

Dijkstar-And-Astar算法
Dijkstra And A*
1.0 引出
2.0 Dijkstar Algorithm
2.1 整体流程
- g(n): The current best estimates of the accumulated cost from the start state to node “n”.
- Update the accumulated costs g(m) for all unexpanded neighbors “m” of node “n”.
- A node that has been expanded/visited is guaranteed to have the smallest cost from the start state.
表示的是从起点开始到当前节点的一个代价总和。 在弹出、扩展这两步的时候,弹出当前节点
,然后找到当前节点的所有孩子节点并进行扩展,此时要计算当前节点 和每个孩子节点 的一个代价值,及 , 首先如果 是没有被扩展过的节点,那么就会检测 g(m) 是否可以通过 进行下降,即把 设置成从 走到 ,看看是否新的代价 进行了下降,如果下降了则更新 。
算法是具有最优性质保证的,即保图中所有被扩展过的节点的 (从起点到当前节点的 )是最小的,这里不进行证明,设计具体的图论相关的知识,读者只需记住 算法是有完备的数学证明即可。
2.2 算法伪代码
- Mantain a priority queue to store all the nodes to be expanded。维护一个优先级队列去存储所有待扩展的节点。注意这里的优先级队列的意思,不同于之前我们在 BFS 时使用的简单队列,他对自动对当前队列中的元素进行排序,实际上在 C++ 实现的时候使用的是标准库中的 map,具体对应的是哈系表这一数据结构,学过的同学都知道他的查找效率是常数
。而我们在每次弹出的时候会自动弹出具有最小 g 值的节点。 - The priority queue is initialized with the start state
。优先级队列在初始化的时候只有一个起点 。这里其他节点(除了起点)的代价值都初始化为了无穷大,是因为我们不知道从起点能否到达该节点,因此初始化为无穷大。 - Assign
) and for all other nodes in the graph。对图中的所有初始节点进行赋值。 - Loop
- if the queue is empty; return false; 如果优先级队列是空的,则算法结束,表示没找到节点,比如说是一个迷宫,或者是个死胡同。
- Remove the node "n" with the lowest g(n) from the priority queue。从当前优先级队列中弹出 g 值最小的节点。对应了通用图搜索算法中的"弹出"。
- Mark "n" as expanded。把 "n" 标记为已经扩展过的。throw the "n" into the close set。此时 "n" 已经不会再被扩展了。
- if n is the goal node, return TRUE;break;
- For all unexpanded neighbors "m" of node "n"
- if g(m) = inifinite (说明这是一个仅仅在刚开始的时候初始化的节点,尚未被探索,则要对其进行操作)
- g(m) = g(n) + Cnm(即边的代价)
- Push node "m" into the queue(open set)将该节点添加到优先级队列中去,等待进行访问/扩展。
- if g(m) > g(n) + Cnm (如果得到的新的路径的代价值小于当前的代价值,则需要更新该节点的代价值和父节点等相关信息。
- g(m) g(n) + Cnm
- end
- END LOOP
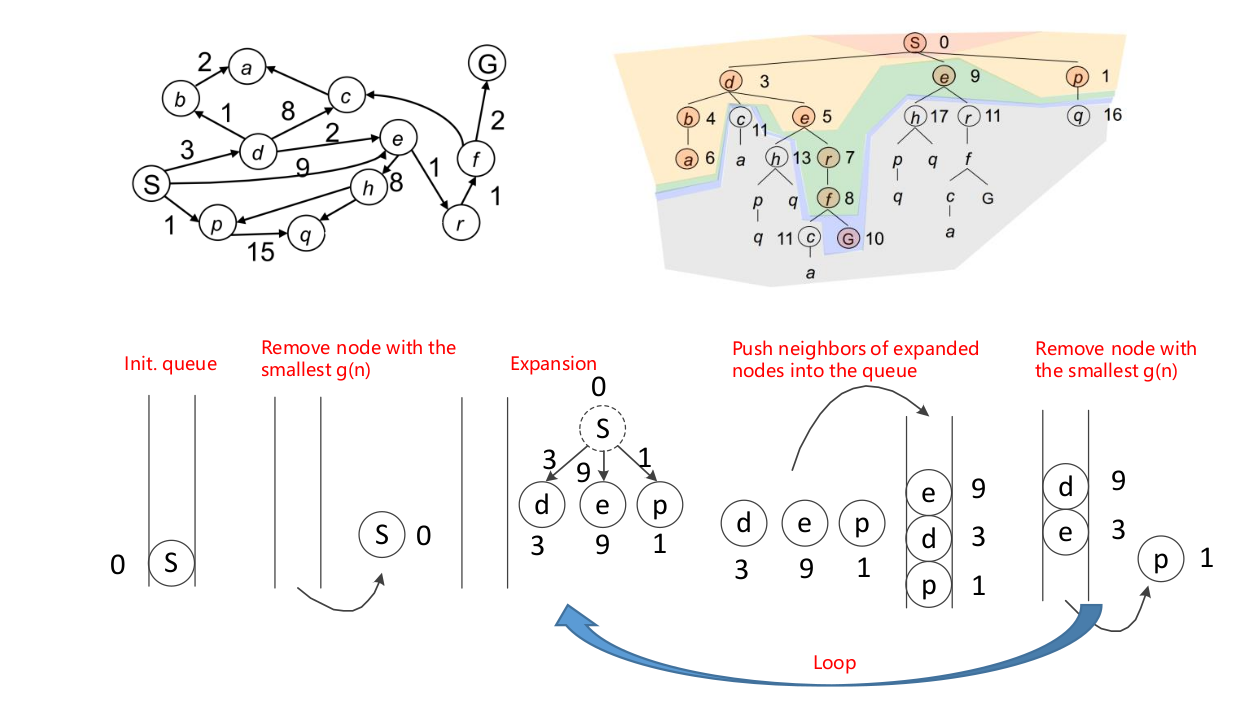
2.3 Pros and Cons of Dijkstra’s Algorithm(优缺点)
-
The Good
- Complete and optimal。完备并且是最优的,也就是说如果该问题有解,则 Dijkstar 算法一定能找到并且是最优的。
-
The Bad
-
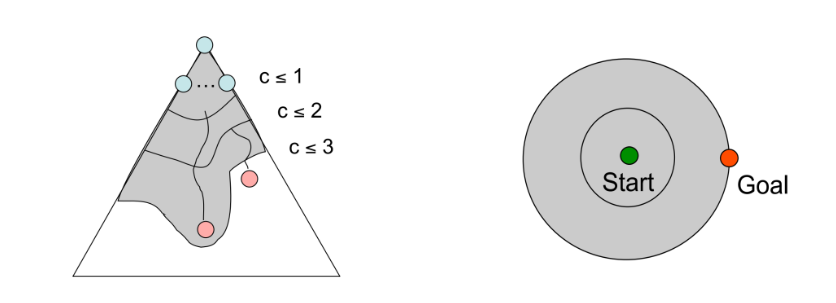
Can only see the cost accumulated so far (i.e. the uniform cost), thus exploring next state in every “direction”。
-
No information about goal location。
-
上述两个缺点体现在如下这张图上
-
3.0 A* Algorithm
3.1 启发式搜索 (Search Heuristic)
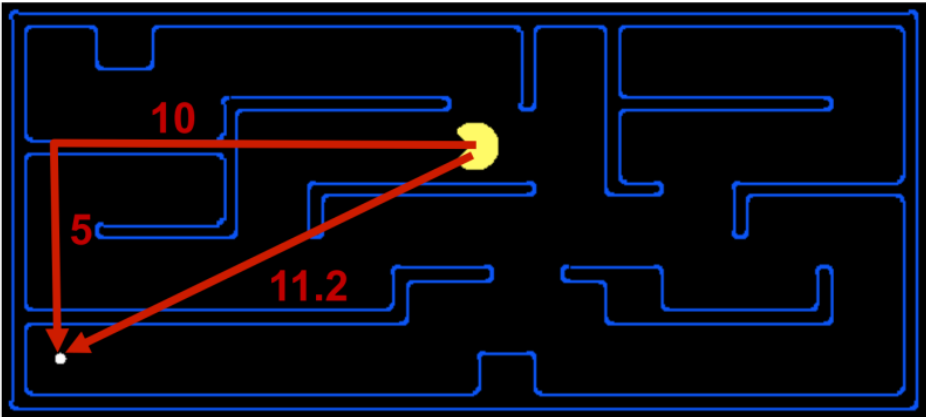
Manhattan Distance VS. Euclidean Distance
3.2 A* :Dijkstra with a Heuristic
- Accumulated cost (累计代价)
- g(n): The current best estimate of the accumulated cost from the start to end node "n"。从起始状态到节点“n”的累积成本的当前最佳估计。
- Heuristic
- h(n) : The estimated least cost from node n to goal state (i.e. goal cost)。从节点 n 到目标状态的估计最小成本(即目标成本)。
- The least estimated cost from start state to goal state passing through node “n” is f(n) = g(n) + h(n)。通过节点“n”从起始状态到目标状态的最小估计成本为 f(n) = g(n) + h(n)
- Strategy: expand the node with cheapest f(n) = g(n) + h(n)。策略:扩展最便宜的节点 f(n) = g(n) + h(n)。
- Update the accumulated costs g(m) for all unexpanded neighbors “m” of node “n”。更新节点“n”的所有未扩展邻居“m”的累积成本 g(m)
- A node that has been expanded is guaranteed to have the smallest cost from the start state。已扩展的节点保证从开始状态具有最小的成本。
A Algorithm Wokrflow*
- Mantain a priority queue to store all the nodes to be expanded。维护一个优先级队列去存储所有待扩展的节点。注意这里的优先级队列的意思,不同于之前我们在 BFS 时使用的简单队列,他对自动对当前队列中的元素进行排序,实际上在 C++ 实现的时候使用的是标准库中的 map,具体对应的是哈系表这一数据结构,学过的同学都知道他的查找效率是常数
。而我们在每次弹出的时候会自动弹出具有最小 g 值的节点。 - The priority queue is initialized with the start state
。优先级队列在初始化的时候只有一个起点 。这里其他节点(除了起点)的代价值都初始化为了无穷大,是因为我们不知道从起点能否到达该节点,因此初始化为无穷大。 - Assign
) and for all other nodes in the graph。对图中的所有初始节点进行赋值。 - Loop
- if the queue is empty; return false; 如果优先级队列是空的,则算法结束,表示没找到节点,比如说是一个迷宫,或者是个死胡同。
- Remove the node "n" with the lowest g(n) from the priority queue。从当前优先级队列中弹出 g 值最小的节点。对应了通用图搜索算法中的"弹出"。
- Mark "n" as expanded。把 "n" 标记为已经扩展过的。throw the "n" into the close set。此时 "n" 已经不会再被扩展了。
- if n is the goal node, return TRUE;break;
- For all unexpanded neighbors "m" of node "n"
- if g(m) = inifinite (说明这是一个仅仅在刚开始的时候初始化的节点,尚未被探索,则要对其进行操作)
- g(m) = g(n) + Cnm(即边的代价)
- Push node "m" into the queue(open set)将该节点添加到优先级队列中去,等待进行访问/扩展。
- if g(m) > g(n) + Cnm (如果得到的新的路径的代价值小于当前的代价值,则需要更新该节点的代价值和父节点等相关信息。
- g(m) g(n) + Cnm
- end
- END LOOP
这里也给出一个 A* 算法的整体流程,如下图所示:
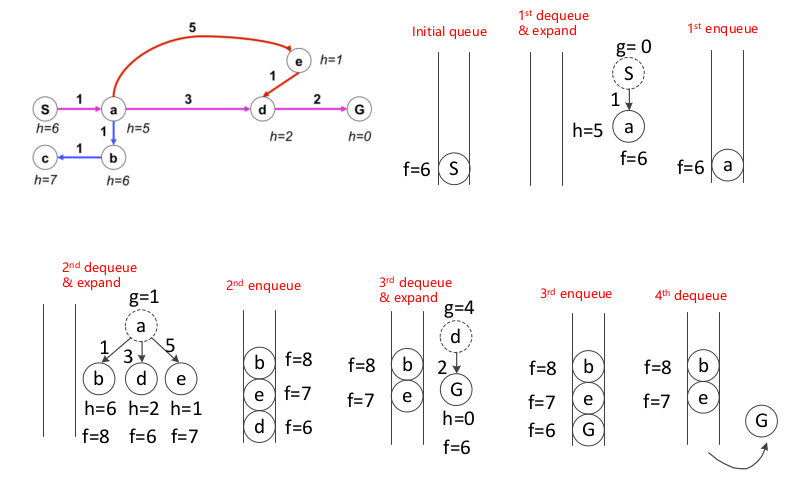
3.3 A* Optimality
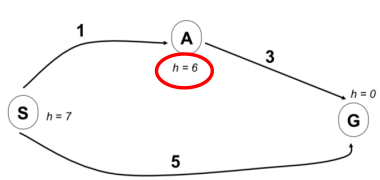
- 首先弹出节点 S
- 将 A 和 G 入队,保存到 A 和 G 的 cost 和 Heuristic。
- 计算得到
- 发现
- 是则结束搜索。
- 最终得到的最短路径是
-
The answer is:
启发式函数所估计出的 cost 要至少是小于等于真正的 cost。而是否真正的合理有的时候还要根据机器人的一个运动学模型来进行选择,例如对于全向轮机器人来说,欧式距离是可以的,但是曼哈顿距离则不行。上面那个例子中 A 点的 H 为 6,明显大于真实机器人距离目标点的 cost。
3.3.1 Admissible Heuristics
-
一个可以接受并进行使用的 Heuristic
对于所有的节点来说:
-
如果 heuristic 是 admissible,那么 A* 搜索算法得到的结果一定是最优的。
-
提出 Admissible Heuristics 是在实践中使用 A* 最为重要核心的部分。
-
下面是两种不同 Heuristic
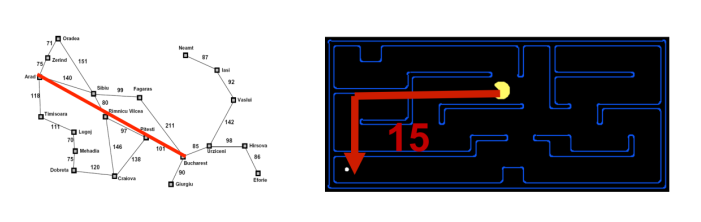
3.3.2 Heuristic Design
-
Is Euclidean distance (L2 norm) admissible?
-
Is Manhattan distance (L1 norm) admissible?
-
Is L∞ norm distance admissible?
-
Is 0 distance admissible?
3.4 Dijkstra Vs A*
- Dijkstra 算法朝着所有的方向进行扩展,不带目的性。如下图所示:

- A* 则带有目的性的进行扩展,如下图所示:

3.5 Sub-optimal Solution

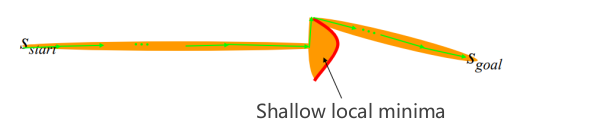
- Weighted A Search:*
- 在最优和速度之间进行折中
- 它可以比 A* 快几个数量级


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)