
CUDA加速——基于规约思想的数组元素求和
数组元素求和,顾名思义就是求数组中所有元素的和,比如有数组X:
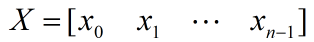
X的所有元素和就是:
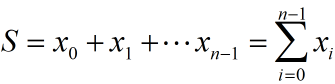
如果按串行顺序求上式还是很好理解的,就是一个逐渐累加的过程,如下图,按照step1~stepn的步骤,依次计算S0,S1,S2,...,Sn-1,最后得到的Sn-1即是所有元素的和:
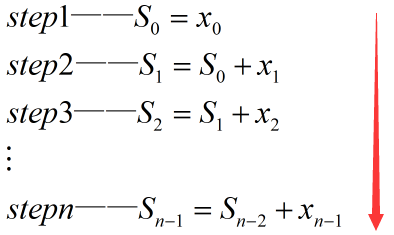
01
—
规约求和思想
以上串行顺序计算的step1~stepn是按照先后顺序依次执行的,那么如果是并行顺序求和呢?也即将多个求和步骤并行执行,而不是按照先后顺序执行,这时该怎么办?
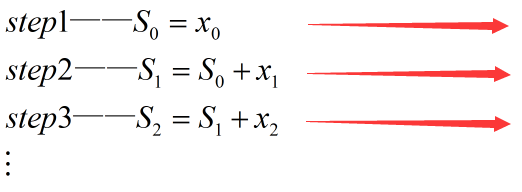
由于step1~stepn中后步骤的计算结果依赖于前步骤的结果,必须等待前步骤计算结果出来之后才能开始后步骤的计算,如果直接对step1~stepn这n个步骤并行执行,显然是不能得到正确结果的,因为前步骤的结果还没出来后步骤就开始计算了。
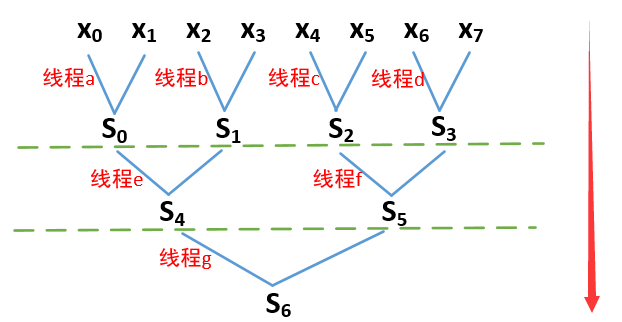
为解上述问题,通常采用规约思想来并行计算。下面我们举一个简单的例子来说明规约思想,假设数组X有8个元素,现要使用规约思想求其元素和:
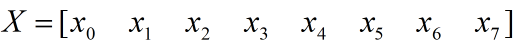
步骤如下:
将x0~x7两两分组:(x0,x1)、(x2,x3)、(x4,x5)、(x6,x7)。然后使用4个线程并行计算每组的元素和,得到4个求和结果:
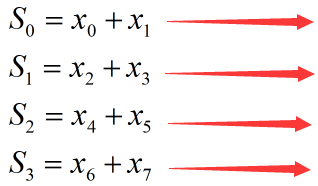
再将上一步骤得到的4个求和结果两两分组:(S0,S1)、(S2,S3)。然后使用2个线程并行计算每组的元素和,得到2个求和结果:
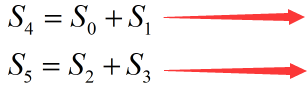
使用1个线程计算上一步骤得到的S4,S5之和,也即最终求和结果:
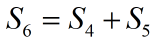
以上3个步骤可用下图表示,每个步骤都将数据两两分组,然后并行计算每组的元素和,最后得到一个结果,这就是规约的过程:
02
—
CUDA实现数组元素的规约求和
CUDA是为并行计算而生的,使用CUDA可以很容实现上述的数组规约求和算法。不过有一点需要注意,就是必须确保每个步骤的所有线程是同步的,也即所有线程计算完成之后再进入下一步骤的计算,否则会导致结果错误。
比如假设上图的线程a、b、c已完成计算,但是线程d未完成计算,如果不等线程d完成计算就直接进入下一步骤计算S4和S5,由于线程d未完成计算,得到的S3是错误的值,这导致得到的S5也是错误的值,从而导致最终计算的S6也错了——这将导致错误的连锁反应。
在CUDA中,可以调用__syncthreads函数方便地同步同一个线程块中的所有线程,因此我们可以使用同一个线程块中的多个线程做规约运算。那么问题来了,如果数据量很大,一个线程块不能完成所有数据的规约运算该怎么办呢?答案是分块处理,将数据平均分成多个部分,每部分都分配给一个线程块做规约运算。因此每个线程块最后得到一个规约结果,最后再将多个规约结果求和,即得到最后结果。如下图所示:
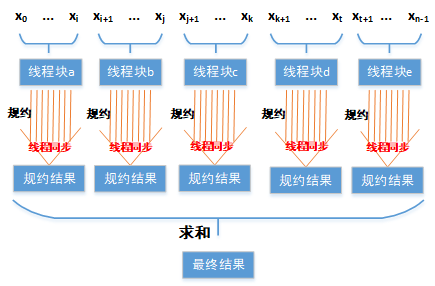
也许这里有人会问,最后得到的多个规约结果还是得按照串行顺序求和呀,这样做有点脱裤子放屁了。我想说是这样,只不过最后得规约结果相对原始数据个数,已经少了很多很多了,因此其串行求和的耗时基本可以忽略。
CUDA核函数代码如下:
#define N (1536 * 20480) //数据总长度
//Para为输入数组,长度为N
//blocksum_cuda存储所有线程块的规约结果
__global__ void cal_sum_ker0(float *Para, float *blocksum_cuda)
{
//计算线程ID号
//blockIdx.x为线程块的ID号
//blockDim.x每个线程块中包含的线程总个数
//threadIdx.x为每个线程块中的线程ID号
int tid = blockIdx.x * blockDim.x + threadIdx.x;
if(tid < N)
{
for (int index = 1; index < blockDim.x; index = (index*2))
{
if (threadIdx.x % (index*2) == 0)
{
Para[tid] += Para[tid + index]; //规约求和
}
__syncthreads(); //同步线程块中的所有线程
}
if(threadIdx.x == 0) //整个数组相加完成后,将共享内存数组0号元素的值赋给全局内存数组0号元素,最后返回CPU端
blocksum_cuda[blockIdx.x] = Para[tid];
}
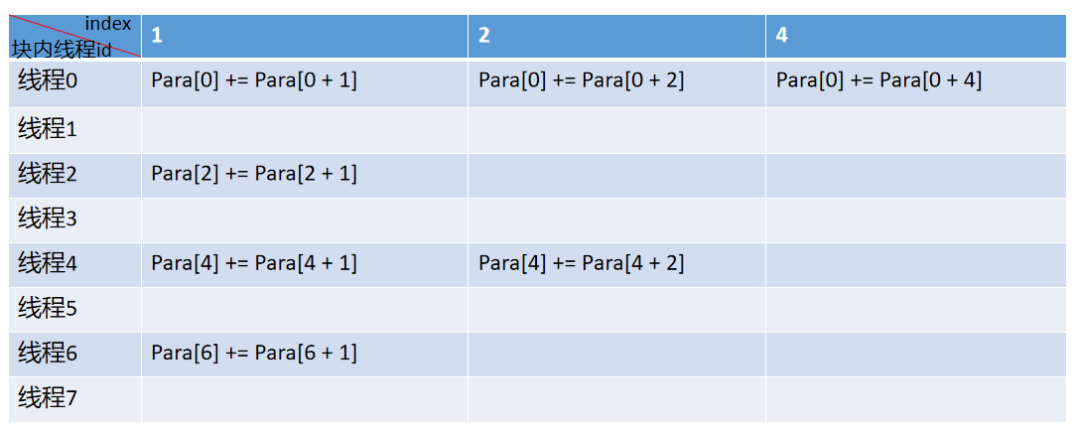
}上面代码的for循环,咋一看很难理解,没有关系,我们举个简单例子来说明就好了。假设:blockDim.x=8,也即每个线程块有8个线程;N=8,也即输入数组的长度为8。那么对于第0个线程块(其它线程块也类似),其包含线程id为0~7,计算过程如下,你是否已经发现,其计算过程就是上述讲的规约过程呀~
下面我们写代码来测试上方实现的规约算法是否正确:
首先,定义一个微秒级计时的类,用于计时:
class Timer_Us2
{
private:
LARGE_INTEGER cpuFreq;
LARGE_INTEGER startTime;
LARGE_INTEGER endTime;
public:
double rumTime;
void get_frequence(void)
{
QueryPerformanceFrequency(&cpuFreq); //获取时钟频率
}
void start_timer(void)
{
QueryPerformanceCounter(&startTime); //开始计时
}
void stop_timer(char *str)
{
QueryPerformanceCounter(&endTime); //结束计时
rumTime = (((endTime.QuadPart - startTime.QuadPart) * 1000.0f) / cpuFreq.QuadPart);
cout << str << rumTime << " ms" << endl;
}
Timer_Us2() //构造函数
{
QueryPerformanceFrequency(&cpuFreq);
}
};接着是测试函数:
void Cal_Sum_Test()
{
Timer_Us2 timer;
//申请长度为N的float型动态内存
float *test_d = (float *)malloc(N * sizeof(float));
for (long long i = 0; i < N; i++)
{
test_d[i] = 0.5; //将所有元素赋值为0.5
}
double ParaSum = 0.0;
timer.start_timer();
//在CPU端按顺序计算数组元素和
for (long long i = 0; i < N; i++)
{
ParaSum += test_d[i]; //CPU端数组累加
}
timer.stop_timer("CPU time:");
cout << " CPU result = " << ParaSum << endl; //显示CPU端结果
//设置每个线程块有1024个线程
dim3 sumblock(1024);
//设置总共有多少个线程块
dim3 sumgrid(((N%sumblock.x) ? (N/sumblock.x + 1) : (N/sumblock.x)));
float *test_d_cuda;
float *blocksum_cuda;
float *blocksum_host = (float *)malloc(sizeof(float) * sumgrid.x);
//申请GPU端全局内存
cudaMalloc((void **)&test_d_cuda, sizeof(float) * N);
cudaMalloc((void **)&blocksum_cuda, sizeof(float) * sumgrid.x);
timer.start_timer();
//将数据从CPU端拷贝到GPU端
cudaMemcpy(test_d_cuda, test_d, sizeof(float) * N, cudaMemcpyHostToDevice);
//调用核函数进行规约求和
cal_sum_ker0 << < sumgrid, sumblock >> > (test_d_cuda, blocksum_cuda);
//将每个线程块的规约求和结果拷贝到CPU端
cudaMemcpy(blocksum_host, blocksum_cuda, sizeof(float) * sumgrid.x, cudaMemcpyDeviceToHost);
//在CPU端对所有线程块的规约求和结果做串行求和
double sum = 0.0;
for(int i = 0; i < sumgrid.x; i++)
{
sum += blocksum_host[i];
}
timer.stop_timer("GPU time:");
cout << " GPU result = " << sum << endl; //显示GPU端结果
//释放内存
cudaFree(test_d_cuda);
cudaFree(blocksum_cuda);
free(blocksum_host);
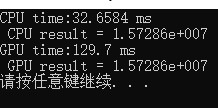
free(test_d);运行结果如下,可以看到对1536*20480长度的数组求元素和,CPU和GPU的计算结果是一致的,不过GPU CUDA计算耗时反而比CPU更多了,一方面是因为GPU计算多了host与device端内存拷贝的耗时,另一方面是因为我们实现的CUDA规约算法没有做到优化的极致,还有不小的优化空间。那么接下来让我们继续尝试优化吧~
欢迎扫码关注本微信公众号,接下来会不定时更新更加精彩的内容,敬请期待~
