
执行 yarn application 连接失败且超时的错误解决
在AWS EMR使用多个Master高可用部署场景下,需要创建3台Master节点上。登录到其中一台节点,运行如下命令:
yarn application -list在某些场景下会遇到如下报错。报错信息:
WARN ipc.Client: Failed to connect to server: ip-172-31-22-134.cn-northwest-1.compute.internal/172.31.22.134:8032: retries get failed due to exceeded maximum allowed retries number: 0
java.net.ConnectException: Connection refused
错误场景如下截图。
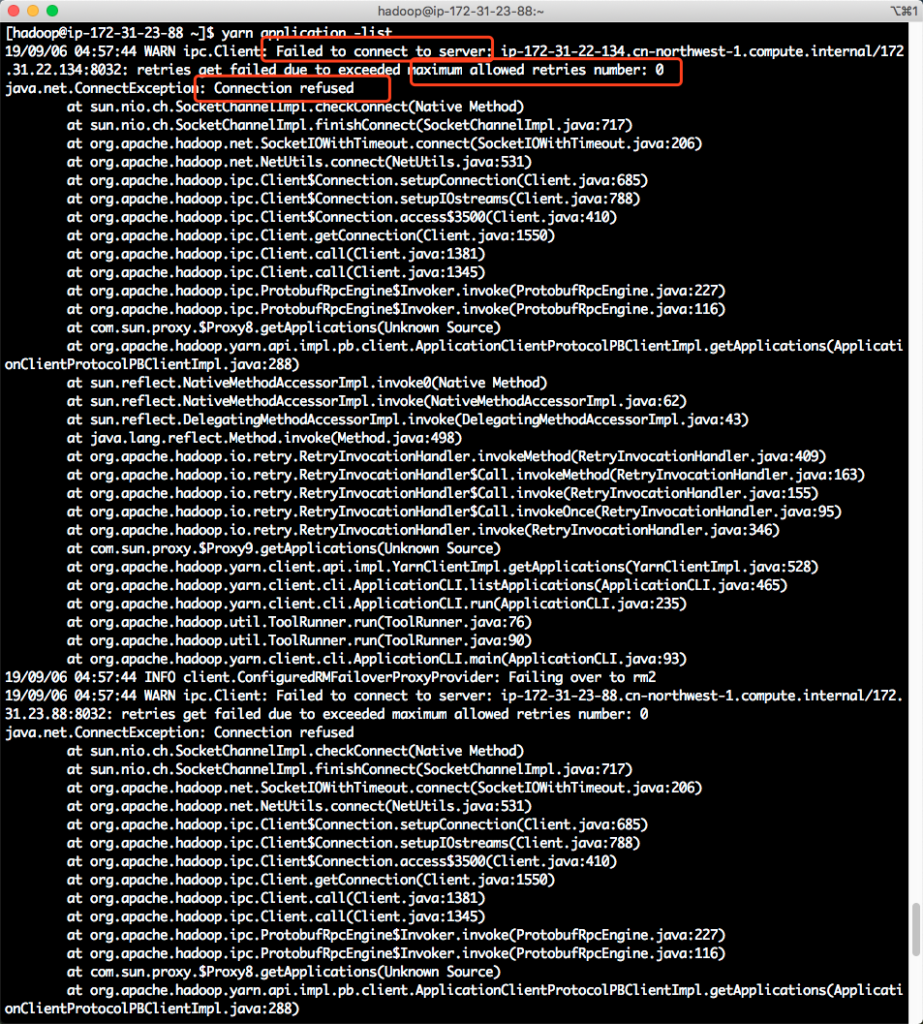
不过在等待一段时间后,也可以看到yarn返回了最终的输出。如下截图。
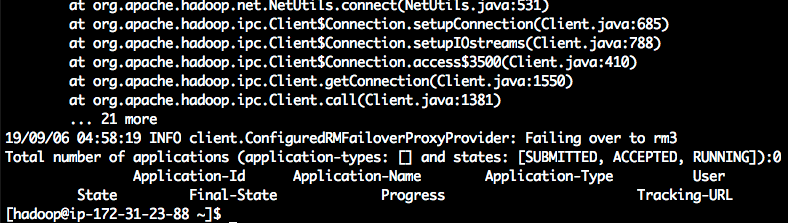
造成这个问题是因为EMR开启了多Master部署,有三台Master节点,分别叫做rm1、rm2、rm3。当前登录的节点可能是rm1,运行yarn查询的时候默认先查询rm1。但是,整个集群的master已经切换走了,rm1并不是master角色,所以yarn会反复查询失败,然后去轮询到下一个节点rm2,继续失败,最后在rm3节点查询完成。
接下来验证下,当前的集群中谁是master节点。执行如下命令:
yarn rmadmin -getAllServiceState执行效果如下截图。
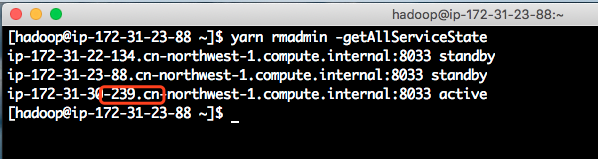
可以从如上命令看出,IP结尾是239的才是master节点。那么这个239节点是否在yarn查询列表的第一位呢?还是排在最后一位?
编辑如下配置文件:
sudo vim /etc/hadoop/conf.empty/yarn-site.xml查看里边的resource manager的顺序如下:
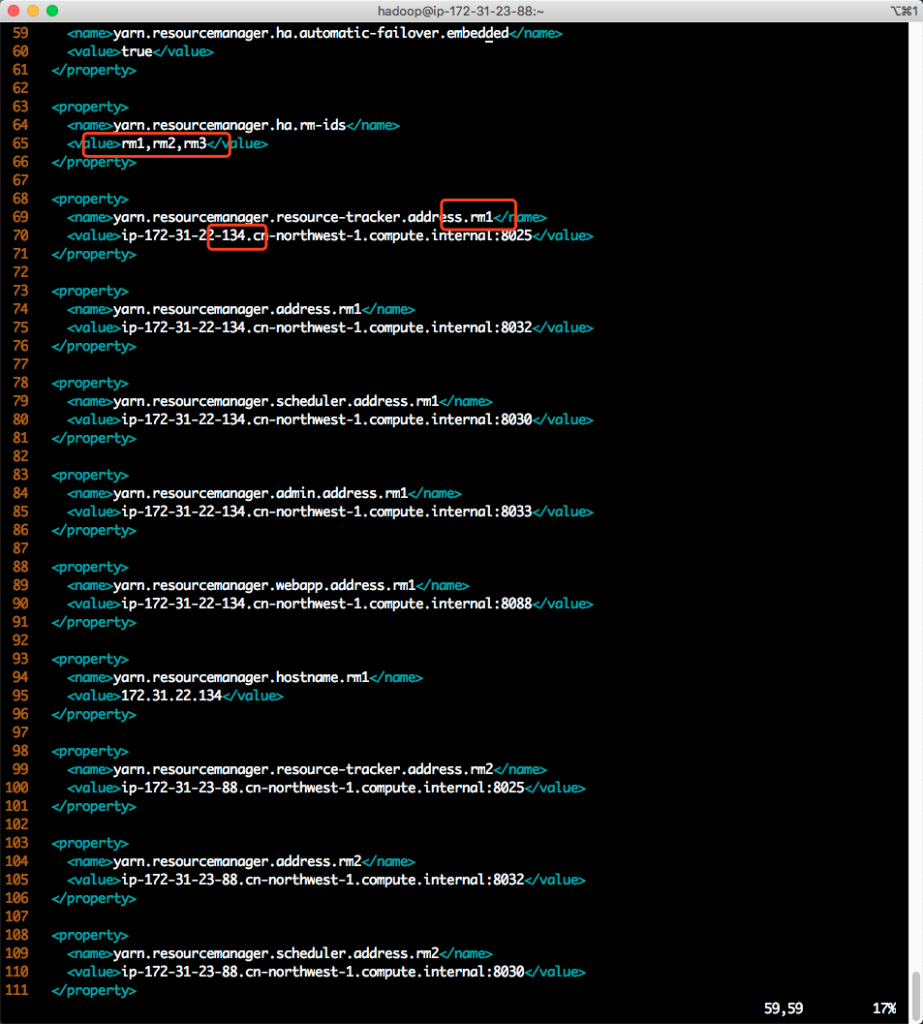
如上截图可以看到,顺序是rm1、rm2、rm3,而rm1对应的IP并不是当前的master节点。所以才有了这个查询失败。
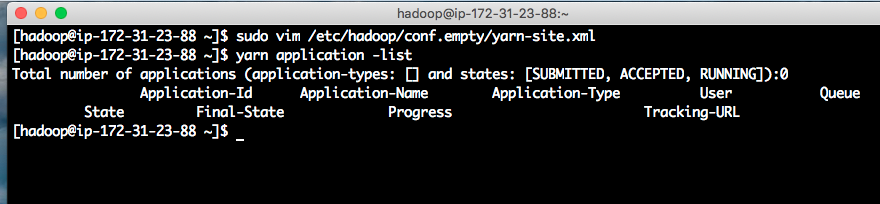
解决办法:把顺序改成rm3、rm2、rm1。改完后,再运行yarn,就没有报错了。如下截图。
至此问题解决。
分类:
hadoop


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 因为Apifox不支持离线,我果断选择了Apipost!
· 通过 API 将Deepseek响应流式内容输出到前端
2018-08-31 SQL truncate/delete/drop 区别