
由一次slow-request浅谈Ceph scrub原理
01背 景 介 绍
Ceph是一款开源分布式存储系统,其具有丰富的功能和高可靠、高扩展性,并且提供统一存储服务,既支持块存储RBD,也支持对象存储RadosGW和文件系统CephFS,被广泛应用在私有云等企业存储场景。
在京东数科内部,Ceph也被广泛应用,用来支撑公司基础存储需求,并且支撑部分关键业务,随着数据量和集群规模逐渐扩大,在日常维护中,我们经常遇到各种异常情况,其中频次较多的就是慢请求slow-request,慢请求会导致性能抖动,直接影响集群的稳定性,需要谨慎对待。前段时间我们再一次遇到slow-request,问题比较典型,主要和scrub有关,现将该问题的定位过程以及scrub相关的原理优化整理如下,本文内容都是基于Luminous版本。
02 Slow-request问题说明
1.问题分析
某晚19:13左右接到手机slow-request告警:个别请求响应时间比较高,有50s左右,之后登陆上机器查看集群状态,见下图:
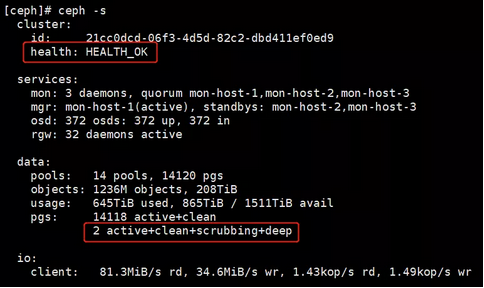
图1 Ceph健康状态
集群状态是OK的,仅发现了有两个pg正在做deep-scrub(Ceph静默检查程序,主要用来检查pg中对象数据不一致,本文后续章节有详细介绍),这两个pg属于业务数据pool(对象元数据、对象数据、日志等数据是存储在不同的pool中的),另外,发现运行scrub的时间段是23:00~06:00。
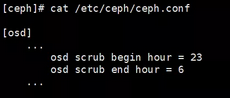
图2 Ceph配置文件
报警时间和scrub的运行时间是对得上的,从pg对应的osd日志上也能确认这一点:
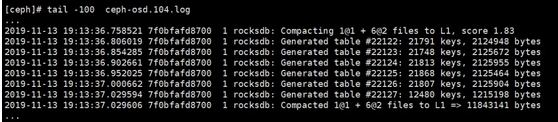
图3 Ceph osd日志
可以看到rocksdb正在进行compacting,说明业务写请求比较多。
所以可确定本次slow-request的原因:大量的用户写入操作导致rocksdb进行compacting,加上deep-scrub进一步引发底层IO资源的竞争,最终导致用户请求超时。
2.问题解决
当时紧急处理方法就是将deep-scrub关掉,后续慢请求就不再出现了。但是deep-scrub直接影响数据的一致性,不能一直关掉,我们优化的思路就是控制deep-scrub的速度和调整其运行时间,本文后续章节会有详细说明,这里就不再展开。
03Ceph scrub简述
Scrub主要是为了检查磁盘数据的静默错误,在英文中被称为:Silent Data Corruption,大家都知道硬盘最核心的使命是正确的读取和写入数据,在读、写失败的情况下及时抛出异常,但是在某些场景下,写入成功,读取的时候才发现数据已经损坏,这就是静默错误,一般静默错误产生原因有这几种:
-
硬件错误
-
传输过程信噪干扰
-
软件bug
-
固件bug
Ceph的scrub类似于文件系统的 fsck,对于每个 pg,Ceph生成所有对象的列表,并比较每个对象多个副本,以确保没有对象丢失或数据不一致。Ceph的scrub主要分两种:
(1)Scrub:对比对象各个副本的元数据来检查元数据的一致性;
(2)Deep scrub:检查对象各个副本数据内容是否一致,耗时长,占用IO资源多;
scrub 对于数据一致性十分重要,但是由上文可知,它会对集群的性能会带来一些负面的影响,主要是会和业务IO竞争资源。下面首先分析下scrub的基本原理,然后介绍具体的优化方案。
04Ceph scrub原理
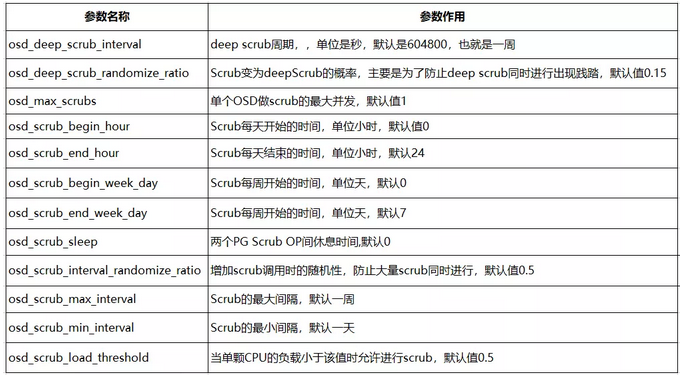
1.Scrub参数说明
在分析代码前,首先说明一下Ceph比较重要的概念和一些常用的参数。

以上是Ceph中重要的组件和概念,下面是scrub常用的参数:
下面介绍scrub的详细流程,scrub是一个生产者消费者模型,生产者生成scrub job,消费者负责消费scrub job。
2.Scrub任务的产生
生产者由定时任务触发,具体流程如下:
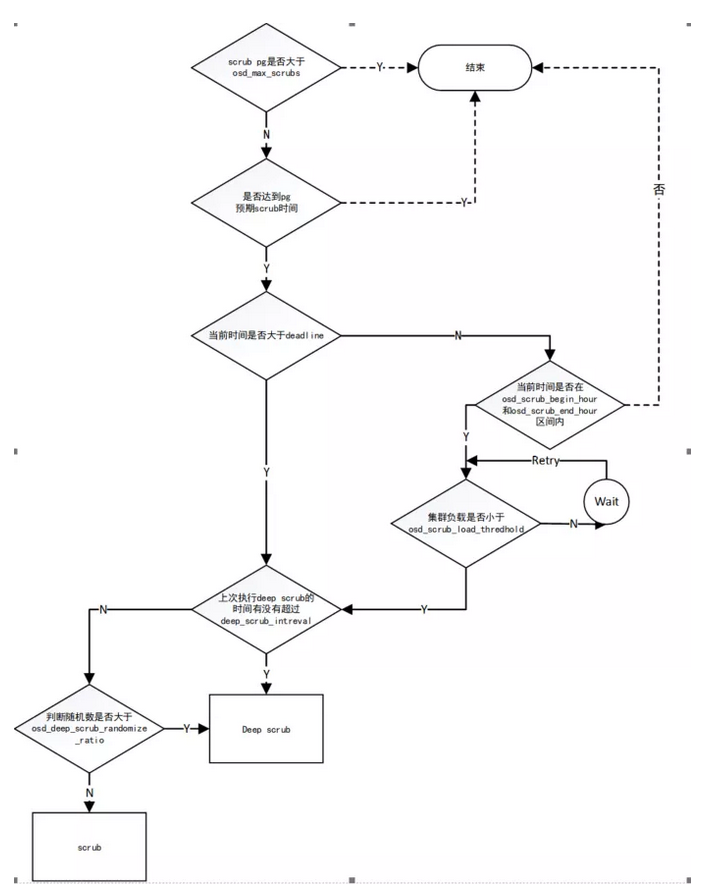
图4 生产者流程
主要流程说明如下:
(1)首先判断osd正在执行scrub的pg数是否大于osd_max_scrubs,如果大于则返回;
(2)是否达到pg的预期scrub时间,如果没达到则返回,预期的scrub时间是由上次scrub的时间、osd_scrub_min_interval、osd_scrub_interval_randomize_ratio参数决定;
(3)判断当前时间是否大于deadline,如果小于,则判断是否在osd_scrub_begin_hour和osd_scrub_end_hour,如果处于则判断集群负载是否在osd_scrub_load_thredhold之下,如果不满足则等待时间再重试。如果当前时间大于deadline,则不会判断时间和负载,强制执行scrub任务,到这一步仍然是osd_scrub_min_interval和osd_scrub_max_interval起作用;
(4)一个scrub任务最后会经过判断,从而决定这个scrub任务到底是scrub还是deepscrub,接下来我来分析一下这个判断流程;
(5)在主osd判断deep scrub的时间有没有超过deep_scrub_interval,如果超过,这个任务会是deep scrub;
scrubber.time_for_deep =ceph_clock_now() >=
info.history.last_deep_scrub_stamp+ deep_scrub_interval;
(6)如果没过期,这时osd_deep_scrub_randomize_ratio这个参数会起作用:
deep_coin_flip = (rand()% 100) < cct->_conf->osd_deep_scrub_randomize_ratio* 100;
scrubber.time_for_deep= (scrubber.time_for_deep || deep_coin_flip);
(7)首先判断osd正在执行scrub的pg数是否大于osd_max_scrubs,如果大于则返回;
(8)之后就是具体将任务加到队列,这里是用统一的数据结构表示scrub和deep scrub任务;
(9)获取deep scrub和scrub的标志位,如果设置了no deep scrub或者no scrub,则不执行相应任务。
从代码中看到的几个细节:
(1)预期的scrub时间,是由 last_scrub_time + min_interval + random_postpone_time,从而错开了pg的开始时间,这里起到了消峰的作用,并且随着系统的运行,这个时间是会错开的:
sched_time += scrub_min_interval;
double r = rand() / (double)RAND_MAX;
sched_time += scrub_min_interval *cct->_conf->osd_scrub_interval_randomize_ratio * r;
deadline += scrub_max_interval;
(2)last_scrub_time + osd_scrub_max_interval作为deadline,所以如果osd_scrub_max_interval设置的不对,就会导致系统在业务的正常时间出现deep scrub和scrub,并且不会受到load thredhold的限制;
(3)osd_deep_scrub_randomize_ratio这个参数会把普通的scrub任务变成deep scrub任务,但是只要max interval设置的合理,是有均衡deep scrub任务的作用的。
3.Scrub任务的消费
消费者是由线程池控制,具体流程如下:

图5 消费者流程
(1)由前文可知,scrub是已pg为单位的,而每个PG的scrub启动是由该PG所在的主OSD启动执行;(2)在比较大的集群规模下,每个PG中可能承载了几十万的对象数,在进行scrub过程中会根据对象名的哈希值的部分作为提取因子,选择一部分对象进行校验,这部分被选中的对象称为chunky,这也是为什么ceph被称为chunkyscrub的原因;(3)scrub的发起者即pg所在的主OSD,向其它副本OSD发起进行数据校验的消息,根据scrub的类型不同,需要校验的数据也不同:
-
scrub 读取对象的元数据信息,检查对象是否一致
-
deep scrub 读取对象的数据并做checksum来检查数据是否一致
(4)校验信息统一放到ScrubMap中,发起者通过比较ScrubMap中的信息,判断对象是否一致,不一致的信息会上报给monitor。
从流程也可以看出几个细节:
(1)chunky scrub里面的object会被锁住,写请求受到影响;
(2)osd_scrub_sleep是控制两次chunkyscrub的间隔,从而会拉长一次scrub(这里包括deepscrub 和 scrub)的时间,睡眠是通过定时器实现的。
05Ceph scrub优化
了解了scrub的原理,下面从如下两个方面来进行介绍scrub优化方案,一种是调整Ceph的相关参数,一种是自研的scrub调度策略。
1.参数优化
首先,可以解决之前的几个迷惑的问题:
(1)针对正在执行的scrub任务,即便时间超过配置的osd_scrub_end_hour 后,仍然会执行,新的任务在OSD::sched_scrub()开始时 OSD::scrub_time_permit返回 false不会执行;
(2)如果osd_scrub_max_interval配置的不合理,则会导致scrub任务的deadline超出,那么就会导致在规定时间外的任意时间出现scrub/deep scrub,从而影响业务IO;
(3)一个scrub任务到底是deep还是普通的scrub,和osd_deep_scrub_interval还有osd_deep_scrub_randomize_ratio参数有关,超过osd_deep_scrub_interval的一定是deep,否则按照osd_deep_scrub_randomize_ratio对应的概率转换成deep;
(4)不管是deep还是shallow scrub任务,执行的逻辑都是一样的,函数也一样,状态机也一样,唯一不同的是ScrubMap如果是deep会额外的请求CRC校验值。
其次,可以总结出参数调优的主要方向:(1)首先,确定osd_scrub_max_interval,这个时间很重要,如果设置的太小就会导致业务在正常时间IO受到影响,并且此时osd_scrub_load_thredhold、begin
hour、end hour都不会生效,osd_scrub_sleep时间生效。通过ceph pg dump --format json |
jq -r '.pg_stats[] | [.last_clean_scrub_stamp ] | @csv' | sort
–r命令查看线上环境,可以看到较多scrub任务在设置的scrub时间之外执行,所以这个参数需要调整,调整到一个月之后,没有出现类似现象;(2)其次,osd_scrub_end_hour的设置,如果业务7点开始使用,那么如果设置成7点,可能最后一个任务没有执行完,deep scrub任务会持续到7点之后,具体取决于最后一个pg scrub的执行时间,那么这个值可以再提前一点;(3)然后,osd_scrub_load_threshold的设置,这个值默认0.5,假如在begin
hour和endhour之间,如果cpu高于这个值,那么是不会执行scrub的,这个值太小会导致在正常规定时间不能执行scrub,从而影响deadline,一旦超过deadline会出现第一种情况;(4)bucket
index对应的shard对象不宜过大,如果太大,这个对象在执行deep
scrub的时候,会影响bucket级别的对象无法写入。这个参数通过修改osd_scrub_chunk_min,osd_scrub_chunk_max,可以缓解但是如果一个shard对象太多,仍然会比较严重;(5)osd_scrub_sleep参数可以降低客户端在scrub时间内的感知,代价是增加了一次scrub任务的时间,所以如果修改这个参数,仍然需要确保一个osd_scrub_max_interval周期里,所有的pg能够被正确执行完scrub任务。
总结一下,总体的优化思路就是首先确保scrub任务不会在osd_scrub_begin_hour和 osd_scrub_end_hour之外的时间执行,其次就是在osd_scrub_begin_hour和osd_scrub_end_hour之间,尽可能减少业务的感知。
2.调度优化
由上文的分析可知,通过调整参数,可以解决一部分问题,但是如果某些参数设置的不合理,仍然会导致在scrub任务在非规定的时间内运行,影响正常的任务,scrub可控性仍然存在一些问题,并且在618和双11大促期间,需要完全避免执行scrub任务。针对这种情况,关闭使用ceph osd set noscrub;ceph osd set nodeep-scrub命令关闭了ceph的scrub机制,采用了自研程序进行scrub任务调度。
图6 scrub调度流程
主要的逻辑说明:
(1)通过rados连接ceph集群,如果连接失败则返回对应错误信息;
(2)进入循环主流程,判断当前日期是否是特殊日期,例如618,双11,如果是则睡眠一定时间继续循环;
(3)检查执行时间和最大任务数是否满足执行条件,如果不满足,则睡眠等待下一轮检查,一般都会设置deep scrub时间范围为晚上23点到第二天早上7点;
(4)通过pg dump获取当前正在执行scrub的pg信息;
(5)如果当前执行scrub的任务数大于所设置的maxscrubs,则睡眠一段时间继续循环
(6)对于非scrubbing状态的PG,按照last_deep_scrub_stamp从远及近排序,作为备选PG组;
(7)循环检查备选PG,对满足以下条件的PG执行deep scrub操作:
-
PG的last_deep_scrub_stamp在1周之前;
-
PG的主osd不处于scrubbing状态;
-
当前deep scrub任务小于最大任务数;
(8)如果当前deep scrub任务达到最大任务数,跳出循环。
(9)睡眠等待下一轮检查。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 因为Apifox不支持离线,我果断选择了Apipost!
· 通过 API 将Deepseek响应流式内容输出到前端