
Python基础
一. Python简介
1. 解释型与编译型语言的区别:
解释型:代码从上到下一行一行解释并执行。
语言:Python,PHP
优点:开发效率块,调试周期短
缺点:执行速度相对慢
编译型:一次性把所有代码编译成机器能识别的二进制码,然后再运行。
语言:C,C++
优点:执行速度快
缺点:开发速度慢,调试周期长
2. Python解释器
(1)CPython(官方推荐)
把python转化成C语言能识别的二进制码
(2)JPython
把python转化成Java语言能识别的二进制码
(3)其他语言解释器
把python转化成其他语言能识别的二进制码
(4)Pypy
将所有代码一次性编译成二进制码,加快执行效率(模仿编译型语言的一款python解释器)
二. Python基础1
1. python六大标准数据类型
(1)number 数字类型(int float bool complex)
int: 整数类型 (正整数 0 负整数)
float: 浮点数类型 (普通小数 科学技术法表示的小数 如:2e-5)
bool: 布尔类型 (真True 假False)
complex: 复数类型 (复数用在科学计算中,表示高精度的数据)
(2)str 字符串类型
(3)list 列表类型
(4)tuple 元组类型
(5)set 集合类型
(6)dict 字典类型
容器类型数据:str list tuple set dict
2. 自动类型转换
当两个不同类型的数据进行运算的时候,默认向更高精度转换
数据类型精度从低到高:bool --> int --> float --> complex
3. 强制类型转换
(1)number类型
int: 整型 浮点型 布尔型 纯数字字符串
float: 整数 浮点型 布尔型 纯数字字符串
complex:整数 浮点型 布尔型 纯数字字符串
bool: 容器类型数据 number类型
(2)容器类型
str: 字符串类型 number类型
list: 字符串 列表 元组 集合 字典
tuple: 字符串 列表 元组 集合 字典
set: 字符串 列表 元组 集合 字典
dict: 二级列表 二级元组 二级集合(里面的容器类型只能是元组)
4. 哈希算法
(1)定义:把不可变的任意长度值计算成固定长度的唯一值,这个值可正可负、可大可小,但长度固定,该算法叫哈希算法(散列算法),这个固定长度值叫哈希值(散列值)。
(2)特点:值长度固定且唯一;该字符串是密文,加密过程不可逆。
(3)用途:比对两个文件内容是否一致;比对密码
(4)字典的键和集合的值都是唯一值(可哈希数据),不可重复
(5)可哈希数据:
可哈希数据(值不可变):Number类型(int、float、bool、complex)、str、tuple
不可哈希数据(值可变):list、set、dict
5. Python运算符
(1)算术运算符:+ - * / // % **
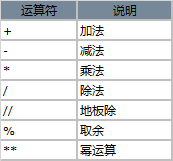
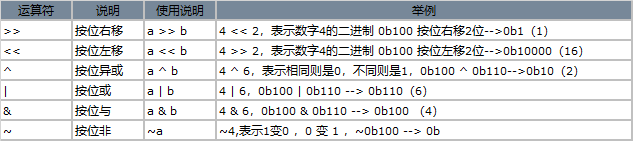
(2)位运算符: >> << ^ | & ~
(3)比较运算符:> < >= <= == !=
(4)身份运算符:is is not(检测两个数据在内存中的地址是否一样)
(5)成员运算符:in not in(针对容器数据类型)
(6)逻辑运算符:and or not
运算符优先级:算术运算符 > 位运算符 > 比较运算符 > 身份运算符 > 成员运算符 > 逻辑运算符
6. 数据在内存中的缓存机制
(1)同一文件(模块)中(仅对python3.6)
Number:
int: -5 ~ 正无穷 相同值,id一致
float: 非负整数 相同值,id一致
bool: 相同值,id一致
complex: 实数+虚数(id永不相同)(只有虚数部分的情况除外)
容器类型:
字符串和空元组 值相同,id一致
列表、元组、字典、集合 id永不相同
(2)不同文件,部分数据驻留小数据池中(仅对python3.6)
小数据池只针对:int、str、bool、空元组()、None关键字 这些数据类型有效
●int: python在内存中创建了 -5 ~ 255 范围的整数,提前驻留在了内存的一块区域,如果是不同的文件(模块)的两个变量,声明同一个值,id一致,让两个变量的值都同时指向一个值的地址,节省空间。
●str:
1. 字符串的长度为 0 或者 1 ,默认驻留小数据池;
2. 字符串长度大于1,且只含有大小写字母、数字、下划线时,默认驻留小数据池;
3. 用 * 号得到的字符串:
1)乘数等于 1 时,无论什么字符串 * 1,都默认驻留小数据池;
2)乘数大于 1 时,仅包含数字、字母、下划线时会被缓存,但字符串长度不能大于20
●指定驻留:
从 sys 模块中导入 intern函数,让两个变量指向同一个值。
from sys import intern
a = intern("爱情公寓&&&………………%%%¥¥¥121212"*10)
b = intern("爱情公寓&&&………………%%%¥¥¥121212"*10)
print(a is b)
7. 小数据池
小数据池,不同代码块的缓存机制,也称为小整数缓存机制,或驻留机制。
前提条件:在不同一个代码块中
适用对象:int(float)、str、bool
用法:同 6.2
8. 代码块
(1)Python代码块是由代码块组成的,块是一个Python程序的文本,它是作为一个单元执行的。
(2)代码块:
一个模块、一个函数、一个类、一个文件都是代码块;
作为交互方式输入的每个命令也都是一个代码块(cmd进入Python解释器,每一行代码就是一个代码块);
对于一个文件中的两个函数,分别是两个不同的代码块。
(3)代码块的缓存机制(前提条件:在同一个代码块中):
python在执行同一个代码块的初始化对象的命令时,会检查是否其值是否已经存在,如果存在,会将其重用。也就是说:执行同一个代码块时,遇到初始化对象的命令时,会将初始化的这个变量与值存储在一个字典中,在遇到新的变量是,会先在字典中查询记录,如果有相同的记录那么会复用使用这个字典中的之前的这个值,即满足缓存机制时在内存中只存在一个值,即id是相同的。
(4)适用对象:int、str、bool
(5)缓存机制规则:
int(float):任何数字在同一个代码块中都会复用;
bool:True 和 False 在字典中都会以 1 和 0 的方式存在,并且复用;
str:几乎所有的字符串都会符合缓存机制;
1. 非乘法得到的字符串都满足代码块的缓存机制;
2. 乘法得到的字符串:
(1)乘数为 1 时,任何字符串满足代码块的缓存机制
(2)乘数大于 1 时,仅包含大小写字母、数字、下划线,且总长度不大于20,满足代码块的缓存机制
优点:能够提高一些字符串、整数处理任务在时间和空间上的性能;需要值相同的字符串、整数的时候,直接从‘字典’中取出复用,避免频繁的创建和销毁,提升效率,节约内存。
9. 流程控制
(1)顺序结构:默认代码从上到下依次执行
(2)分支结构:
单项分支:if ...code
双向分支:if code1 else: code2
多项分支:if code1 elif code2 elif code3 ...
巢状分支:单项分支、双向分支、多项分支的相互嵌套
(3)循环结构:for ... in ... / while ...
10. 关键字
(1)pass:代码占位符
(2)break:终止当前循环(只用在循环中)
(3)continue:跳过当前循环,从下一个循环继续执行
三. Python基础2--基础数据类型
1. 字符串 str
(1)拼接:+
(2)重复:‘abc’ * num
(3)跨行拼接:\
(4)索引:从 0 开始
(5)切片:
[开始索引:]:从开始索引截取到最后
[:结束索引]:从开头截取到结束索引-1
[开始索引:结束索引]:从开始索引截取到结束索引-1
[开始索引:结束索引:间隔值]:从开始索引截取到结束索引-1,并且间隔指定的间隔值
[:]或[::]:截取全部
1.1 字符串格式化 format
(1)顺序传参
(2)索引传参
(3)关键字传参
(4)容器类型数据(列表和元组)传参
(5)format 的填充符号的使用(^ > <)
(6)进制转换等特殊符号的使用( :d :f :s :,)
1.2 字符串函数
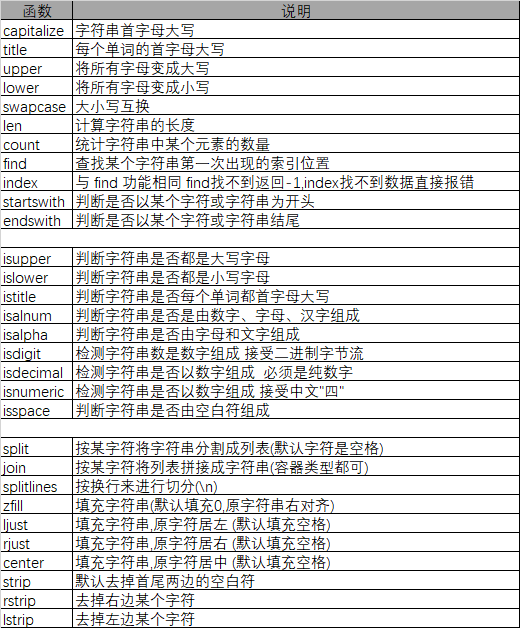
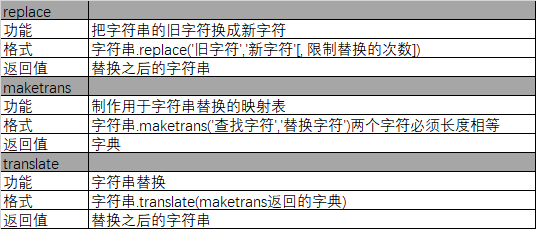
2. 列表 list
(1)拼接:+
(2)重复:*
(3)切片:(同字符串)
(4)查询:(可切片)
(5)修改:(可切片)
(6)删除:(可切片)
2.1 列表函数
新增:
append:向列表末尾添加元素
insert:在指定索引之前插入元素 insert(索引,值)
extend:迭代添加所有元素
删除:
pop:通过指定索引删除元素 pop(索引)
remove:通过指定的值删除 remove(值)
clear:清空列表
查询:
index:获取某个值的索引 列表.index(值,start,end)
count:统计某个元素出现的次数
sort:排序(默认从小到大) 列表.sort(reverse=False)
reverse:反转列表 列表.reverse()
3. 元组 tuple
不能修改和不能删除,其他同列表
index:(同列表)
count:(同列表)
4. 字典 dict
新增:
fromkeys: 使用一组键和默认值创建字典
删除:
pop : 通过键去删除键值对 若没有该键可设置默认值,预防报错
popitem : 删除最后一个键值对
clear : 清空字典
更新:
update : 批量更新有该键就更新,没该键就添加
查询:
get : 通过键获取值若没有该键可设置默认值,预防报错
keys : 将字典的键组成新的可迭代对象
values : 将字典中的值组成新的可迭代对象
items : 将字典的键值对凑成一个个元组,组成新的可迭代对象
5. 集合 set
新增:
add:向集合中添加数据
update:迭代着增加
删除:
clear:清空集合
pop:随机删除集合中的一个数据
remove:删除集合中指定的值(不存在则报错)
discard:删除集合中指定的值(不存在不删除,推荐)
集合的交叉并补:
intersection:交集
difference:差集
union:并集
symmetric_difference:对称差集
issubset:判断是否是子集
issuperset:判断是否是父集
isdisjoint:判断两个集合是否互不相交 不相交:True 相交:False
冰冻集合:
frozenset:强转容器类型数据变为冰冻集合
冰冻集合一旦创建,不能再进行任何修改,只能做交叉并补操作

 浙公网安备 33010602011771号
浙公网安备 33010602011771号