
基于libtorch的LeNet-5卷积神经网络实现
前文中我们详细讲了win10系统下VS2017+Opencv3.4.1+libtorch开发环境的配置。接下来,就让我们基于这个配置好的环境,来实现一个最经典的卷积神经网络LeNet-5吧,并使用实现的网络对Minst手写数字集进行分类。秉着学以致用的原则,本人是边学边做边总结的,也希望有此方面经验的读者多多指教,无经验的读者也没关系,我们共同学习一起进步~
1. LeNet-5网络的结构
首先我们讲一下LeNet-5网络的总体结构。

如上图所示,该网络总共有7层:C1、S2、C3、S4、C5、F6、OUTPUT。其中C1、C3、C5为卷积层,S2、S4为池化层,F6为Affine层,OUTPUT为全连接层。有关卷积层、池化层、Affine层和全连接层的基础知识,我们在前文已经详解过,读者可参考下方链接,在此我们着重讲每层的输入输出。
(1) C1层
C1作为LeNet-5网络的第一层,也是输入层。它的相关信息列出如下:
输入:1张32*32的图像。
卷积神经元个数:6个卷积神经元。
卷积核尺寸:每个卷积神经元对应1个5*5卷积核。
偏置:每个卷积神经元对应1个偏置值。·
卷积模式:Valid卷积模式。
激活函数:Relu函数。
输出尺寸:每个卷积神经元输出(32-5+1)*(32-5+1)=28*28的卷积结果,总共6个卷积神经元,因为总共输出6张28*28的卷积结果图像。
(2) S2层
本层信息列出如下:
输入:6张28*28的卷积结果图。
池化窗口尺寸:2*2。
池化模式:最大值池化。
输出尺寸:每张卷积结果图经过池化之后,变成(28/2)*(28/2)=14*14的图像,因此该层输入的6张28*28的图像变成6张14*14的图像。
(3) C3层
本层的相关信息列出如下:
输入:6张14*14的图像。
卷积神经元个数:16个卷积神经元。
卷积核尺寸:每个卷积神经元对应6个5*5卷积核。
偏置:每个卷积神经元对应1个偏置值。·
卷积模式:Valid卷积模式。
激活函数:Relu函数。
输出尺寸:每个卷积神经元输出(14-5+1)*(14-5+1)=10*10的卷积结果,总共16个卷积神经元,因为总共输出16张10*10的卷积结果图像。
(4) S4层
本层信息列出如下:
输入:16张10*10的卷积结果图。
池化窗口尺寸:2*2。
池化模式:最大值池化。
输出尺寸:每张卷积结果图经过池化之后,变成(10/2)*(10/2)=5*5的图像,因此该层输入的16张10*10的图像变成16张5*5的图像。
(5) C5层
本层的相关信息列出如下:
输入:16张5*5的图像。
卷积神经元个数:120个卷积神经元。
卷积核尺寸:每个卷积神经元对应16个5*5卷积核。
偏置:每个卷积神经元对应1个偏置值。·
卷积模式:Valid卷积模式。
激活函数:Relu函数。
输出尺寸:每个卷积神经元输出(5-5+1)*(5-5+1)=1*1的卷积结果,总共120个卷积神经元,因为总共输出120张1*1的卷积结果图像。
(6) F6层
本层是Affine层,其信息列出如下:
输入:首先将120张1*1的卷积结果图像按顺序展开成长度为120的一维向量,然后将该一维向量输入该层。
神经元个数:84个神经元,每个神经元都输入长度为120的一维向量。
权重个数:每个神经元对应120个权重,总共84个神经元,因此该层总共有84*120个权重。
偏置:每个卷积神经元对应一个偏置值,因此总共有84个偏置值。·
激活函数:Relu函数。
输出尺寸:对应84个神经元,输出84个数值,组成一个长度为84的一维向量。
(7) OUTPUT层
本层是全连接层,也是LeNet-5网络的最后一层,其信息列出如下:
输入:一个长度为84的一维向量。
神经元个数:10个神经元,每个神经元都输入长度为84的一维向量。
权重个数:每个神经元对应84个权重,总共10个神经元,因此该层总共有10*84个权重。
偏置:每个卷积神经元对应一个偏置值,因此总共有10个偏置值。·
激活函数:Softmax函数。
输出尺寸:每个神经元输出一个0~1之间的概率值,因此总共输出10个概率值。
2. 基于libtorch的LeNet-5网络代码实现
(1) 包含的头文件与命名空间
#include <iostream>
#include <memory>
#include <torch/torch.h>
#include <torch/script.h>
#include <opencv2/opencv.hpp>
#include <opencv2/core/core.hpp>
#include <opencv2/xfeatures2d.hpp>
using namespace cv;
using namespace std;
using namespace torch;
(2) LeNet-5网络的结构定义
struct LeNet5 : torch::nn::Module
{
//arg_padding为C1层的padding参数,当输入图像为28*28时,需要将其填充为32x32的图像
//这里可能有人会有疑惑,为什么没有定义S2、S4层,这是因为池化层放在前向传播函数中执行即可,不需要再定义了,详细见forward函数
LeNet5(int arg_padding = 0)
//C1层
: C1(register_module("C1", torch::nn::Conv2d(torch::nn::Conv2dOptions(1, 6, 5).padding(arg_padding))))
//C3层
, C3(register_module("C3", torch::nn::Conv2d(6, 16, 5)))
//C5层
, C5(register_module("C5", torch::nn::Conv2d(16, 120, 5)))
//F6层
, F6(register_module("F6", torch::nn::Linear(120, 84)))
//OUTPUT层
, OUTPUT(register_module("OUTPUT", torch::nn::Linear(84, 10)))
{
}
~LeNet5()
{
}
//该函数用于将多维数据一维展开成一维向量
int64_t num_flat_features(torch::Tensor input)
{
int64_t num_features = 1;
auto sizes = input.sizes();
for (auto s : sizes)
{
num_features *= s;
}
return num_features;
}
//前向传播函数
torch::Tensor forward(torch::Tensor input)
{
namespace F = torch::nn::functional;
//这一步其实包含了3个操作,首先是C1层的卷积,其次是将卷积结果输入Relu函数,接着是将Relu函数的结果做最大值的池化操作
auto x = F::max_pool2d(F::relu(C1(input)), F::MaxPool2dFuncOptions({ 2,2 }));
//这一步也包含了3个操作,首先是C3层的卷积,其次是将卷积结果输入Relu函数,接着是将Relu函数的结果做最大值的池化操作
x = F::max_pool2d(F::relu(C3(x)), F::MaxPool2dFuncOptions({ 2,2 }));
//将C5层的卷积结果输入Relu函数,Relu函数的结果作为本层输出
x = F::relu(C5(x));
//120张1*1的卷积结果图像按顺序展开成长度为120的一维向量
x = x.view({ -1, num_flat_features(x) });
//F6层的Affine计算
x = F::relu(F6(x));
//OUTPUT层的Affine计算,注意这里不包括Softmax层计算,Softmax层计算放到后面的交叉熵误差函数中去做
x = OUTPUT(x);
return x;
}
//要求这里的各层定义与本结构体开头处的定义保持一致
int m_padding = 0;
torch::nn::Conv2d C1;
torch::nn::Conv2d C3;
torch::nn::Conv2d C5;
torch::nn::Linear F6;
torch::nn::Linear OUTPUT;
};
(3) Minst手写数字图像的读取
Minst数据集的格式,我们在前文已详解,读者可参考以下链接:
卷积神经网络原理及其C++/Opencv实现(8)—手写数字图像识别
由于libtorch框架的数据格式为Tensor,我们使用Opencv读取的数据格式为Mat,因此我们首先使用Mat格式读取每一张手写数字图像,在训练和分类的时候,再将Mat格式转换为Tensor格式。
//英特尔处理器需要将数据的大小端反转
int ReverseInt(int i)
{
unsigned char ch1, ch2, ch3, ch4;
ch1 = i & 0xff;
ch2 = (i >> 8) & 0xff;
ch3 = (i >> 16) & 0xff;
ch4 = (i >> 24) & 0xff;
return ((int)(ch1 << 24)) + ((int)(ch2 << 16)) + ((int)(ch3 << 8)) + (int)ch4;
}
// 读入手写数字图像
vector<Mat> read_Img_to_Mat(const char* filename)
{
FILE *fp = NULL;
fp = fopen(filename, "rb");
if (fp == NULL)
printf("open file failed\n");
assert(fp);
int magic_number = 0;
int number_of_images = 0;
int n_rows = 0;
int n_cols = 0;
fread(&magic_number, sizeof(int), 1, fp); //从文件中读取sizeof(int) 个字符到 &magic_number
magic_number = ReverseInt(magic_number); //如果是英特尔处理器,需要将读取数据的大小端反转
fread(&number_of_images, sizeof(int), 1, fp); //获取训练或测试image的个数number_of_images
number_of_images = ReverseInt(number_of_images);
fread(&n_rows, sizeof(int), 1, fp); //获取训练或测试图像的高度Heigh
n_rows = ReverseInt(n_rows);
fread(&n_cols, sizeof(int), 1, fp); //获取训练或测试图像的宽度Width
n_cols = ReverseInt(n_cols);
//获取第i幅图像,保存到vec中
int i;
int img_size = n_rows * n_cols;
vector<Mat> img_list;
for (i = 0; i < number_of_images; ++i)
{
Mat tmp(n_rows, n_cols, CV_8UC1);
fread(tmp.data, sizeof(uchar), img_size, fp);
tmp.convertTo(tmp, CV_32F);
tmp = tmp / 255.0; //将数据大小转换到0~1之间
tmp = (tmp - 0.5) / 0.5; //将数据大小转换到-1~1之间
img_list.push_back(tmp.clone());
}
fclose(fp);
return img_list;
}
//读取标签
//mode -- 0 -- 一个数据的格式
//mode -- 1 -- one hot独热码格式
vector<Mat> read_Lable_to_Mat(const char* filename, int mode)// 读入图像
{
FILE *fp = NULL;
fp = fopen(filename, "rb");
if (fp == NULL)
printf("open file failed\n");
assert(fp);
int magic_number = 0;
int number_of_labels = 0;
int label_long = 10;
fread(&magic_number, sizeof(int), 1, fp); //从文件中读取sizeof(magic_number) 个字符到 &magic_number
magic_number = ReverseInt(magic_number);
fread(&number_of_labels, sizeof(int), 1, fp); //获取训练或测试image的个数number_of_images
number_of_labels = ReverseInt(number_of_labels);
int i, l;
vector<Mat> label_list;
if (mode == 0)
{
Mat tmp = Mat::zeros(1, 1, CV_32FC1);
for (i = 0; i < number_of_labels; ++i)
{
unsigned char temp = 0;
fread(&temp, sizeof(unsigned char), 1, fp);
tmp.ptr<float>(0)[0] = temp;
label_list.push_back(tmp.clone());
}
}
else //one hot
{
for (i = 0; i < number_of_labels; ++i)
{
Mat tmp = Mat::zeros(1, label_long, CV_32FC1);
unsigned char temp = 0;
fread(&temp, sizeof(unsigned char), 1, fp);
tmp.ptr<float>(0)[(int)temp] = 1.0;
label_list.push_back(tmp.clone());
}
}
fclose(fp);
return label_list;
}
(4) 训练
Minst数据集中,train-images-idx3-ubyte文件为训练数据,train-labels-idx1-ubyte为训练数据对应的标签。

训练过程主要分为前向传播、反向传播、参数更新,这个过程我们在前文有详细说明,在此我们主要讲一下梯度下降法的Momentum模式,我们注意到代码中是按如下定义优化器的,其实就是定义为Momentum模式。
auto optimizer = torch::optim::SGD(net1.parameters(), torch::optim::SGDOptions(0.001).momentum(0.9));
Momentum模式与梯度下降法通常模式的主要区别在于参数的更新。
通常模式的参数更新公式如下,其中μ为学习率。
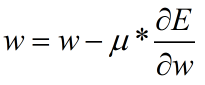
Momentum模式的参数更新公式如下,其中α为固定参数,通常取0.9。可以看到该模式引入了速度v,当前轮的速度v不仅与当前轮迭代的梯度、学习率μ有关,还与上轮迭代的速度v有关。这样做的好处在于加快收敛速度。
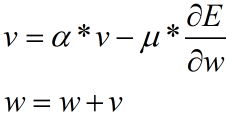
完整的训练代码如下:
void tran_lenet_5(void)
{
//读取训练数据与标签
vector<Mat> train_data = read_Img_to_Mat("./data/train-images-idx3-ubyte");
vector<Mat> train_label = read_Lable_to_Mat("./data/train-labels-idx1-ubyte", 0);
//定义一个LeNet-5网络结构体,输入的图像是28x28,需要设置padding为2,转化为32x32
LeNet5 net1(2);
//定义交叉熵误差函数,注意该函数本身就包含了Softmax操作
auto criterion = torch::nn::CrossEntropyLoss();
//定义梯度下降法优化器
auto optimizer = torch::optim::SGD(net1.parameters(), torch::optim::SGDOptions(0.001).momentum(0.9));
int64_t kNumberOfEpochs = 2;
for (int64_t epoch = 1; epoch <= kNumberOfEpochs; ++epoch)
{
auto running_loss = 0.;
for (int i = 0; i < train_data.size(); i++)
{
//将Mat格式转换为Tensor格式
torch::Tensor inputs = torch::from_blob(train_data[i].data, {1, 1, train_data[i].rows, train_data[i].cols}, torch::kFloat); //1*1*28*28
torch::Tensor labels = torch::from_blob(train_label[i].data, { 1 }, torch::kFloat); //1
labels = labels.toType(torch::kLong); //此处的标签就是一个0~9之间的数字,并不是独热码,需要将该数值转换为long int格式,否则会出错
//清零梯度
optimizer.zero_grad();
//前向传播
auto outputs = net1.forward(inputs);
//计算交叉熵误差
auto loss = criterion(outputs, labels);
//误差反向传播
loss.backward();
//更新参数
optimizer.step();
//累加每3000个误差值,方便查看训练时交叉熵误差函数的下降情况
running_loss += loss.item().toFloat();
if ((i + 1) % 2000 == 0)
{
printf("loss: %.3f\n", running_loss / 2000);
running_loss = 0.;
}
}
}
printf("Finish training!\n");
torch::serialize::OutputArchive archive;
net1.save(archive);
archive.save_to("mnist.pt"); //保存训练好的模型到文件,方便下次使用
printf("Save the training result to mnist.pt.\n");
}
(5) 分类测试
Minst数据集中,t10k-images-idx3-ubyte文件为测试数据,t10k-labels-idx1-ubyte为测试数据对应的标签。经过上一步骤的训练之后,我们就可以使用训练好的模型对训练数据之外的其它数据进行分类了。
完整的测试代码如下:
void test_lenet_5(void)
{
LeNet5 net1(2);
torch::serialize::InputArchive archive;
archive.load_from("mnist.pt"); //加载上一步骤训练好的模型
net1.load(archive);
//读取测试数据
vector<Mat> test_data = read_Img_to_Mat("./data/t10k-images-idx3-ubyte");
//读取测试数据的标签
vector<Mat> test_label = read_Lable_to_Mat("./data/t10k-labels-idx1-ubyte", 0);
int total_test_items = 0, passed_test_items = 0;
for (int i = 0; i < test_data.size(); i++)
{
//将Mat格式转换为Tensor格式
torch::Tensor inputs = torch::from_blob(test_data[i].data, { 1, 1, test_data[i].rows, test_data[i].cols }, torch::kFloat);
torch::Tensor labels = torch::from_blob(test_label[i].data, { 1 }, torch::kFloat); //获取标签数据, 0 ~ 9
labels = labels.toType(torch::kLong); //注意标签要转换为long int类型
//使用训练好的模型对测试数据进行分类,也即前向传播过程
auto outputs = net1.forward(inputs);
//得到分类值,0 ~ 9
auto predicted = (torch::max)(outputs, 1);
//比较分类结果和对应的标签是否一致,如果一致则认为分类正确
if (labels[0].item<int>() == std::get<1>(predicted).item<int>())
passed_test_items++;
total_test_items++;
printf("label: %d.\n", labels[0].item<int>());
printf("predicted label: %d.\n", std::get<1>(predicted).item<int>());
}
printf("total_time=%f\n", total_time);
printf("total_test_items=%d, passed_test_items=%d, pass rate=%f\n", total_test_items, passed_test_items, passed_test_items*1.0/total_test_items);
}
(6) main函数
我们在main函数中调用训练函数与测试函数:
int main()
{
tran_lenet_5(); //训练
test_lenet_5(); //测试
return EXIT_SUCCESS;
}
3. 运行结果
运行上述代码,先训练模型、保存模型,然后再加载模型(实际使用时如果已经训练好模型,可直接加载模型而不需要再训练)。
训练时目标函数(损失函数)的变化如下图所示,可以看到其值逐步减小,因此我们的训练是非常成功的,哈哈~

待训练完成以及保存模型之后,就可以加载模型对数据进行分类预测啦,我们的分类结果如下图所示,可以看到准确率达到了98.32%,这个分类结果还是挺理想的。

本文我们就讲到这里啦,本人已把Minst数据集上传到以下网址,读者如下想下载Minst数据集,可以到该地址下载:
https://download.csdn.net/download/shandianfengfan/16675315?spm=1001.2014.3001.5501
欢迎扫码关注以下微信公众号,接下来会不定时更新更加精彩的内容噢~

