
寒假作业2/2
| 这个作业属于哪个课程 | 2021软件工程实践W班 |
|---|---|
| 这个作业要求在哪里 | 寒假作业2/2 |
| 这个作业的目标 | 阅读构建之法,并提出问题,完成WordCount |
| 其他参考文献 | CSDN |
Part1.阅读构建之法并提问
1
第二章2.4.1提到了软件的开放-封闭原则,说的是允许扩展但是不允许修改。在需求发证变化时,我们需要对模块进行扩展,但是我们不要改变模块本身。乍一看,我有点懵,怎么样才能对摸块进行扩展的情况下做到不改变模块本身,仔细一想,我们可以依赖于抽象。实现开放封闭的核心思想就是对抽象编程,而不对具体编程,因为抽象相对稳定。让类依赖于固定的抽象,所以对修改就是封闭的;而通过面向对象的继承和对多态机制,可以实现对抽象体的继承,通过覆写其方法来改变固有行为,实现新的扩展方法,所以对于扩展就是开放的。
2
第三章3.2提到了过早优化,并且提出了“过早优化是一切罪恶的根源”。由于没有什么经验,在我看来所谓的过早优化是不是就是当你发现某个模块能够更加完善,所以就顺手将这个模块进行了优化,而不必等到整个工程完成再去对一些细节进行优化完善,这样子能够在完成项目时得到一个比较完善的项目,从而减少了需要再优化的部分。查阅资料解释的是关键部分的优化是很有必要的,也是必须的,但是很多优化是不值得做也不应该做的,这些优化才被称为过早优化的一部分。也就是说所谓的过早优化的部分在对于全局来说是不重要的,不用在这些不值得的事情上浪费大量的人力物力。
3
第四章4.1提到了代码的规范问题,并且列举了4种不同的代码格式。
A格式

B格式

C格式

D格式

对于我而言我也喜欢D格式的,因为这个格式层次分明,很容易看懂。但是在实际中,例如在软件上进行代码编写,系统自动生成的代码风格确是C类型的,但是对于我而言,D型明显更具有优势,也更容易 程序员对于代码进行阅读,所以我写代码的话也会按照D格式来进行编写。但是我还是不明白为什么系统生成的代码默认格式为C类型。
4
第八章8.2提到了软件产品的利益相关者,在我之前没看书之前,我的理解是受益人和用户。顾名思义,受益人就是从这个软件获取利益的人,而用户是使用软件的人。看了书上关于这方面的描述,我发现并不是我所想的这样,这一条利益链上有很多不同身份的人,用户-客户-系统集成商-应用集成商-软件团队-软件工程师等等。软件开发不可能一次性满足所有利益相关者的要求,但是我们得让这些人能够提出他们的需求。所以问题来了,我们作为一个软件开发的团队,那么我们从什么地方获取他们的需求呢?一个使用软件的用户和软件开发的团队之间隔着很多利益相关者,我们获取需求是从上一级利益相关者获取还是从用户那里获取又或者是直接从每一级利益相关者获取?我们将如何进行取舍,才能最大程度满足需求?
5
第十六章的迷思之七“成功的团队更能创新”,给我们解释了事实并非我们所想的那样理所当然,当一个团队获得了成功之后,慢慢步入中年,当年发迹的市场成熟了,当时获得成功的创新技术成为了现在主流的成熟技术,人们自然而然的会趋于维持这个技术,反而创新对于他们来说有些不符合团队的问化,这样子反而是那些没有成功包袱的团队更加能够把颠覆性的创新带到市场。在我看来,这有一定的道理,但是我觉得在样子的对比有些不太合适。从数量上来说,成功的团队就要比那些还没成功的要少(所谓成功应该指的是还没有被淘汰的),而当我们对比创新的时候,比的是创新的数量而不是百分比,所以这个更能创新只能实在某一个维度上合理,相比于没有成功的团队,已经成功的团队有更多的资源去发展创新,并不影响他们维持已经趋于成熟的技术,二者并不冲突,而那些没有成功的团队去创新是因为现实在逼迫他们去创新,因为适者生存,所以同样是创新,但是出发点还是有区别的。我无法判断二者谁更容易创新,但他们都是创新的主力军。
冷知识
第一个写软件的人是Ada(Augusta Ada Lovelace),在1860年代她尝试为 Babbage(Charles Babbage)的机械式计算机写软件。尽管他们的努力失败了,但他们的名字永远载入了计算机发展的史册。她的父亲就是那个狂热的,不趋炎附势的激进诗人和冒险家拜伦。她本身也是一个光彩照人的人物—数学尖子和某种程度上的赌徒。她最重要的贡献来自于与发明家Charles Babbage的合作,从而设计出世界上首批大型计算机—Difference Engine和Analytical Engine。她甚至认为如果有正确的指令,Babbage的机器可以用来作曲,这是一个多么疯狂的想法,因为当时大多数人只把它看成是一个机械化算盘,而她却有渲染力和感召力来传播她的思想。
Part2.WordConut编程
GitHub地址
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 10 |
| • Estimate | • 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 900 | 1150 |
| • Analysis | • 需求分析 (包括学习新技术) | 240 | 300 |
| • Design Spec | • 生成设计文档 | 30 | 35 |
| • Design Review | • 设计复审 | 30 | 25 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 40 | 30 |
| • Design | • 具体设计 | 60 | 40 |
| • Coding | • 具体编码 | 400 | 360 |
| • Code Review | • 代码复审 | 20 | 20 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 80 | 340 |
| Reporting | 报告 | 180 | 85 |
| • Test Report | • 测试报告 | 60 | 60 |
| • Size Measurement | • 计算工作量 | 10 | 15 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 20 | 10 |
| 合计 | 1100 | 1245 |
解题思路描述
1.实现文件字符读取,我想到就是说用ready一个个取读取,并且将读取到的字符存在一个字符串中,后买你进行操作时就不用重复读取文件了
2.字符读取显然只要统计ASCII范围内的字符就可以了
3.行数的统计需要去掉看不见的行数,这里我想用正则表达式,因为这个代码相对来说要少很多
4.单词数的统计也用到了正则表达式,利用split("\s+")以空格为分隔符进行拆分并存temp[],在利用正则表达式检查是否符合规范,符合规范的单词全部转化为小写并且存入wordsMap
5.要统计单词出现频率,应该是用键值对的形式进行存储
代码规范
设计与实现过程
两个类,一个WordCOunt类,包含main函数以及输出;
Lib类里有五个函数,实现五个功能。
1.读取文件,用read()方法一个字符一个字符读取,并将他们存起来,便于后面方法就行操作,从而减少对文件的读取次数,提高效率。
public static String readFile(String filePath)
{
int flag;
StringBuffer content = new StringBuffer();
try
{
BufferedReader br = new BufferedReader(new FileReader(filePath));
//将字符一个个读入content
while((flag=br.read()) != -1)
{
content.append((char)flag);
}
}
catch (FileNotFoundException e)
{
e.printStackTrace();
}
catch (IOException e)
{
e.printStackTrace();
}
return content.toString();
}
2.读取字符,判断范围即可,只有在0-127范围内都属于字符
public static int getCharacterNum(String str)
{
int charactersNum = 0;
char[] a = str.toCharArray();
for(int i = 0;i < str.length();i++)
{
if(a[i] >= 0 && a[i] <= 127)
{
charactersNum++;
}
else
{
continue;
}
}
return charactersNum;
}
3.用正则表达式去匹配即可
public static int getLinesNum(String str)
{
int linesNum = 0;
Matcher matcher = Pattern.compile("(^|\n)\\s*\\S+").matcher(str);
while(matcher.find())
{
linesNum++;
}
return linesNum;
}
4.排序
sortMap()通过lambda表达式以及compareTo(),将存入的单词以键值(出现次数)进行排序,相同键值即采用字典序进行排序。
public List<Map.Entry<String,Integer>> sortMap()
{
List<Map.Entry<String,Integer>> wordList= new ArrayList<>(wordsMap.entrySet());
Collections.sort(wordList, (o1, o2) ->
{
if (o1.getValue().equals(o2.getValue()))
{
return o1.getKey().compareTo(o2.getKey());
}
else
{
return o2.getValue()-o1.getValue();
}
});
return wordList;
}
单元测试
例如
1.对排序的测试
@Test
public void getLinesNumTest()
{
Lib a = new Lib();
String s = Lib.readFile("input.txt");
Lib.getWordsNum(s);
List<Map.Entry<String,Integer>> list = a.sortMap();
System.out.println(list);
}
2.对读取字符数的测试
@Test
public void getLinesNumTest()
{
Lib a = new Lib();
String str = Lib.readFile("input.txt");
int b = Lib.getCharacterNum(str);
Assert.assertEquals(3,b);
}
代码覆盖率
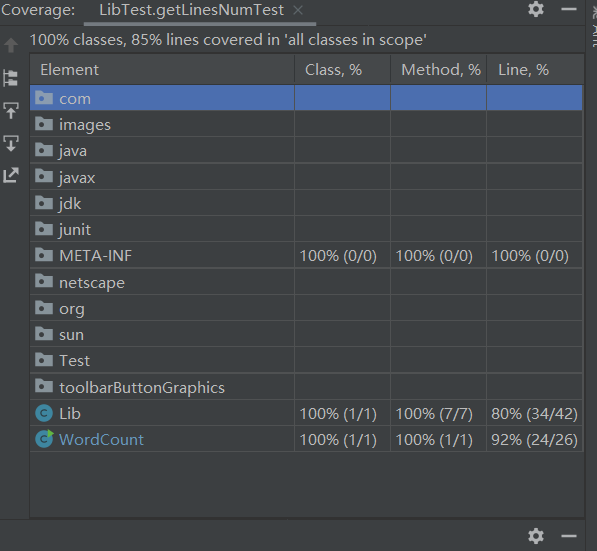
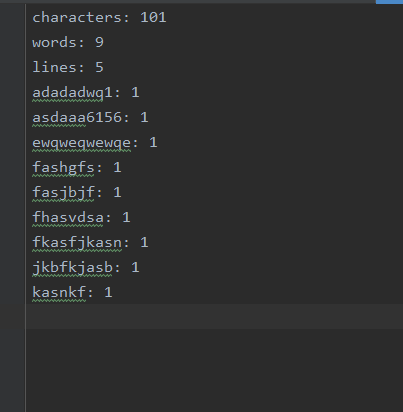
程序运行的一些结果
异常处理说明
没有可以去做异常的处理。
心路历程与收获
学到了很多东西,github之前也没有用过,这次作业的很多东西在以往的学习生活中都没有做过,以前做作业就是写程序直接提交代码完事大吉,这一次的作业让我印象十分深刻,我感觉自己遇到新的事物会有一种莫名的畏惧感,这让我不得不对自己进行了一番心理教育。软件工程这个专业,肯定是会遇到各种新问题,也要接触新的语言,一切都是未知,所以我一定会加强自己的适应能力,做到能够以一颗积极向上的心态去面对未来的挑战,字一次一次的实践中成长。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号