
Qwen2.5-VL Tech Report
https://arxiv.org/abs/2502.13923
https://github.com/QwenLM/Qwen2.5-VL
-
背景介绍
目前VLMs虽然能胜任各类任务,却难以像LLM那样达到卓越表现。主要发展瓶颈在于:计算复杂度、有限的上下文理解能力、细粒度视觉感知能力差、输出序列长度敏感。
针对这些问题,新一代的Qwen2.5-VL致力于探索细粒度的感知能力,旨在建立一个鲁棒的VLMs基座。Qwen2.5-VL静态的图像和文本理解能力出色,同时作为Visual Agent 支持在现实场景中进行推理、使用工具、操作设备等。
相比于上一代在视觉识别、精细定位、文档解析和长视频理解方面具有显著提升。
-
- 强大的文档解析能力:Qwen2.5-VL将文本识别升级为全文档解析,能够出色处理多场景、多语言以及包含手写体、表格、图表、化学公式、乐谱等复杂文档。
-
- 精确的定位能力:Qwen2.5-VL显著提升了物体检测、定位与计数的精度,支持绝对坐标和JSON格式输出
-
- 超长视频理解与细粒度视频定位能力:将态分辨率扩展至时间维度,既可高效解析数小时的视频内容,又能在、锁定秒级关键事件片段
-
- 增强的Agent能力:融合先进的定位、推理及决策能力
-
模型结构
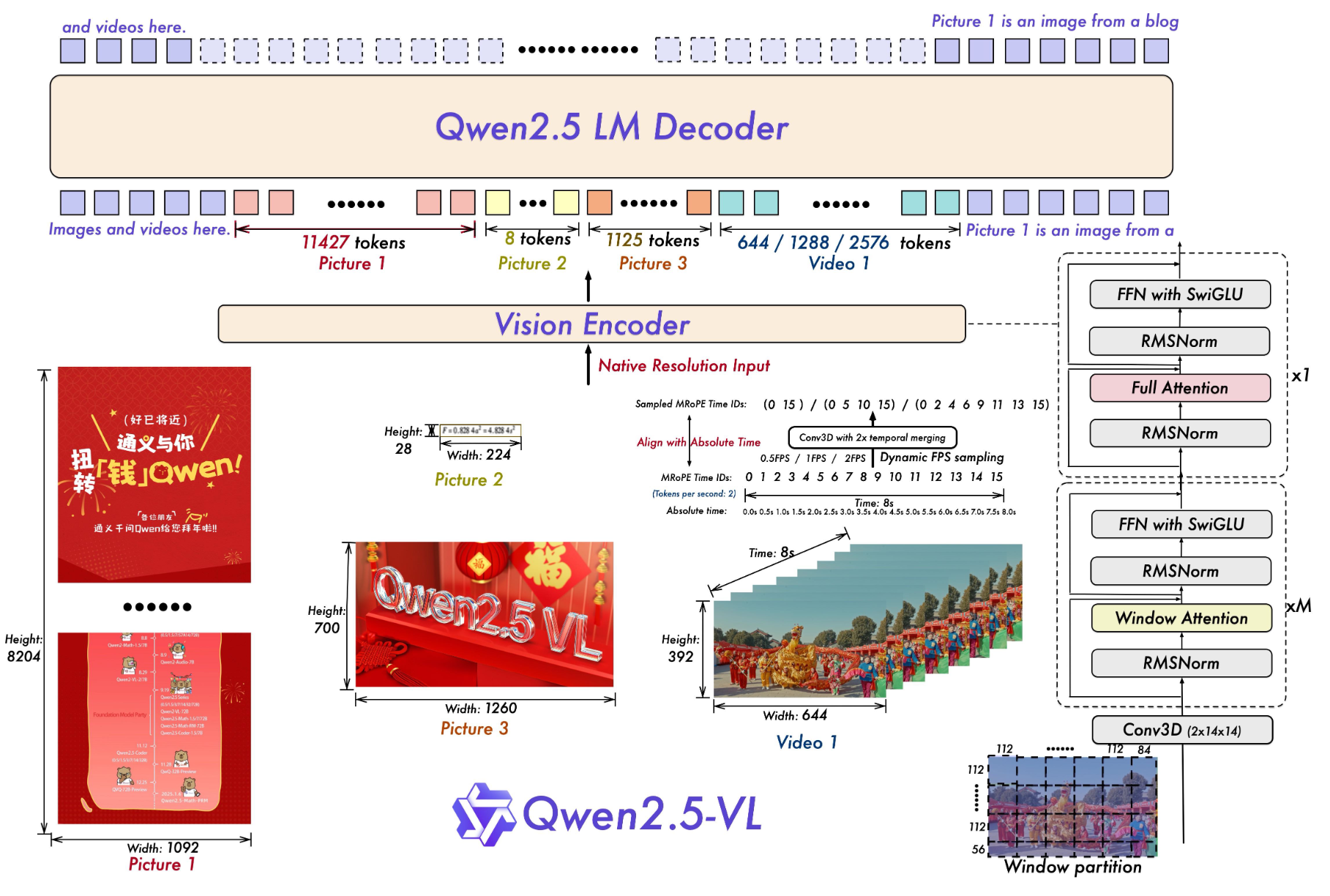
相比于Qwen2-VL的改进:
-
- 在视觉编码器中引入窗口注意力机制以优化推理效率(支持原生分辨率输入)
-
- 动态帧率采样技术,将动态分辨率扩展至时间维度,使得模型能够兼容不同采样频率并实现对视频内容的全方位理解
-
- 升级MRoPE,在时序维度上对齐绝对时间轴,增强对于复杂时间序列的学习能力
-
- 在预训练和监督微调阶段投入大量高质量训练数据,将预训练语料库规模从 1.2T tokens 扩展至 4.1T tokens。
-
高效视觉编码器
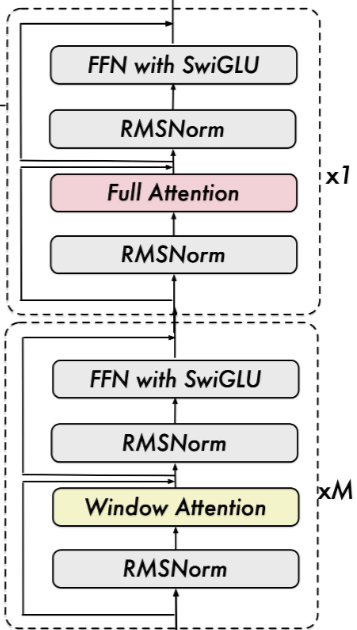
-
采用原生分辨率:原始ViT的Attention计算复杂度与序列长度成平方关系。因此在大多数layer中使用window_attention(8*8),复杂度降低到 O(n)
-
LLM更好的对齐:提高视觉模型计算效率和与LLM的兼容性。采用RMSNorm进行归一化,SwiGLU进行激活
-
Train from scratch:CLIP预训练方式、视觉语言对齐、端到端微调、动态采样不同原生分辨率的图像
-
动态分辨率和帧率
-
与传统的归一化坐标的方法不同,Qwen2.5-VL直接使用输入图像的实际尺寸来表示边界框、点和其他空间特征
-
针对视频输入,结合动态帧率训练和绝对时间编码。直接将MRoPE ID与视频时间戳对齐,使模型能通过时序维度感知时间节奏,在不增加额外计算开销的前提下实现视频内容的精准时间轴定位能力
-
MRoPE
Qwen2-VL的MRoPE通过将位置编码分解为三个独立维度——时间维度、高度维度和宽度维度
-
对于文本输入,三个维度均采用相同的统一位置ID,此时MRoPE在功能上等同于传统的1D旋转位置嵌入
-
在图像处理中,所有视觉token的时间维度ID保持恒定,而高度与宽度维度则根据每个token在图像中的具体空间位置分配唯一ID;
-
当处理视频时(视频被视作连续帧的序列),时间维度ID逐帧递增,而高度和宽度维度的ID分配逻辑与静态图像一致。(每秒采样两帧)
局限性:其时间维度位置ID仅与输入帧数相关联,未能充分捕捉视频内容变化速率或事件发生的具体绝对时间
Qwen2.5-VL提出了一项核心改进——将MRoPE的时间维度组件与绝对时间轴对齐,通过时间维度ID间的间隔映射,模型能够跨不同帧率采样率的视频学习到一致的时序对齐关系,从而更精确地理解动态内容的节奏与事件时间戳。
-
Pre-training
-
预训练数据
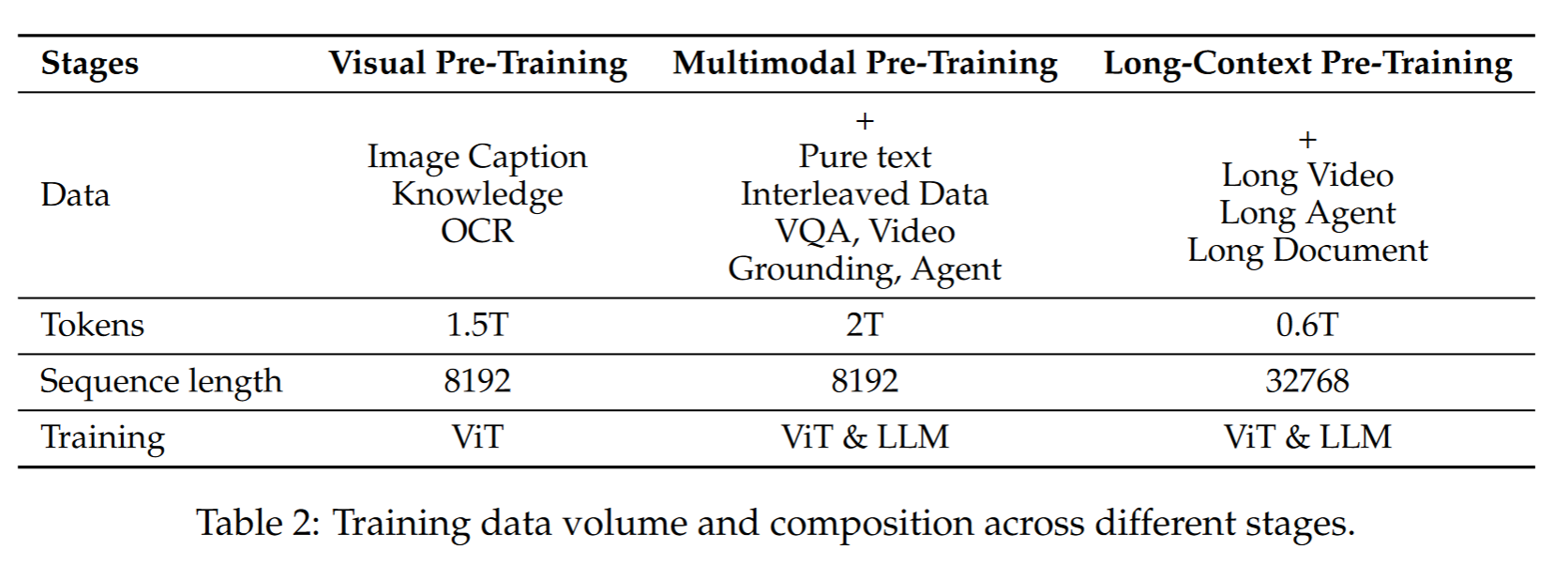
预训练tokens:Qwen2-VL(1.2 T) -> Qwen2.5-VL(4.1T),数据类型包括:图像描述、交错图文数据、OCR数据、视觉知识(如名人、地标、动植物识别等)、多模态学术问答、定位数据、文档解析数据、视频描述与时间定位、基于智能体的交互数据
-
图文相关数据:现有大量交错图文数据存在严重缺陷:缺乏有意义的图文关联且往往存在噪声。1)采用传统数据清洗技术。2)运用内部评估模型对数据进行分级筛选,评分维度包括:纯文本质量、图文相关度、信息互补性、信息密度平衡度
-
绝对位置的定位数据:基于输入图像的实际尺寸生成坐标值,构建了一个包含bbox与point的综合型定位数据集,将训练数据集扩展至覆盖超过10000种目标物体类别
-
文档解析数据:统一的HTML格式,通过绝对坐标与HTML语义的结合,强化模型在文档解析任务中的细粒度空间推理与模态融合能力
-
OCR数据:引入了一个大型多语言OCR数据集,合成100万张图样本,处理了600万份表格样本
-
视频数据:动态调整采样频率 ,使训练数据集的FPS分布更均衡,针对时长超过半小时的长视频构建了多帧连贯描述,在视频定位任务中,时间戳以秒级和小时-分钟-秒-帧格式双重标注
-
Agent 数据:
-
收集了多平台的截屏数据,并且生成截屏描述和UI元素定位描述
-
统一动作空间:Function Call格式
-
轨迹数据的收集和标注:包括开源的数据和Agent在虚拟空间中生成的数据
-
推理增强:对于每一个step,提供给标注者整体query及当前动作的前后截图,标注动作意图和推理过程
-
-
训练流程
-
- train ViT from scratch (DataComp+内部数据集)
-
- ViT对齐
-
- 解冻所有参数,在多样化数据集训练
-
- 解冻所有参数,在长序列、复杂任务上训练,并扩展最大序列长度
-
Post-training
-
指令数据集SFT
数据集组成:
-
该数据集包含约200万条指令,其中50%为纯文本数据,50%为多模态数据(包含图文、视频文本组合)
-
结构呈现不同对话复杂度,包括单轮对话 和多轮交互 ,且交互场景涉及单图输入、多图序列等
-
包含针对VQA 、caption、math、code等通用多模态数据集。
-
构建了面向OCR 、Grounding 、视频分析(Video Analysis)及Agent的专用数据集
两阶段数据清洗流程:
-
- 特定领域分类,利用Qwen2-VL-Instag模型将不同的QA对划分为8个大类30小类
-
- 针对每一个子类进行数据清洗:基于规则(过滤不完整或者不符合格式的数据),随后基于Reword Model进行多维度打分(query的复杂性和相关性,answer的正确性、完整性、清晰性、相关性等)
-
拒绝采样增强推理能力
先前研究表明,引入思维链(Chain-of-Thought, CoT)推理能显著提高模型的推断性能。基于已标注的数据,Qwen2.5-VL 通过拒绝采样策略来优化数据集并提升推理能力,对复杂推理的任务提升明显
借助Qwen2.5-VL中间版本模型进行COT增强,将其生成的回复与真实答案进行比对,仅保留模型输出与预期答案一致的样本。为保障CoT的清晰性和连贯性,附加约束条件过滤低质量输出:限制过长的文本输出、重复文本等
-
训练流程
后训练过程中,均冻结ViT
-
SFT:基于通用多模态数据集、增强数据集和专有数据集进行训练
-
DPO:与人类偏好保持一致,每个样本仅处理一次
-
实验分析
-
VQA
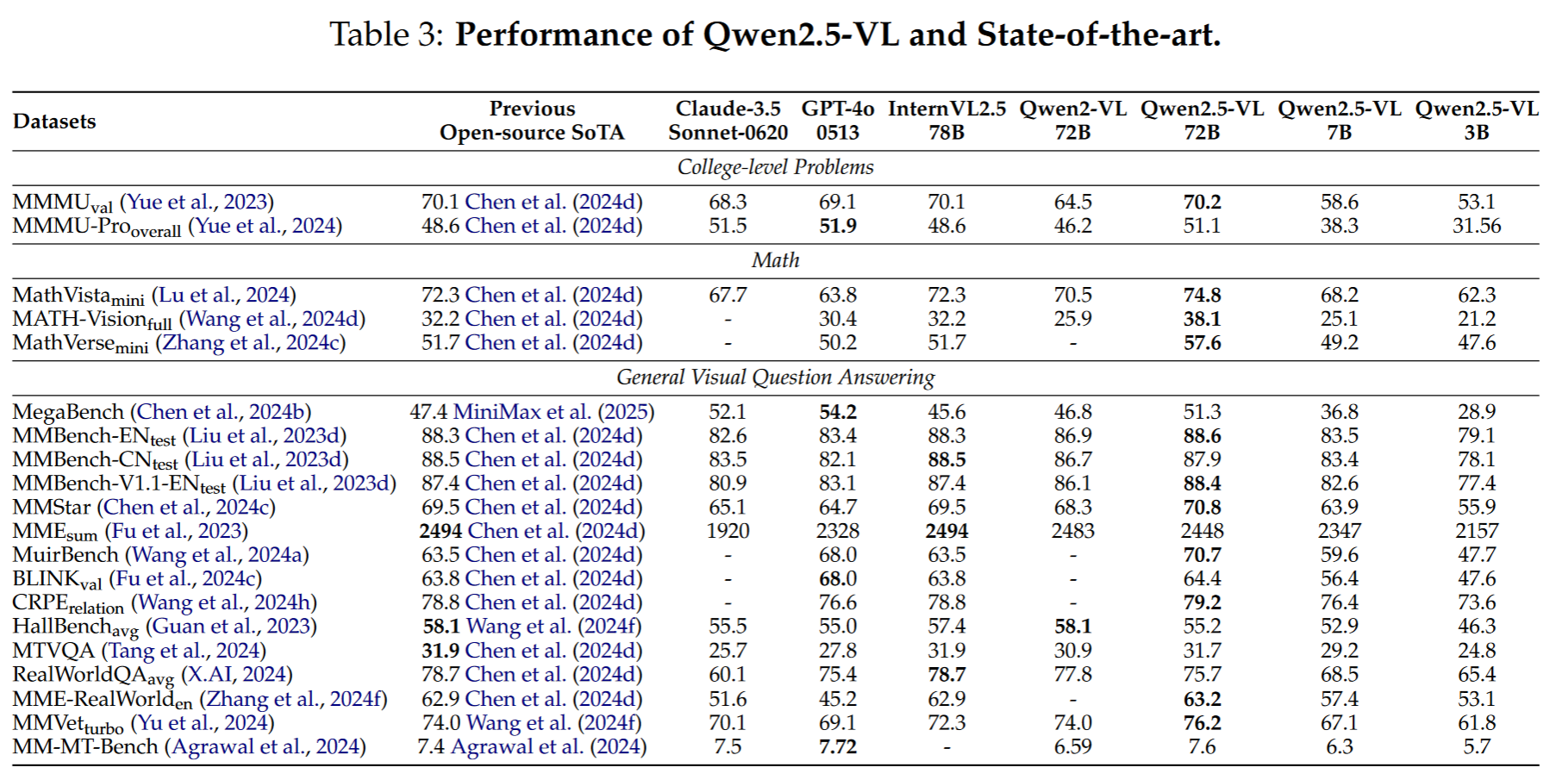
在MMMU和MMMU-Pro上与Claude-3.5-Sonnet-0620和GPT-4o0513持平,相比于Qwen2VL-72B明显提升
-
文档理解和OCR
-
图像理解和定位
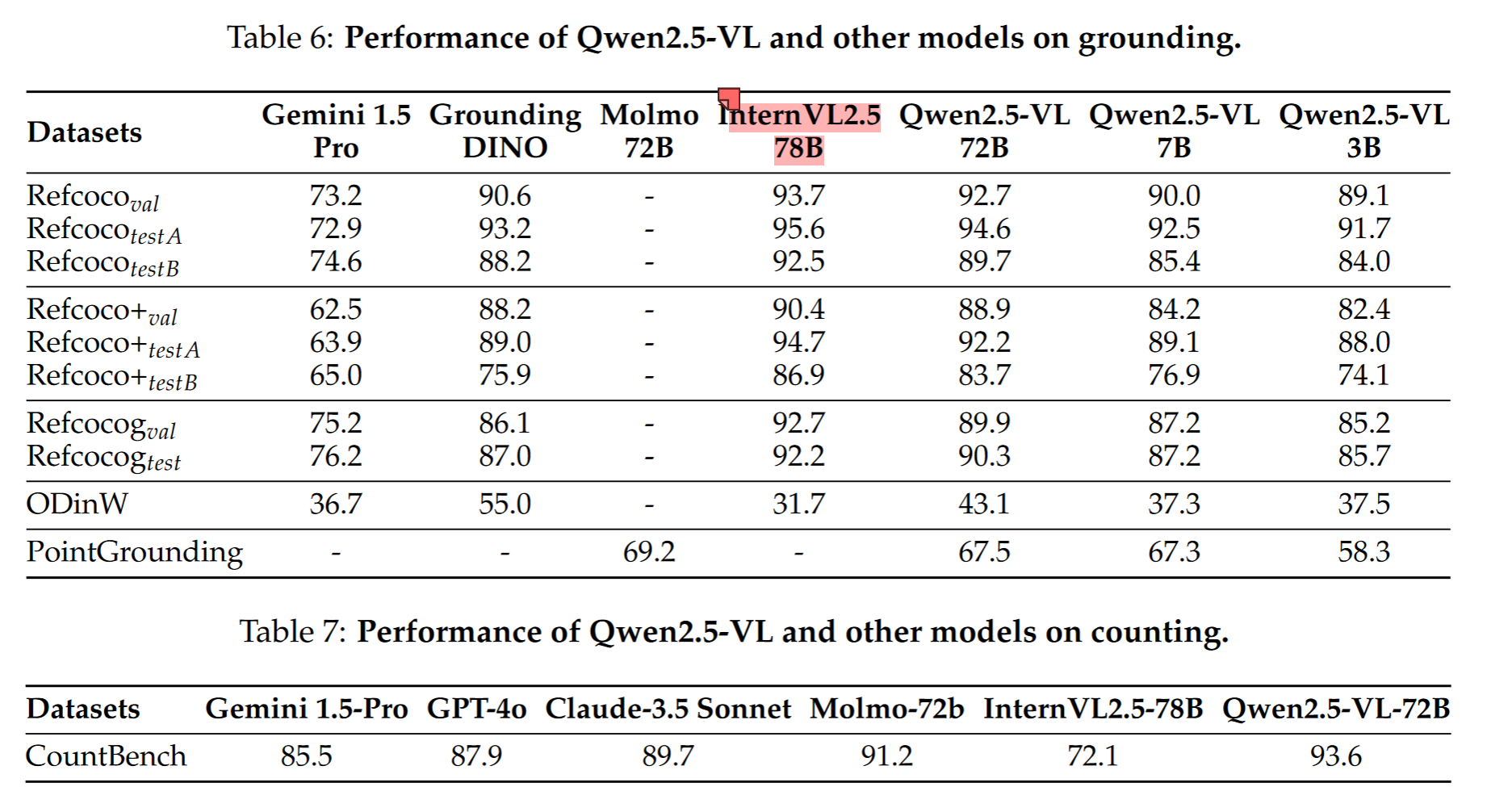
grounding方面:与Gemini, Grounding-DINO模型相比,在bbox-grounding,point-grounding和counting上取得领先性能,但是落后于InternVL2.5-78B
在基于VQA的长视频理解方面,显著优于GPT-4o
-
Agent
-
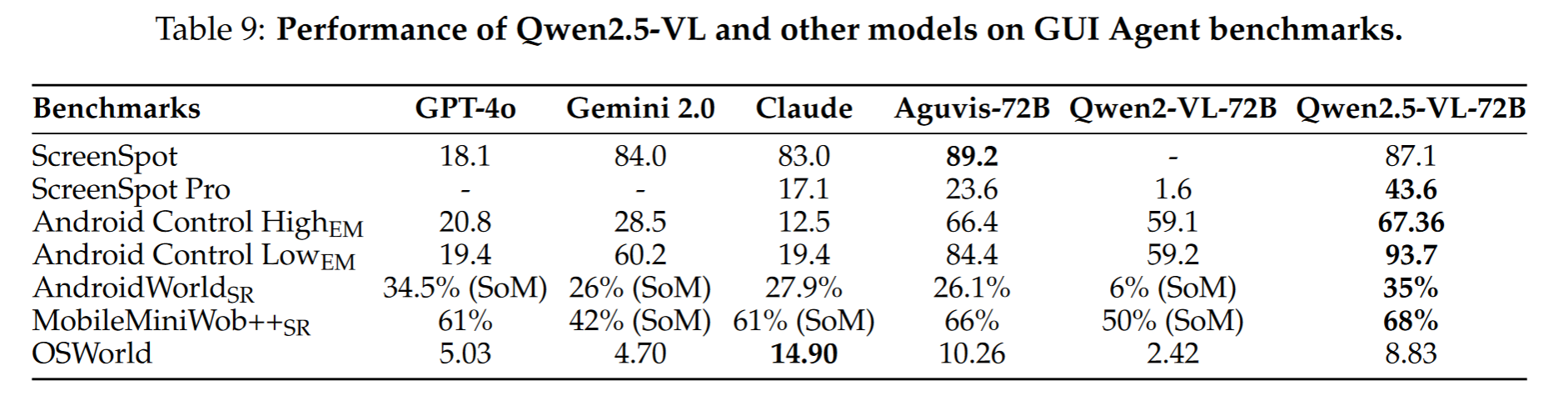
定位(ScreenSpot):定位能力大幅度领先闭源商业模型
-
离线评估(Android Control):大幅度领先
-
在线评估:复杂任务(OSWorld)不及Claude

 浙公网安备 33010602011771号
浙公网安备 33010602011771号