
redis数据结构(三) - Dict字典
字典又称为符号表,关联数组或者映射,是一种用于保存键值对的抽象数据结构。字典的每个键都独一无二的,但redis所使用的C语言并没有内置这种数据结构,因此redis构建了自己的字典实现。
在数据库中创建一个键为“msg”,值为“hello world”的键值对时,这个键值对就是保存在代表数据库的字典里面。除了表示数据库之外,字典还是哈希键的底层实现之一,当一个哈希键包含的键值对比较多,又或者键值对中的元素都是比较长的字符串是,redis就会使用字典作为哈希键的底层实现。
例:website是包含10086个键值对的哈希键,这个哈希键的键都是一些数据库的名字,而键的值就是数据库的主页网址:
redis>HLEN website
(integer) 10086
redis>HGETALL website
1)"redis"
2)"Redis.io"
3)"MariaDB"
4)"MariaDB.org"
5)"MongoDB"
6)"MongoDB.org"
.......
website键的底层实现就是一个字典,字典中包含了10086个键值对 例如
键值对的键为"redis",值为"redis.io"。
键值对的键为"MariaDB",值为"MariaDB.org"。
键值对的键为"MongoDB",值为"MongoDB.org"。
一,字典的实现
redis的字典使用哈希表作为底层实现,一个哈希表里面可以有多个哈希表节点,而每个哈希表节点就保存了字典中的一个键值对
1.哈希表
redis字典所使用的哈希表由dict.h/dictht结构定义:
typedef struct dictht{
//哈希表数组
dictEntry **table;
//哈希表大小
unsigned long size;
//哈希表大小掩码 用于计算索引位置 总是等于size-1
unsigned long sizemask;
//该哈希表已有节点的数量
unsigned long used;
}dictht;
table属性是一个数组,数组中每个元素都是指向dict.h/dictEntry结构的指针,每个dictEntry结构保存着一个键值对。
size属性记录了哈希表的大小,也即是table数组的大小,
而used属性则记录了哈希表目前已有节点(键值对)的数量。
sizemask属性的值总是等于size-1,这个属性和哈希值一起决定一个键应该被放倒table数组的那个索引上面
2.哈希表的节点
哈希表用dictEntry结构表示,每一个dictEntry结构都保存着一个键值对:
typedef struct dictEntry{
//键
void *key;
//值
union{
void *val;
nint64_tu64;
int64_ts64;
}v;
//指向下个哈希表节点,形成链表
struct dictEntry *next;
}dictEntry;
key属性保存着键值对中的键,而v属性则保存着键值对中的值,其中键值对的值可以是一个指针,或者是一个unit64_t整数,又或者是是一个int64_t整数
next 属性指向另一个哈希表节点的指针,这个指针可以将多个哈希值相同的键值对连接在一起,以此来解决键冲突的问题。
3.字典
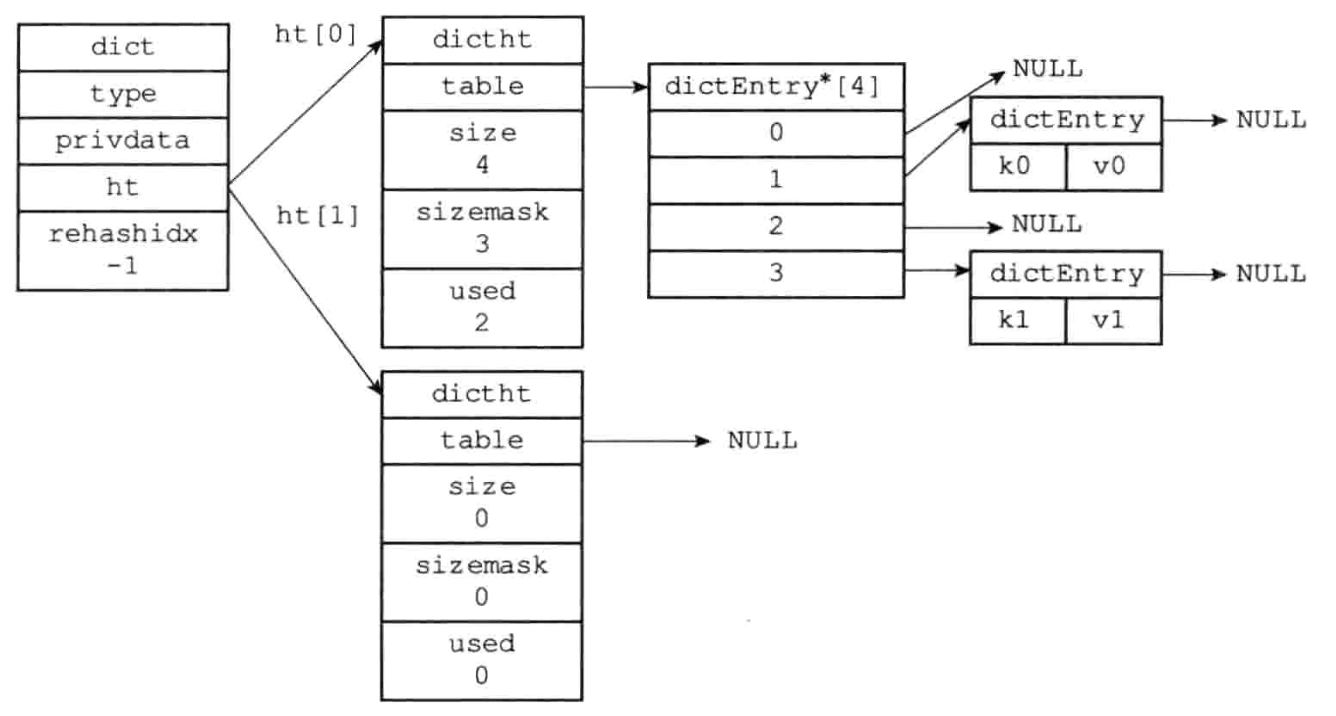
redis中的字典由dict.h/dict结构表示
typedef struct dict{
//类型特定的函数
dictType *type;
//私有数据
void *privdata;
//哈希表
dictht ht[2];
//rehash索引
//当rehash不在进行时,值为-1
in trehashidx;/*rrehashing not in progress if rehashidx==-1*/
}dict;
type属性和privdata属性是针对不同类型的键值对,为创建多态字典而设计的;
1.type属性是一个指向dictType结构的指针,每个dictType结构保存了一簇用于操作特定类型键值对的函数,redis会为用途不同的字典设置不同类型特定函数。
2.而privdata属性则保存了需要传给那些类型特定函数的可选参数
typedef struct dictType{
//计算哈希值的函数
unsigned int (*hashFunction) (const void *key);
//复制键的函数
void *(*keyDup) (void *privdata, const void *key);
//复制值的函数
void *(*valDup) (void *privdata,const void *obj);
//对比键的函数
int (*keyDestructor) (void *privdata,const void *key1,const void key2);
//销毁键的函数
void (*keyDestructor) (void *privdata,void *key);
//销毁值的函数
void (*valDestructor) (void *privdata,void *obj);
}dictType;
ht属性是一个包含两个项的数组,数组中的每一项都是一个dictht哈希表,一般情况下,字典只使用ht[0]哈希表,ht[1]哈希表只会对ht[0]哈希表进行rehash时使用。
rehashidx记录了rehash目前的进度,如果目前没有进行rehash,那么他的值为-1.
下图展示没有rehash的字典
4.哈希算法
当要将一个新的键值对添加到字典里面时,程序需要先根据键值对的键计算出哈希值和索引值,然后再根据索引值,将包含新键值对的哈希表节点放到哈希表数组的指定索引上面。
redis计算哈希值和索引的方法如下
#使用字典的哈希函数,计算key的哈希值
hash=dict->type->hashFunction(key);
#使用哈希表的sizemask属性和哈希值,计算出索引
#根据情况不同,ht[x] 可以是ht[0] 或者ht[1]
index=hash&dict->ht[x] .sizemask;
5.解决键冲突
当两个或以上的键被分配到哈希表数组的同一个索引上面时,我们称这些键发生了冲突。
redis的哈希表使用连地址法来解决键冲突,每个哈希表节点都由一个next指针,多个哈希表节点可以用next指针构成一个单向链表,
被分配到同一个索引上的多个节点可以用这个单向链表连接起来,这就解决了键冲突的问题。
6.rehash
随着操作的不断进行,哈希表保存的键值对会逐渐的增多或减少,为了让哈希表的负载因子维持一个合理的范围之内,当哈希表保存的键值对数量太大或者太少时,程序需要对哈希表进行相应的扩展或收缩。
扩展和收缩哈希表的工作可以通过执行rehash(重新散列)操作完成,redis对字典的哈希表执行rehash的步骤如下:
1.为字典的ht[1] 哈希表分配空间,这个哈希表空间大小取决于执行的操作,以及ht[0]当前包含的键值对数量(也即是ht[0].used属性的值 ):
a.如果执行的是扩展操作,那么ht[1] 的大小为第一次大于等于ht[0] .used*2的2的n次方
b.如果执行的是收缩操作,那么ht[1] 的大小为第一个大于等于ht[0].used的2的n次方
2.将保存在ht[0]中所有的键值对rehash到ht[1] 上面:
3.当ht[0]包含的所有键值对都迁移到了ht[1] 之后(ht[0]变为空表 ),释放ht[0],将ht[1] 设置为ht[0],并在ht[1] 新创建一个空白的哈希表,为下一次rehash做准备。
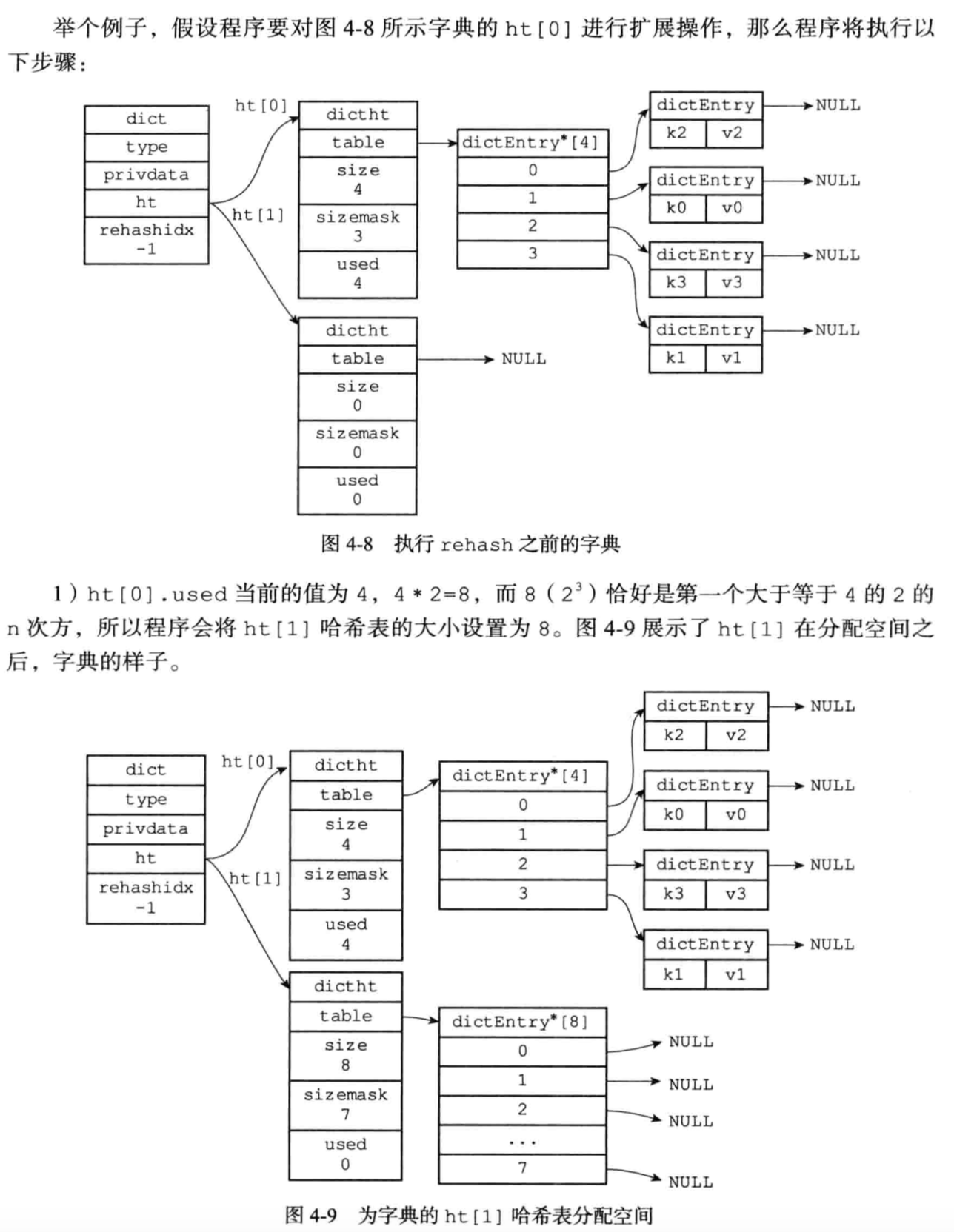
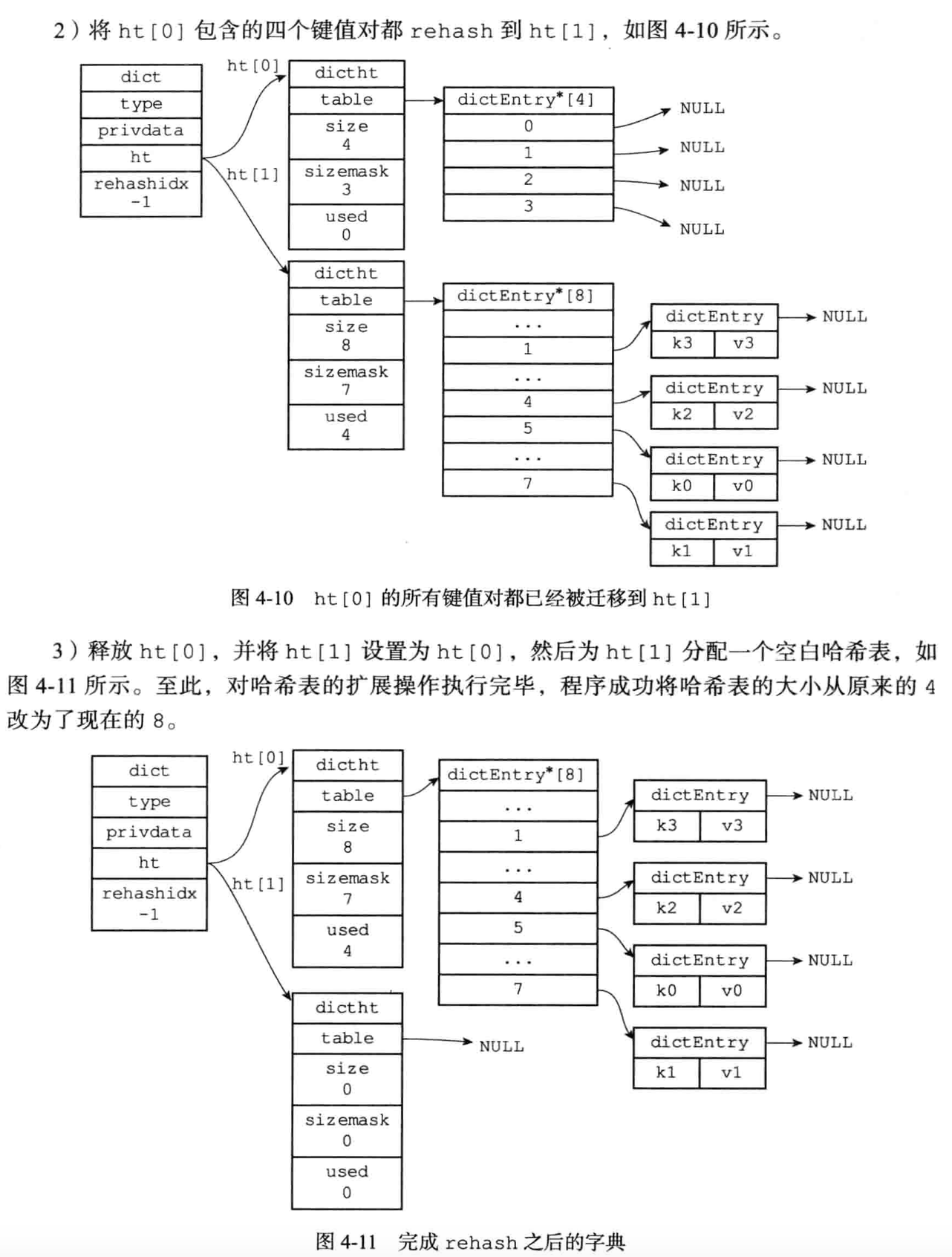
哈希表的扩展与收缩
当以下条件中的任意一个被满足时,程序会自动开始对哈希表执行扩容操作:
1.服务器目前没有在执行BGSAVE命令或者BGREWRITEAOF命令,并且哈希表的负载因子大于等于1
2.服务器目前正在执行BGSAVE命令或者BGREWRITEAOF命令,并且哈希表的负载因子大于等于5
其中哈希表的负载因子可以通过公式
#负载因子=哈希表已保存节点数/哈希表大小
load_factory=ht[0].used/ht[0].size
计算得出
例如,对于一个大小为4,包含4个键值对的哈希表来说,这个哈希表的负载因子为
load_factory=4/4=1
根据BGSAVE命令或者BGREWRITEAOF命令是否正在执行,服务器执行扩展操作所需的负载因子并不相同,这是因为在执行BGSAVE命令或者BGREWRITEAOF命令的过程中,
redis需要创建当前服务器进程的子进程,而大多数操作系统都采用写时复制(copy-on-write)技术来优化子进程的使用效率,所以在子进程存在期间,服务器会提高执行扩展操作所需的负载因子,
从而尽可能地避免在子进程存在期间进行哈希扩展操作,这可以避免不必要的内存写入操作,最大限度的节约内存。
7.渐进式rehash
上面说过,扩展或收缩哈希表需要将ht[0]里面的所有键值对rehash到ht[1]里面,但是,这个rehash动作并不是一次性的,集中性完成的,而是分多次,渐进式完成的。
这样做的原因在于,如果ht[0]里面只保存着四个键值对,那么服务器可以在瞬间就将这些键值对全部rehash到ht[1];但是如果哈希表中保存千万甚至上亿键值对时,
那么要一次性将这些键值对全部rehash到ht[1]的话,庞大的数据计算量可能会导致服务器在一段时间内停止服务,
渐进式rehash的详细步骤:
1.为ht[1]分配空间,让字典同事持有ht[0]和ht[1]两个哈希表
2.在字典中维持一个索引的计数器变量rehashidx,并将他的值设置为0,表示rehash工作正式开始
3.在rehash进行期间,每次对字典执行添加,删除,查找或者更新时,程序除了执行指定的操作外,
还会顺带着将ht[0]哈希表在rehashidx索引上的所有键值对rehash到ht[1],当rehash工作完成之后,程序将rehashidx属性的值增一。
4.随着字典操作的不断执行,最终在某个时间点上,ht[0]的所有键值对都会rehash到ht[1],这时候rehashidx的值设置为-1,表示rehash完成
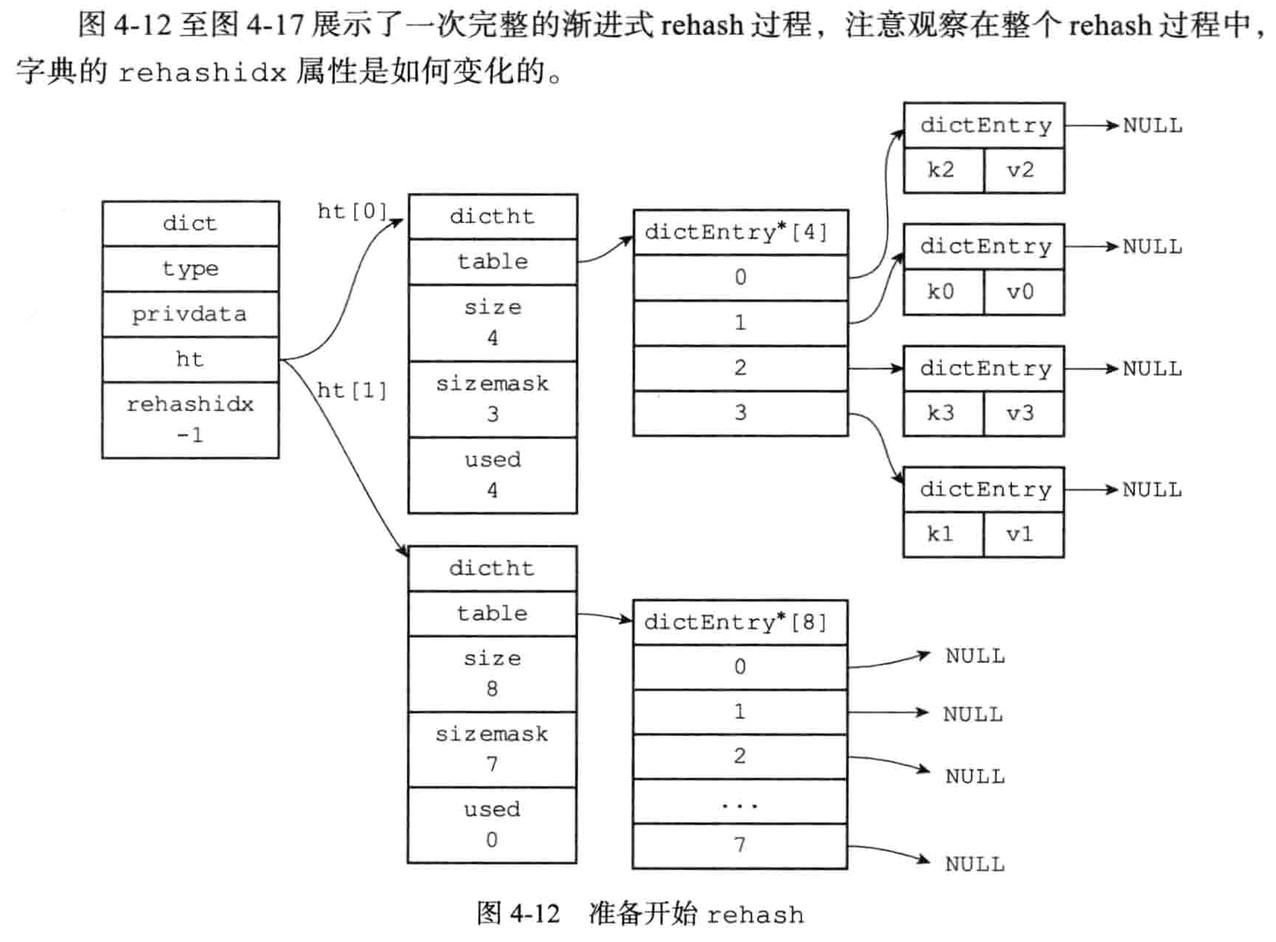
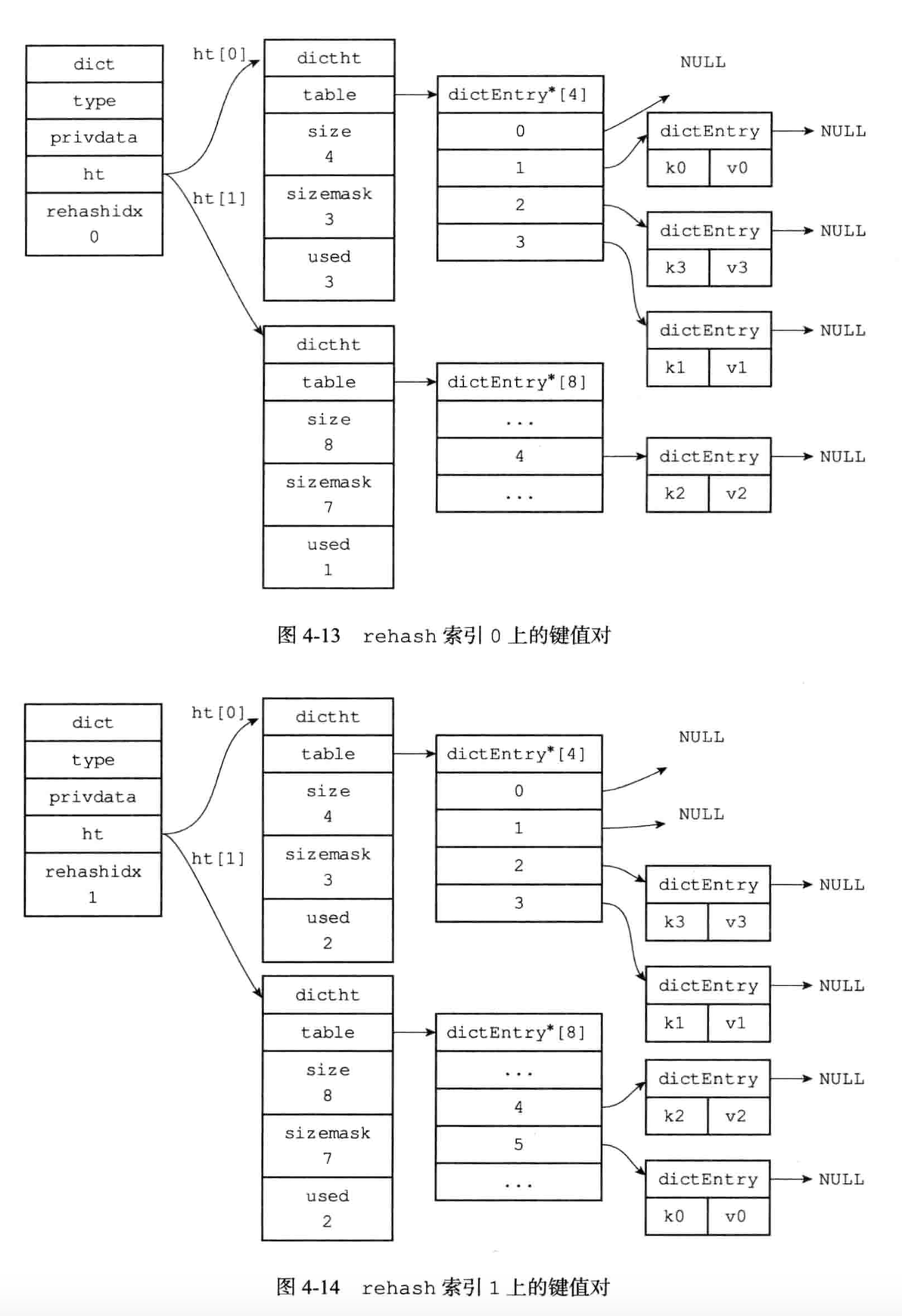
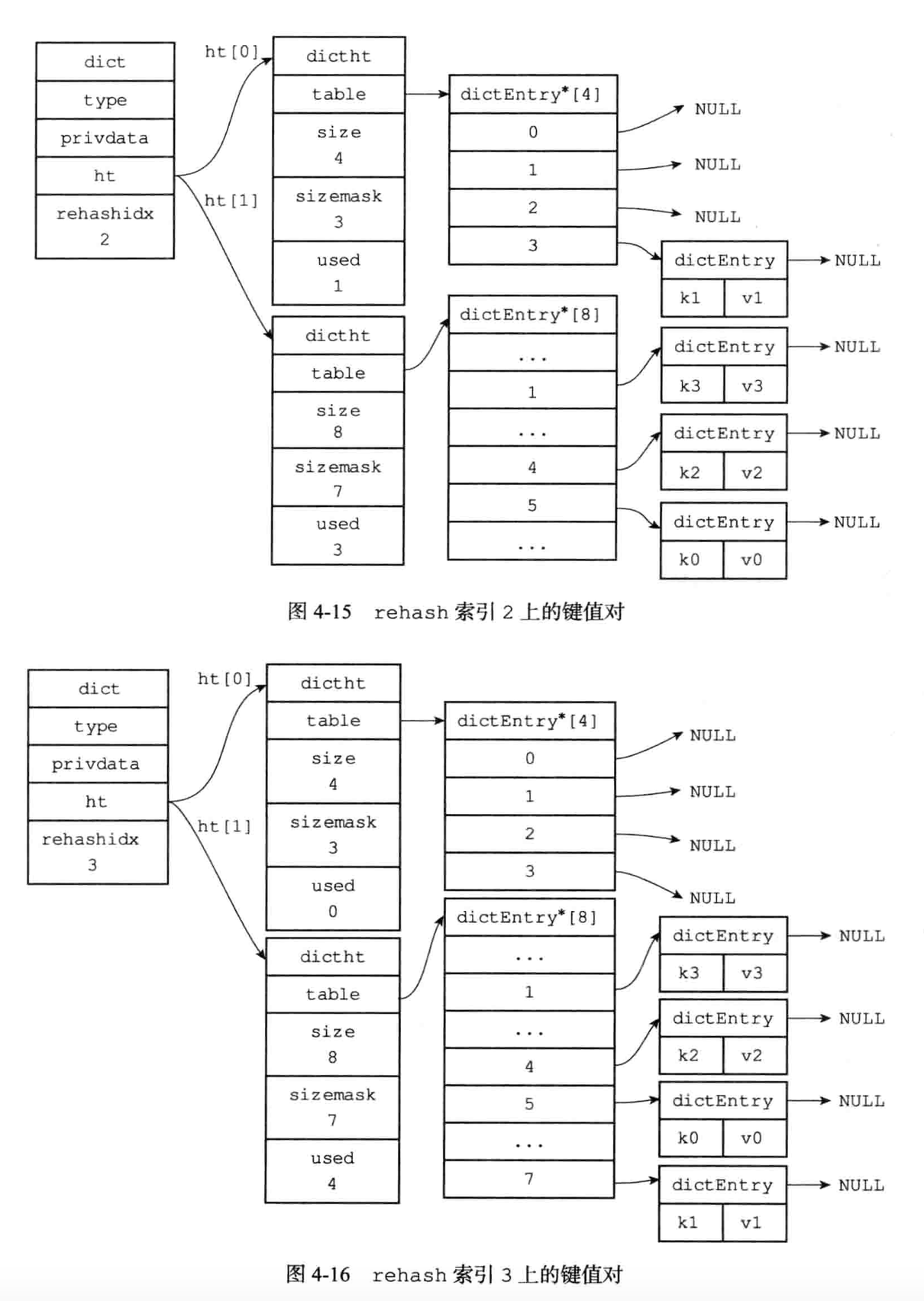
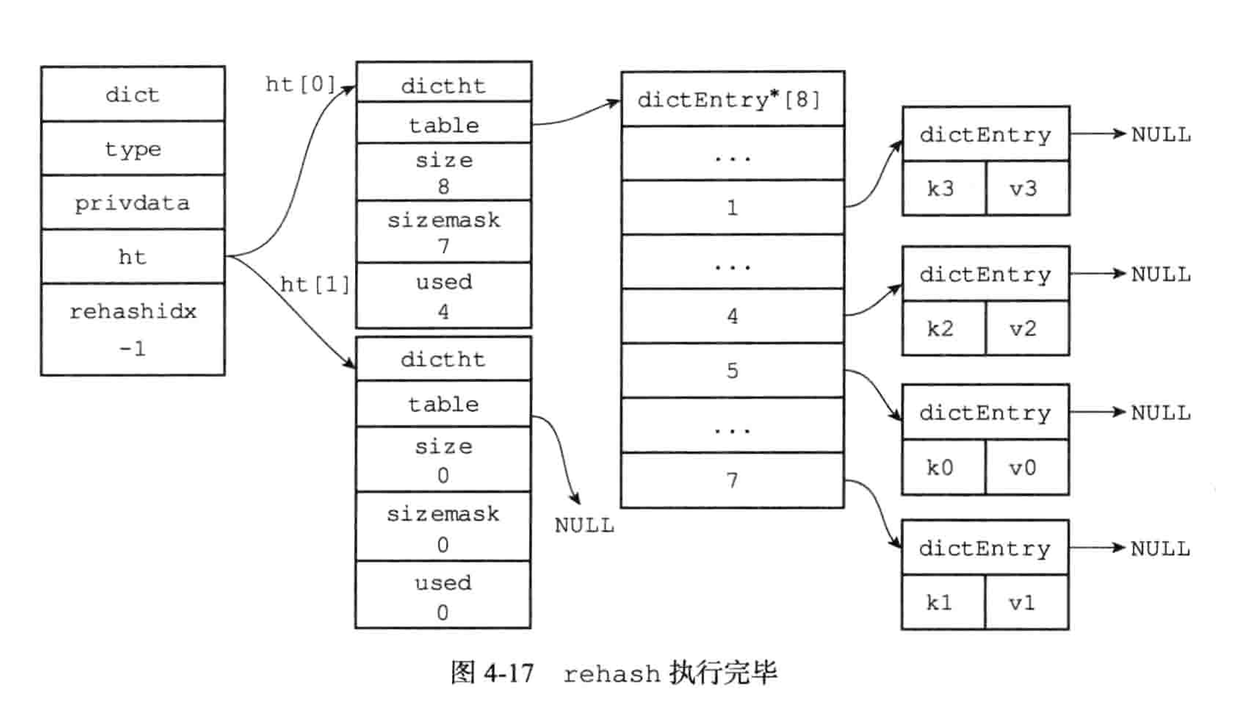
渐进式rehash执行期间的哈希表操作
因为在进行渐进式rehash的过程中,字典会同时使用ht[0]和ht[1]两个哈希表,所以渐进式rehash进行期间,字典的删除,查找,更新等操作会在两个哈希表上进行,
例如:要在字典里查找一个键的话,现在ht[0]中查找,没有找到的话,再继续到ht[1]中进行查找
另外,在渐进式rehash执行期间,新添加到字典的键值对一律会保存到ht[1]里面,而ht[0]则不再进行任何添加操作,并随着rehash操作的执行而最终变成空表,

8.重点回顾
1.字典被广泛用于实现redis的各种功能,其中包括数据库和哈希键
2.redis中的字典使用哈希表作为底层实现,或者哈希键的底层实现,redis使用MumurHash2算法来计算哈希值
3.哈希表使用链地址法来解决键冲突,被分配到同一索引上的多个键值对会连接成一个单向链表
4.在对哈希表进行扩展或者收缩操作时,程序需要将现有哈希表包含的所有键值对rehash到新的哈希表中,并且这个rehash过程并不是一次性完成的,而是渐近性的完成的。
本文摘自《redis设计与实现》 黄健宏 著

 浙公网安备 33010602011771号
浙公网安备 33010602011771号