KIMI-VL TECHNICAL REPORT
Kimi-VL 仅激活 2.8B 参数就能实现多项 SOTA 表现
Kimi-VL-Thinking 是其“深度思考”版本,专注于复杂长链推理,适用于科研、教学、AI agent 等场景。
背景
随着 GPT-4o 等多模态模型的发布,AI 正在向“视觉 + 语言”深度融合发展。然而开源社区在多模态模型(VLM)方面仍面临效率与能力的瓶颈。
Kimi-VL 应运而生:
- 高效 MoE 架构(2.8B 激活参数)
- 原生高分辨率视觉编码器 MoonViT
- 强大的长文本 + 视频 + 多图理解能力
- 多项 benchmark 超越 GPT-4o-mini、Qwen2.5-VL-7B 等模型
动机与方法
为什么要做 Kimi-VL?
现有开源 VLM 多采用密集架构,难以实现低成本训练、长上下文处理和复杂推理任务。
Kimi-VL 的目标 是用最小的激活参数实现最大化的视觉语言理解与推理能力,并推动开源生态迈入“长思考”时代。
总体方案
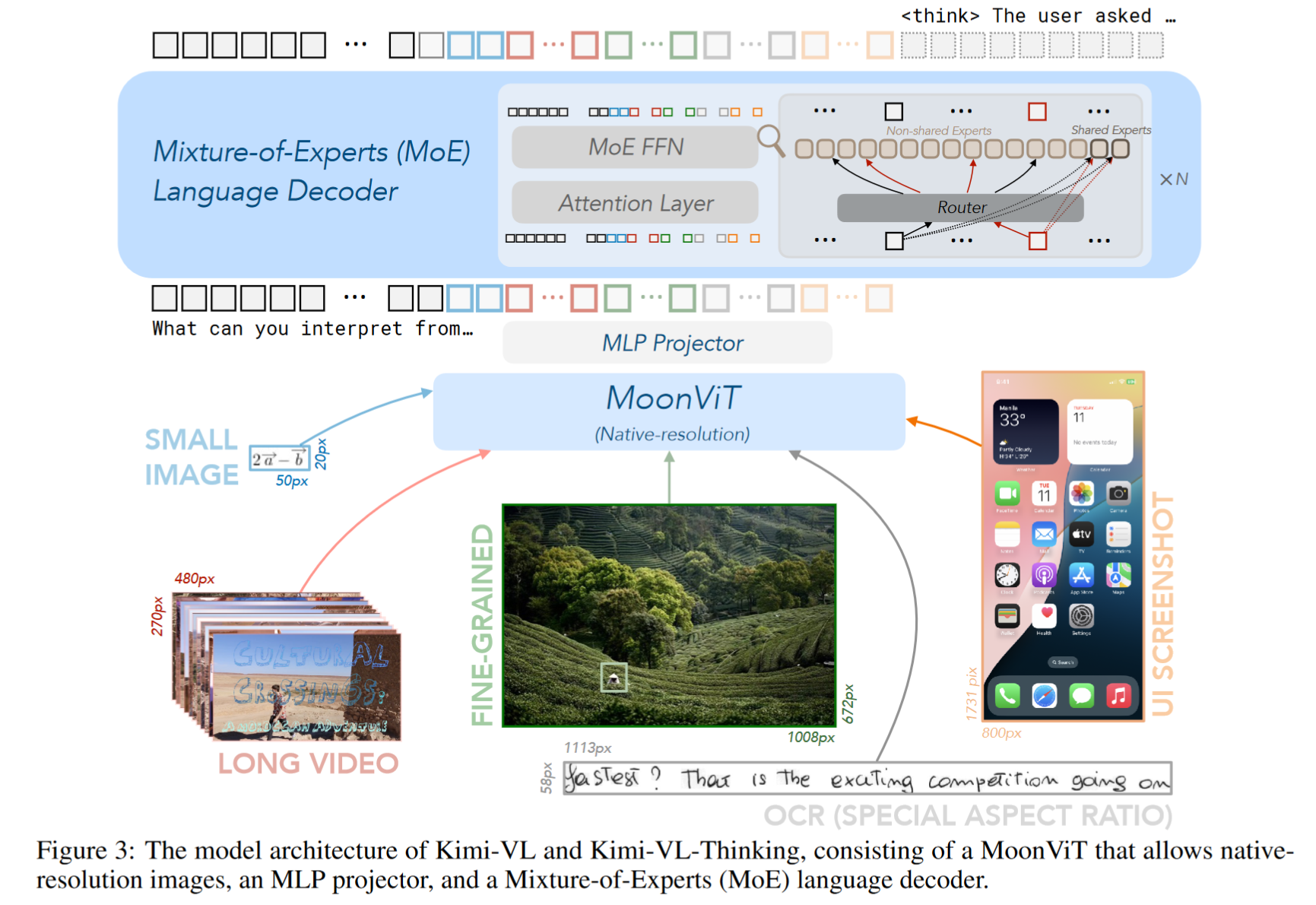
Kimi-VL 采用模块化设计,包括:
- MoonViT 视觉编码器:原生支持高分辨率图像,无需切图
- MLP Projector:桥接视觉和语言特征
- Moonlight MoE 语言模型:只激活 2.8B 参数但支持 128K 上下文
方法细节
模型结构
- Vision Encoder:MoonViT(原生分辨率、RoPE 位置编码)
- Projector:两层 MLP + Pixel Shuffle 下采样
- Language Model:Moonlight(MoE 架构、支持长上下文)
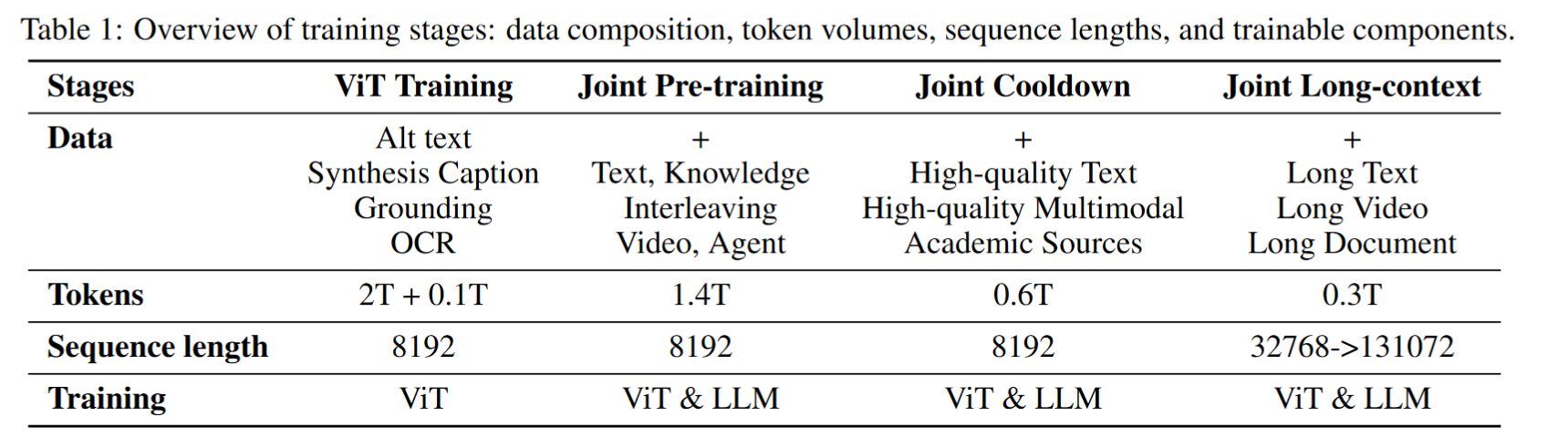
训练策略
采用渐进式多阶段训练策略:
- 纯文本预训练(5.2T tokens)
- ViT训练(图文对,采用 CoCa-style 损失)
- 联合预训练(多模态+文本,1.4T)
- 冷却阶段(高质量合成数据,提升数学/代码能力)
- 长上下文激活(最长支持 128K)

后训练阶段
- 指令微调(SFT):提升对话/交互能力
- 长链式思维微调(Long-CoT):构建思考路径
- 强化学习(RL):强化推理质量与紧凑性

实验设计与结果
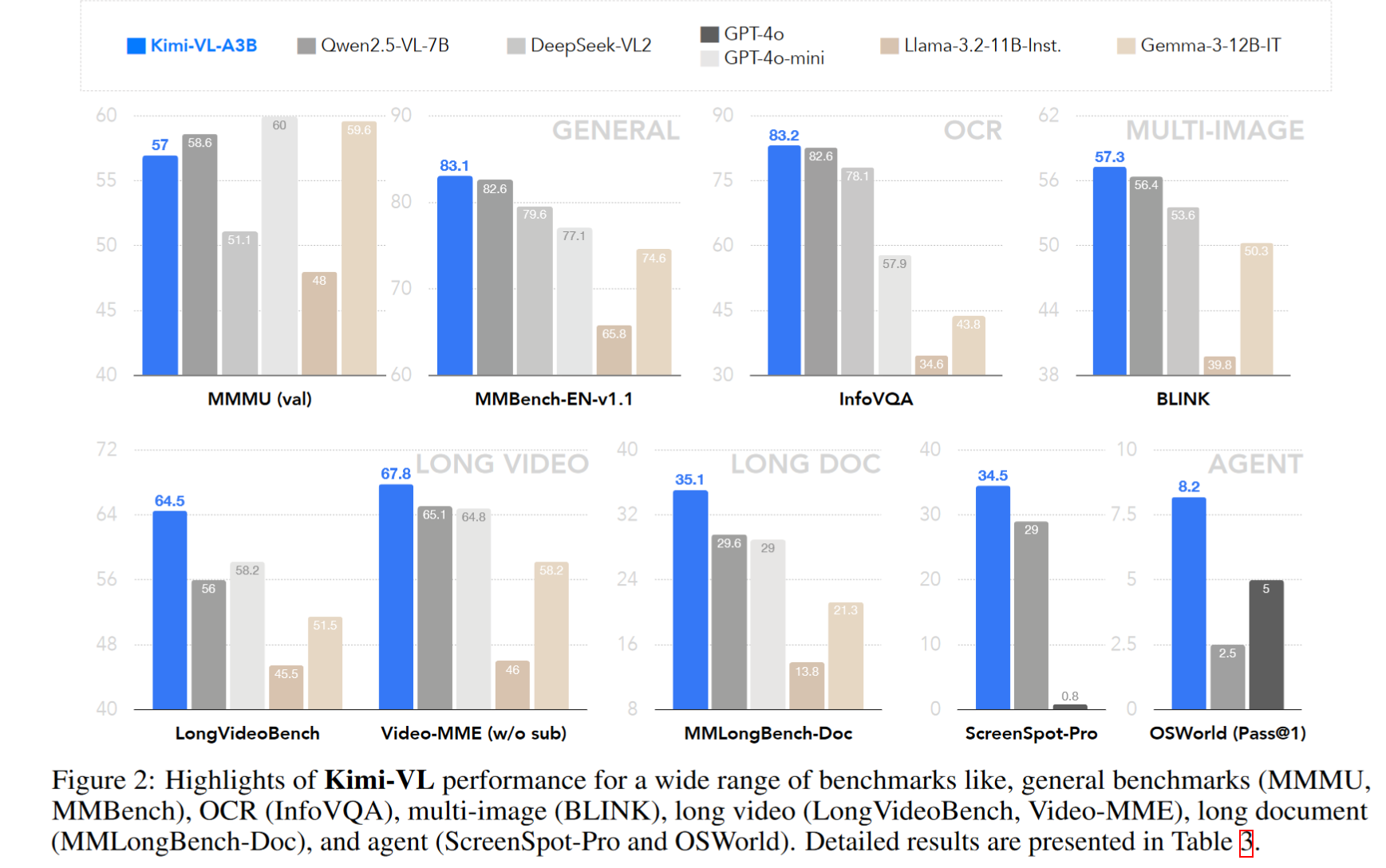
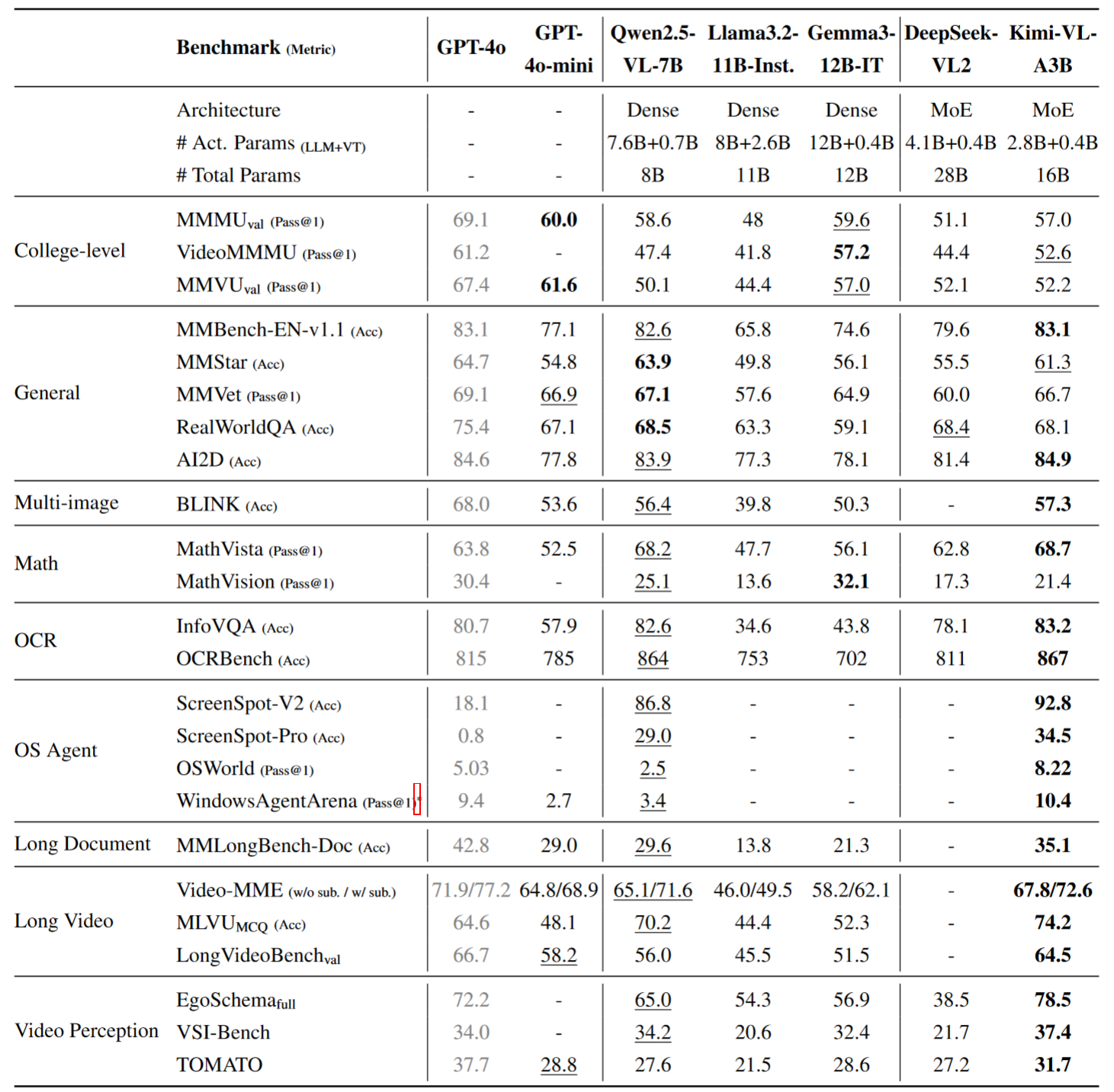
综合表现
Kimi-VL 在 24 个主流任务中有 19 项超越 Qwen2.5-VL-7B,且激活参数仅为其 1/2。
- MMBench-EN(常规视觉问答):83.1%,与 GPT-4o 持平
- MathVista(视觉数学):68.7%,超过 GPT-4o
- OCR(InfoVQA):83.2%,全场最佳
- 长文档(MMLongBench-Doc):35.1%,领先同类
- 长视频理解(LongVideoBench):64.5%,紧随 GPT-4o
总结与讨论
Kimi-VL 成功实现了三项关键突破:
- 小而强大:仅激活 2.8B 参数
- 长而清晰:支持 128K 上下文、原生高分图像处理
- 推理能力强:通过 Long-CoT 与 RL 实现复杂多步思考 (可能是以后的主要发力点)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号