
How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites

InternVL1.5: 更强的视觉编码器,动态处理高分辨率图像,高质量的双语数据集。
主要内容
对标商业模型,提出InternVL1.5。更强的视觉编码器(InternViT-6B),动态处理高分辨率图像(将图像分成448*448的tails,最高支持4K分辨率),高质量的双语数据集(显著提高了OCR和中文相关任务的性能)。与开源和商业模型相比,在 8/18 个多模态benchmark上sota。
动机和方法
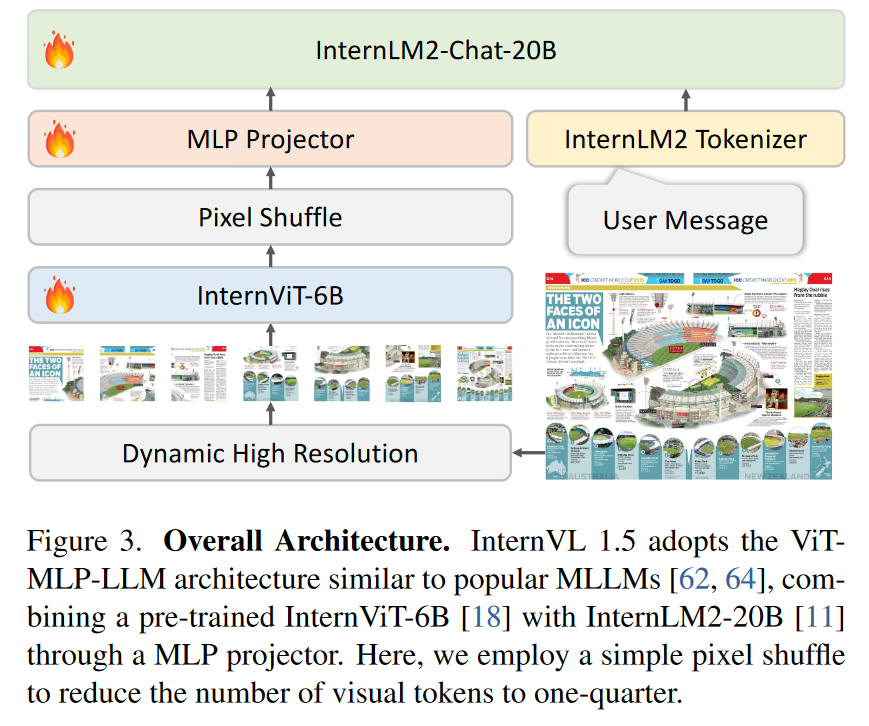
- Dynamic High-Resolution & Pixel Shuffle
受UReader的启发,我们采用了一种动态的高分辨率训练方法,可以有效地适应输入图像的分辨率和宽高比的变化。该方法利用了图像分块的灵活性,增强了模型对细节的处理能力。
Pixel Shuffle减少了Image tokens(1024 -> 256)。

-
Two Stage Training
第一阶段微调ViT+Projector,第二阶段微调ViT+Projector+LLM -
High-Quality Bilingual Dataset
包含了大量的图文数据集,提供了一个数据翻译的pipeline

实验分析
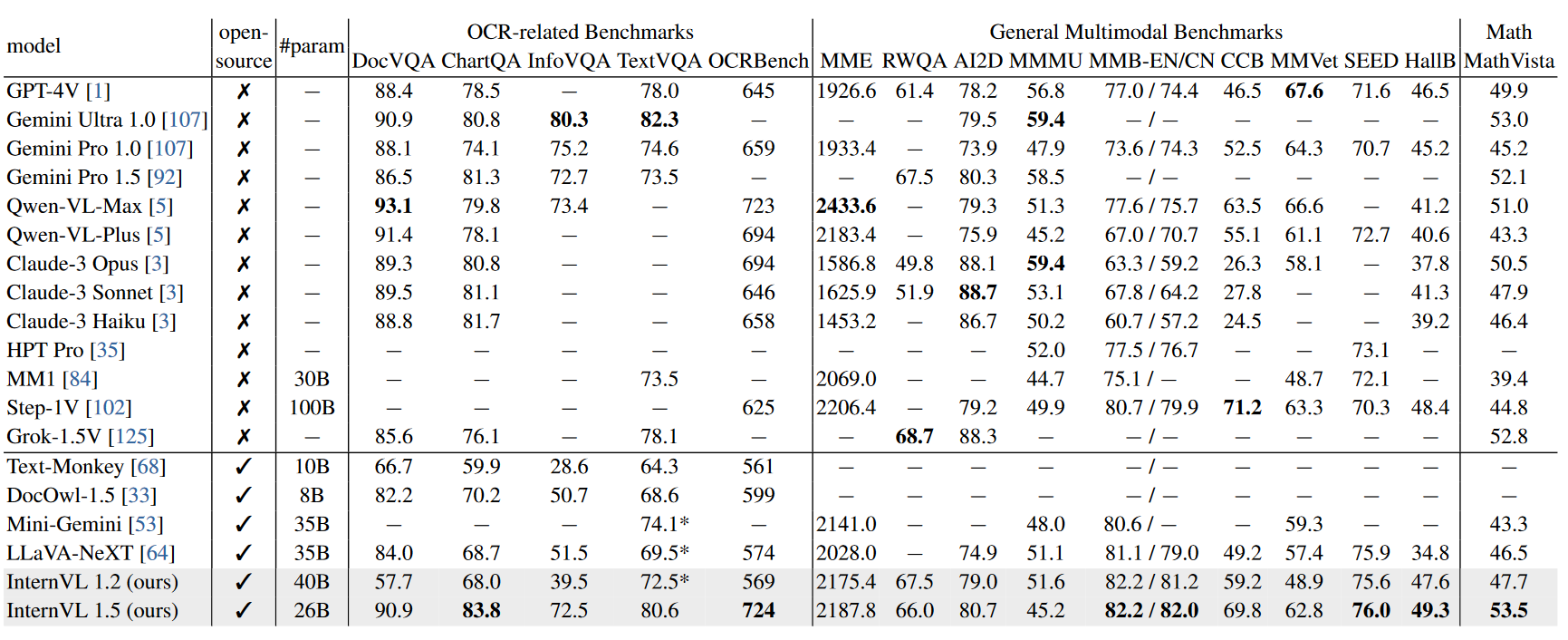
在OCR任务上表现出色,

总结
开源做的很好,大量的pretrain datasets和benchmark,一般人也做不来
本文作者:WeihangZhang
本文链接:https://www.cnblogs.com/weihangzhang/p/18678454
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。
分类:
标签:



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步