

pandas处理重复、NaN数据及读取excel空值
1.删除重复的数据
df.drop_duplicates();默认删除完全一样的行数据。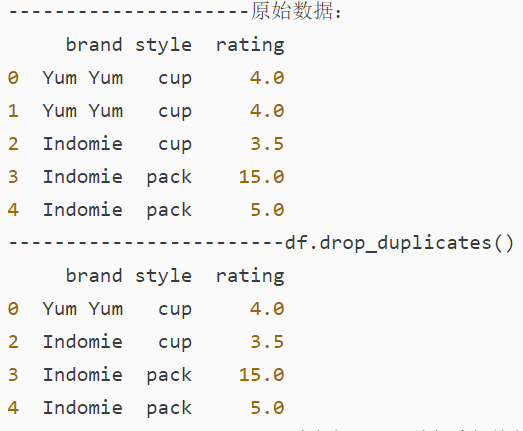
2.删除NaN数据
df.dropna() ;默认删除掉行数据,只要一行中有NaN;
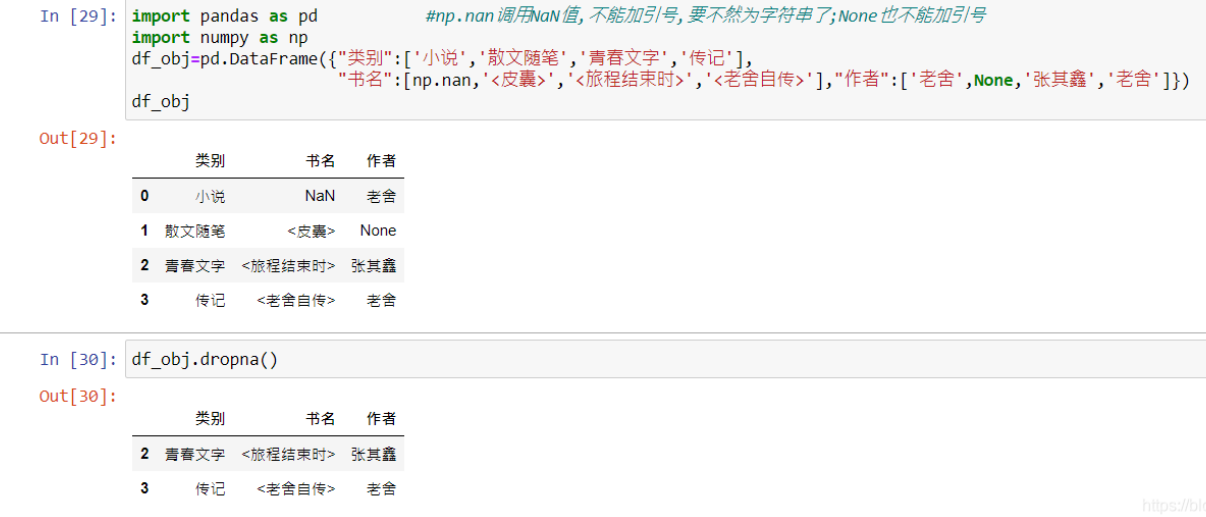

3.pandas读取excel空白单元格默认设置修改
pandas读取excel表格空值为NaN;用df.fillna没有效果。原因是pandas默认读取空字符串时读出的是nan,在使用pandas.read_excel(file)这个方法时可以在后面加上keep_default_na=False,这样读取到空字符串时读出的就是”而不是nan了。
df = pd.read_excel(data_path, keep_default_na=False)
分类:
pandas数据分析


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
2018-07-18 zabbix报错listener failed: zbx_tcp_listen() fatal error: unable to serve on any address
2018-07-18 shell脚本中执行mysql 语句,去除warning using a password on the command line interface can be insecure信息
2018-07-18 zabbix_get :command not found 解决办法
2018-07-18 CentOS7 升级到7.4
2018-07-18 jumpserver v0.5.0 创建用户和管理机器
2017-07-18 linux下双网卡的绑定