
朴素贝叶斯
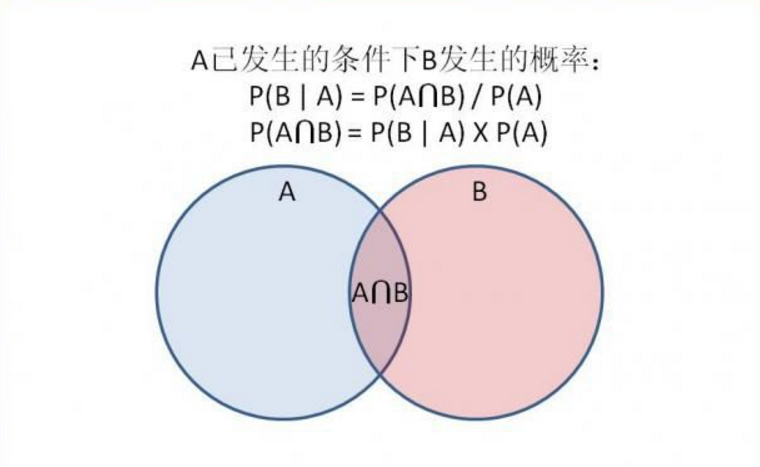
朴素贝叶斯定理 : 用来描述两个条件概率之间的关系,
比如 P(A|B) 和 P(B|A)。按照乘法法则,可以立刻导出:P(A∩B) = P(A)*P(B|A)=P(B)*P(A|B)。
如上公式也可变形为:P(B|A) = P(A|B)*P(B) / P(A)。
下面上代码,来一次天气预报,利用朴素贝叶斯来预测一下
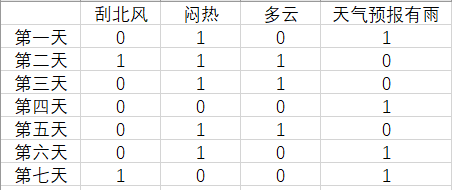
0代表否,1代表是,这样我们得到了一个数组
X = [0,1,0,1],[1,1,1,0],[0,1,1,0],[0,0,0,1],[0,1,1,0],[0,1,0,1],[1,0,0,1]
#导入numpy
import numpy as np
#将X,y赋值为np数组
X = np.array([[0,1,0,1],
[1,1,1,0],
[0,1,1,0],
[0,0,0,1],
[0,1,1,0],
[0,1,0,1],
[1,0,0,1]])
y = np.array([0,1,1,0,1,0,0])
#对不同分类计算每个特征为1的数量
counts = {}
for label in np.unique(y):
counts[label] = X[y == label].sum(axis=0)
print("feature counts:\n{}".format(counts))
结果:
feature counts:
{0: array([1, 2, 0, 4]), 1: array([1, 3, 3, 0])}
############################# 贝努利朴素贝叶斯 #######################################
#导入贝努利贝叶斯
from sklearn.naive_bayes import BernoulliNB
#使用贝努利贝叶斯拟合数据
clf = BernoulliNB()
clf.fit(X,y)
#要进行预测的这一天,没有刮北风,也不闷热,但是多云,天气预报没有说有雨
Next_Day = [[0,0,1,0]]
pre = clf.predict(Next_Day)
print('\n\n\n')
print('代码运行结果:')
print('====================================')
if pre == [1]:
print('要下雨了,快收衣服啊')
else:
print("放心,又是一个艳阳天")
print('====================================')
print('\n\n\n')
代码运行结果: ==================================== 要下雨了,快收衣服啊 ====================================
#假设另外一天的的数据如下
Another_day = [[1,1,0,1]]
#使用训练好的模型进行预测
pre2 = clf.predict(Another_day)
print('\n\n\n')
print('代码运行结果:')
print('====================================')
if pre2 == [1]:
print('要下雨了,快收衣服啊')
else:
print("放心,又是一个艳阳天")
print('====================================')
print('\n\n\n')
代码运行结果: ==================================== 放心,又是一个艳阳天 ====================================
print('\n\n\n')
print('代码运行结果:')
print('====================================')
#预测模型分类的概率
print(clf.predict_proba(Next_Day))
print('====================================')
print('\n\n\n')
代码运行结果: ==================================== [[0.13848881 0.86151119]] ====================================
print('\n\n\n')
print('代码运行结果:')
print('====================================')
#预测模型分类的概率
print(clf.predict_proba(Another_day))
print('====================================')
print('\n\n\n')
代码运行结果: ==================================== [[0.92340878 0.07659122]] ====================================
#导入数据集生成工具
from sklearn.datasets import make_blobs
#导入数据集拆分工具
from sklearn.model_selection import train_test_split
#生成样本数量为500,分类数为5的数据集
X,y = make_blobs(n_samples=500,centers=5,random_state=8)
#将数据集拆分成训练集和测试集
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=8)
#使用贝努利贝叶斯拟合数据
nb = BernoulliNB()
nb.fit(X_train,y_train)
print('\n\n\n')
print('代码运行结果:')
print('====================================\n')
#打印模型得分
print('模型得分:{:.3f}'.format(nb.score(X_test,y_test)))
print('\n====================================')
print('\n\n\n')
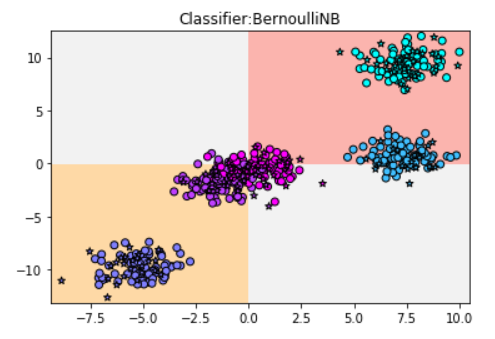
代码运行结果: ==================================== 模型得分:0.544 ====================================
#导入画图工具
import matplotlib.pyplot as plt
#限定横轴与纵轴的最大值
x_min,x_max = X[:,0].min()-0.5,X[:,0].max()+0.5
y_min,y_max = X[:,1].min()-0.5,X[:,1].max()+0.5
#用不同的背景色表示不同的分类
xx,yy = np.meshgrid(np.arange(x_min,x_max,.02),np.arange(y_min,y_max,.02))
z = nb.predict(np.c_[(xx.ravel(),yy.ravel())]).reshape(xx.shape)
plt.pcolormesh(xx,yy,z,cmap=plt.cm.Pastel1)
#将训练集和测试集用散点图表示
plt.scatter(X_train[:,0],X_train[:,1],c=y_train,cmap=plt.cm.cool,edgecolor='k')
plt.scatter(X_test[:,0],X_test[:,1],c=y_test,cmap=plt.cm.cool,marker='*',edgecolor='k')
plt.xlim(xx.min(),xx.max())
plt.ylim(yy.min(),yy.max())
#定义图题
plt.title('Classifier:BernoulliNB')
#现实图片
plt.show()
############################# 高斯朴素贝叶斯 #######################################
#导入高斯朴素贝叶斯
from sklearn.naive_bayes import GaussianNB
#使用高斯贝叶斯拟合数据
gnb = GaussianNB()
gnb.fit(X_train,y_train)
print('\n\n\n')
print('代码运行结果:')
print('====================================\n')
#打印模型得分
print('模型得分:{:.3f}'.format(gnb.score(X_test,y_test)))
print('\n====================================')
print('\n\n\n')
代码运行结果: ==================================== 模型得分:0.968 ====================================
#用不同的色块来表示不同的分类
z = gnb.predict(np.c_[(xx.ravel(),yy.ravel())]).reshape(xx.shape)
plt.pcolormesh(xx,yy,z,cmap=plt.cm.Pastel1)
#用散点图画出训练局和测试集数据
plt.scatter(X_train[:,0],X_train[:,1],c=y_train,cmap=plt.cm.cool,edgecolor='k')
plt.scatter(X_test[:,0],X_test[:,1],c=y_test,cmap=plt.cm.cool,marker='*',edgecolor='k')
plt.xlim(xx.min(),xx.max())
plt.ylim(yy.min(),yy.max())
#定义图题
plt.title('Classifier:GaussianNB')
#现实图片
plt.show()

############################# 多项式朴素贝叶斯 #######################################
#导入多项式朴素贝叶斯
from sklearn.naive_bayes import MultinomialNB
#导入数据预处理工具MinMaxScaler
from sklearn.preprocessing import MinMaxScaler
#使用MinMaxScaler对数据进行预处理,使数据全部为非负值
scaler = MinMaxScaler()
scaler.fit(X_train)
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)
#使用多项式朴素贝叶斯拟合经过预处理之后的数据
mnb = MultinomialNB()
mnb.fit(X_train_scaled,y_train)
print('\n\n\n')
print('代码运行结果:')
print('====================================\n')
#打印模型得分
print('模型得分:{:.3f}'.format(mnb.score(X_test_scaled,y_test)))
print('\n====================================')
print('\n\n\n')
代码运行结果: ==================================== 模型得分:0.320 ====================================
#用不同的色块来表示不同的分类
z = mnb.predict(np.c_[(xx.ravel(),yy.ravel())]).reshape(xx.shape)
plt.pcolormesh(xx,yy,z,cmap=plt.cm.Pastel1)
#用散点图画出训练局和测试集数据
plt.scatter(X_train[:,0],X_train[:,1],c=y_train,cmap=plt.cm.cool,edgecolor='k')
plt.scatter(X_test[:,0],X_test[:,1],c=y_test,cmap=plt.cm.cool,marker='*',edgecolor='k')
plt.xlim(xx.min(),xx.max())
plt.ylim(yy.min(),yy.max())
#定义图题
plt.title('Classifier:MultinomialNB')
#现实图片
plt.show()

总结:
贝努利朴素贝叶斯的模型很简单,直接以横纵轴分为四个象限来分类的,所以得分差
高斯朴素贝叶斯的分类边界要复杂的多,能够胜任大多数分类任务,这也跟高数中高斯分布有关,因为在数据中,呈正态分布的现象很普遍
多项式朴素贝叶斯只适合用来对非负离散数值特征进行分类,如:对转化为向量后的文本数据进行分类,所以需要数据预处理,常用的有MinMaxScaler将数据集中的特征值全部转化为0~1
文章引自:《深入浅出python机器学习》

