1 clf = tree.DecisionTreeClassifier(max_depth=1) #拟合训练数据集 clf.fit(X_train,y_train)
DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=1,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False, random_state=None,
splitter='best')
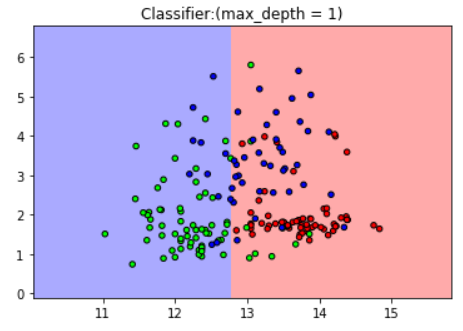
2.图示max_depth = 1 时的分类结果
#定义图像中分区的颜色和散点的颜色
cmap_light = ListedColormap(['#FFAAAA','#AAFFAA','#AAAAFF'])
cmap_bold = ListedColormap(['#FF0000','#00FF00','#0000FF'])
#分别用样本的两个特征值创建图像和横轴和纵轴
x_min,x_max = X_train[:, 0].min() - 1,X_train[:, 0].max() + 1
y_min,y_max = X_train[:, 1].min() - 1,X_train[:, 1].max() + 1
xx,yy = np.meshgrid(np.arange(x_min,x_max, .02),np.arange(y_min,y_max, .02))
Z = clf.predict(np.c_[xx.ravel(),yy.ravel()])
#给每个分类中的样本分配不同的颜色
Z = Z.reshape(xx.shape)
plt.figure()
plt.pcolormesh(xx, yy, Z, cmap=cmap_light)
#用散点图把样本表示出来
plt.scatter(X[:, 0],X[:, 1],c=y,cmap=cmap_bold,edgecolor='k',s=20)
plt.xlim(xx.min(),xx.max())
plt.ylim(yy.min(),yy.max())
plt.title("Classifier:(max_depth = 1)")
plt.show()
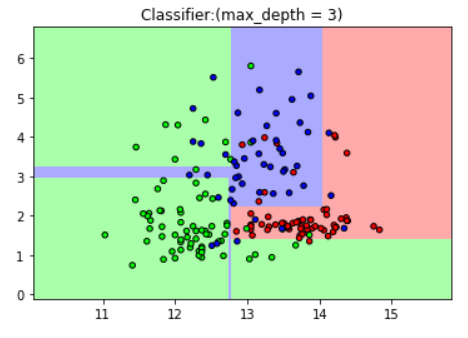
3.图示max_depth = 3 时的分类结果
#设定决策树最大深度为3 clf2 = tree.DecisionTreeClassifier(max_depth=3) #重新拟合数据 clf2.fit(X_train,y_train)
DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=3,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False, random_state=None,
splitter='best')
#定义图像中分区的颜色和散点的颜色
cmap_light = ListedColormap(['#FFAAAA','#AAFFAA','#AAAAFF'])
cmap_bold = ListedColormap(['#FF0000','#00FF00','#0000FF'])
#分别用样本的两个特征值创建图像和横轴和纵轴
x_min,x_max = X_train[:, 0].min() - 1,X_train[:, 0].max() + 1
y_min,y_max = X_train[:, 1].min() - 1,X_train[:, 1].max() + 1
xx,yy = np.meshgrid(np.arange(x_min,x_max, .02),np.arange(y_min,y_max, .02))
Z = clf2.predict(np.c_[xx.ravel(),yy.ravel()])
#给每个分类中的样本分配不同的颜色
Z = Z.reshape(xx.shape)
plt.figure()
plt.pcolormesh(xx, yy, Z, cmap=cmap_light)
#用散点图把样本表示出来
plt.scatter(X[:, 0],X[:, 1],c=y,cmap=cmap_bold,edgecolor='k',s=20)
plt.xlim(xx.min(),xx.max())
plt.ylim(yy.min(),yy.max())
plt.title("Classifier:(max_depth = 3)")
plt.show()
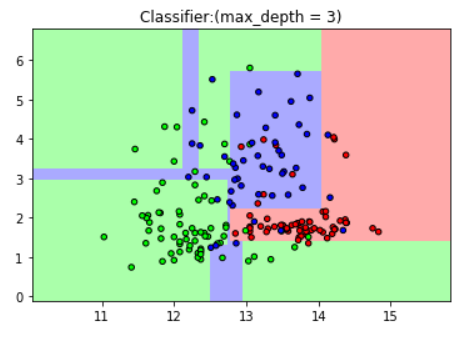
4.图示max_depth = 5 时的分类结果
#设定决策树最大深度为5 clf3 = tree.DecisionTreeClassifier(max_depth=5) #重新拟合数据 clf3.fit(X_train,y_train)
DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=5,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False, random_state=None,
splitter='best')
#定义图像中分区的颜色和散点的颜色
cmap_light = ListedColormap(['#FFAAAA','#AAFFAA','#AAAAFF'])
cmap_bold = ListedColormap(['#FF0000','#00FF00','#0000FF'])
#分别用样本的两个特征值创建图像和横轴和纵轴
x_min,x_max = X_train[:, 0].min() - 1,X_train[:, 0].max() + 1
y_min,y_max = X_train[:, 1].min() - 1,X_train[:, 1].max() + 1
xx,yy = np.meshgrid(np.arange(x_min,x_max, .02),np.arange(y_min,y_max, .02))
Z = clf3.predict(np.c_[xx.ravel(),yy.ravel()])
#给每个分类中的样本分配不同的颜色
Z = Z.reshape(xx.shape)
plt.figure()
plt.pcolormesh(xx, yy, Z, cmap=cmap_light)
#用散点图把样本表示出来
plt.scatter(X[:, 0],X[:, 1],c=y,cmap=cmap_bold,edgecolor='k',s=20)
plt.xlim(xx.min(),xx.max())
plt.ylim(yy.min(),yy.max())
plt.title("Classifier:(max_depth = 3)")
plt.show()
5.决策树的工作过程
'''
#导入graphviz工具
import graphviz
#导入决策树中输出graphviz的接口
from sklearn.tree import export_graphviz
#选择最大深度为3的分类模型
export_graphviz(clf2,out_file="wine.dot",class_name=wine.target_names,feature_anmes=wine.feature_names[:2],impurity=False,filled=True)
#打开一个dot文件
with open("wine.dot") as f:
dot_graph = f.read()
#显示dot文件中的图形
graphviz.Source(dot_graph)
'''
二.随机森林
随机森林有时候又被称为随机决策森林,是一种集合学习的方法,既可以用于分类,也可以用于回归.
1.随机森林的构建
############################# 随机森林的构建 ####################################### #导入numpy import numpy as np #导入画图工具 import matplotlib.pyplot as plt #导入随机森林模型 from sklearn.ensemble import RandomForestClassifier #导入数据集拆分工具 from sklearn.model_selection import train_test_split #载入红酒数据集 from sklearn.datasets import load_wine from matplotlib.colors import ListedColormap #sklearn的datasets模块载入数据集 datasets = load_wine() wine = datasets #选择数据集前两个特征 X = wine.data[:,:2] y = wine.target #将数据集拆分为训练集和数据集 X_train,X_test,y_train,y_test = train_test_split(X,y) #设定随机森林中有6棵树 forest = RandomForestClassifier(n_estimators=6,random_state=3) #使用模型拟合数据 forest.fit(X_train,y_train)
RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=6, n_jobs=None,
oob_score=False, random_state=3, verbose=0, warm_start=False)
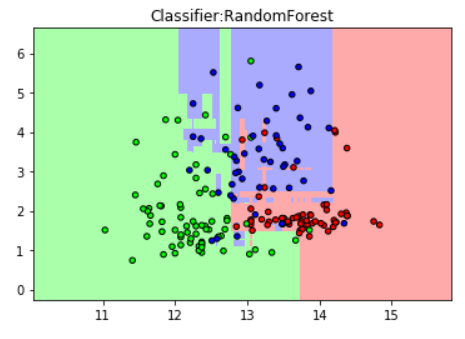
2.构图表现随机森林对酒的数据集进行的分类
#定义图像中分区的颜色和散点的颜色
cmap_light = ListedColormap(['#FFAAAA','#AAFFAA','#AAAAFF'])
cmap_bold = ListedColormap(['#FF0000','#00FF00','#0000FF'])
#分别用样本的两个特征值创建图像和横轴和纵轴
x_min,x_max = X_train[:, 0].min() - 1,X_train[:, 0].max() + 1
y_min,y_max = X_train[:, 1].min() - 1,X_train[:, 1].max() + 1
xx,yy = np.meshgrid(np.arange(x_min,x_max, .02),np.arange(y_min,y_max, .02))
Z = forest.predict(np.c_[xx.ravel(),yy.ravel()])
#给每个分类中的样本分配不同的颜色
Z = Z.reshape(xx.shape)
plt.figure()
plt.pcolormesh(xx, yy, Z, cmap=cmap_light)
#用散点图把样本表示出来
plt.scatter(X[:, 0],X[:, 1],c=y,cmap=cmap_bold,edgecolor='k',s=20)
plt.xlim(xx.min(),xx.max())
plt.ylim(yy.min(),yy.max())
plt.title("Classifier:RandomForest")
plt.show()
总结:
决策树:
1.如果使用决策树算法的话,我们几乎不需要对数据进行预处理,这是决策树的优点.
2.即便我们在建模的时候使用类似max_depth或是max_leaf_nodes等参数对决策树预处理,但是其还是不可避免的出现了过拟合问题.
随机森林:
1.和决策树一样,随机森林也不需要数据预处理.
2.随机森林在并行处理超大数据集时能提供良好的性能表现.
3.为了避免决策树的过拟合问题,所以我们选择了随机森林模型
线性模型与随机森林的对比:
随机森林更消耗内存,虚度也比线性模型慢,所以如果希望节省内存和时间,选择线性模型会更好一点.
在处理如:超高维数据集,稀疏数据集等随机森林的表现就不怎么好了,这时线性模型比随机森林表现要好一点.
文章引自:《深入浅出python机器学习》

