

从不同的的角度去划分垃圾回收算法。
按照基本回收策略分
引用计数(Reference Counting)
比较古老的回收算法。原理是此对象有一个引用,即增加一个计数,删除一个引用则减少一个计数。垃圾回收
时,只用收集计数为0的对象。此算法最致命的是无法处理循环引用的问题。
标记-清除(Mark-Sweep)

此算法执行分两阶段。第一阶段从引用根节点开始标记所有被引用的对象,第二阶段遍历整个堆,把未标记的
对象清除。此算法需要暂停整个应用,同时,会产生内存碎片。
复制(Copying)

此算法把内存空间划为两个相等的区域,每次只使用其中一个区域。垃圾回收时,遍历当前使用区域,把正在
使用中的对象复制到另外一个区域中。次算法每次只处理正在使用中的对象,因此复制成本比较小,同时复制
过去以后还能进行相应的内存整理,不会出现“碎片”问题。当然,此算法的缺点也是很明显的,就是需要两
倍内存空间。
标记-整理(Mark-Compact)

此算法结合了“标记-清除”和“复制”两个算法的优点。也是分两阶段,第一阶段从根节点开始标记所有被引
用对象,第二阶段遍历整个堆,把清除未标记对象并且把存活对象“压缩”到堆的其中一块,按顺序排放。此
算法避免了“标记-清除”的碎片问题,同时也避免了“复制”算法的空间问题。
按分区对待的方式分
增量收集(Incremental Collecting)
实时垃圾回收算法,即:在应用进行的同时进行垃圾回收。不知道什么原因JDK5.0中的收集器没有使用这种算法的。
分代收集(Generational Collecting)
基于对对象生命周期分析后得出的垃圾回收算法。把对象分为年青
代、年老代、持久代,对不同生命周期的对象使用不同的算法(上述方式中的一个)进行回收。现在的垃圾回
收器(从J2SE1.2开始)都是使用此算法的。
按系统线程分
串行收集
串行收集使用单线程处理所有垃圾回收工作,因为无需多线程交互,实现容易,而且效率比较高。但
是,其局限性也比较明显,即无法使用多处理器的优势,所以此收集适合单处理器机器。当然,此收集器也可
以用在小数据量(100M左右)情况下的多处理器机器上。
并行收集
并行收集使用多线程处理垃圾回收工作,因而速度快,效率高。而且理论上CPU数目越多,越能体现出并行收集器的优势。
并发收集
相对于串行收集和并行收集而言,前面两个在进行垃圾回收工作时,需要暂停整个运行环境,而只有
垃圾回收程序在运行,因此,系统在垃圾回收时会有明显的暂停,而且暂停时间会因为堆越大而越长。
如何区分垃圾
上面提到“引用计数”法,通过统计控制生成对象和删除对象时的引用数来判断。垃圾回收程序收集计数
为0的对象即可。但是这种方法无法解决循环引用。所以,后来实现的垃圾判断算法中,都是从程序运行的根节
点出发,遍历整个对象引用,查找存活的对象。那么在这种方式的实现中,垃圾回收从哪儿开始的呢?即,从
哪儿开始查找哪些对象是正在被当前系统使用的。上面分析的堆和栈的区别,其中栈是真正进行程序执行地
方,所以要获取哪些对象正在被使用,则需要从Java栈开始。同时,一个栈是与一个线程对应的,因此,如果
有多个线程的话,则必须对这些线程对应的所有的栈进行检查。
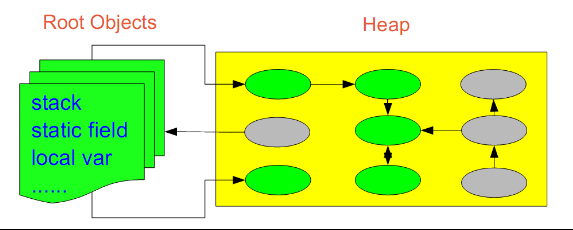
同时,除了栈外,还有系统运行时的寄存器等,也是存储程序运行数据的。这样,以栈或寄存器中的引用为
起点,我们可以找到堆中的对象,又从这些对象找到对堆中其他对象的引用,这种引用逐步扩展,最终以null引
用或者基本类型结束,这样就形成了一颗以Java栈中引用所对应的对象为根节点的一颗对象树,如果栈中有多
个引用,则最终会形成多颗对象树。在这些对象树上的对象,都是当前系统运行所需要的对象,不能被垃圾回
收。而其他剩余对象,则可以视为无法被引用到的对象,可以被当做垃圾进行回收。
因此,垃圾回收的起点是一些根对象(java栈, 静态变量, 寄存器...)。而最简单的Java栈就是Java程序执行的
main函数。这种回收方式,也是上面提到的“标记-清除”的回收方式。
如何处理碎片
由于不同Java对象存活时间是不一定的,因此,在程序运行一段时间以后,如果不进行内存整理,就会出现零
散的内存碎片。碎片最直接的问题就是会导致无法分配大块的内存空间,以及程序运行效率降低。所以,在上
面提到的基本垃圾回收算法中,“复制”方式和“标记-整理”方式,都可以解决碎片的问题。
如何解决同时存在的对象创建和对象回收问题
垃圾回收线程是回收内存的,而程序运行线程则是消耗(或分配)内存的,一个回收内存,一个分配内存,
从这点看,两者是矛盾的。因此,在现有的垃圾回收方式中,要进行垃圾回收前,一般都需要暂停整个应用
(即:暂停内存的分配),然后进行垃圾回收,回收完成后再继续应用。这种实现方式是最直接,而且最有效
的解决二者矛盾的方式。
但是这种方式有一个很明显的弊端,就是当堆空间持续增大时,垃圾回收的时间也将会相应的持续增大,对应
应用暂停的时间也会相应的增大。一些对相应时间要求很高的应用,比如最大暂停时间要求是几百毫秒,那么
当堆空间大于几个G时,就很有可能超过这个限制,在这种情况下,垃圾回收将会成为系统运行的一个瓶颈。为
解决这种矛盾,有了并发垃圾回收算法,使用这种算法,垃圾回收线程与程序运行线程同时运行。在这种方式
下,解决了暂停的问题,但是因为需要在新生成对象的同时又要回收对象,算法复杂性会大大增加,系统的处
理能力也会相应降低,同时,“碎片”问题将会比较难解决。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号