TinaLinux NPU开发
TinyVision V851s 使用 OpenCV + NPU 实现 Mobilenet v2 物体识别。上一篇已经介绍了如何使用 TinyVision 与 OpenCV 开摄像头,本篇将使用已经训练完成并且转换后的模型来介绍对接 NPU 实现物体识别的功能。
MobileNet V2
MobileNet V2是一种轻量级的卷积神经网络(CNN)架构,专门设计用于在移动设备和嵌入式设备上进行计算资源受限的实时图像分类和目标检测任务。
以下是MobileNet V2的一些关键特点和创新之处:
-
Depthwise Separable Convolution(深度可分离卷积):MobileNet V2使用了深度可分离卷积,将标准卷积分解为两个步骤:depthwise convolution(深度卷积)和pointwise convolution(逐点卷积)。这种分解方式可以显著减少计算量和参数数量,从而提高模型的轻量化程度。
-
Inverted Residuals with Linear Bottlenecks(带线性瓶颈的倒残差结构):MobileNet V2引入了带有线性瓶颈的倒残差结构,以增加模型的非线性表示能力。这种结构在每个残差块的中间层采用较低维度的逐点卷积来减少计算量,并使用扩张卷积来增加感受野,使网络能够更好地捕捉图像中的细节和全局信息。
-
Width Multiplier(宽度乘数):MobileNet V2提供了一个宽度乘数参数,可以根据计算资源的限制来调整模型的宽度。通过减少每个层的通道数,可以进一步减小模型的体积和计算量,适应不同的设备和应用场景。
-
Linear Bottlenecks(线性瓶颈):为了减少非线性激活函数对模型性能的影响,MobileNet V2使用线性激活函数来缓解梯度消失问题。这种线性激活函数在倒残差结构的中间层中使用,有助于提高模型的收敛速度和稳定性。
总体而言,MobileNet V2通过深度可分离卷积、倒残差结构和宽度乘数等技术,实现了较高的模型轻量化程度和计算效率,使其成为在资源受限的移动设备上进行实时图像分类和目标检测的理想选择。
NPU
V851s 芯片内置一颗 NPU,其处理性能为最大 0.5 TOPS 并有 128KB 内部高速缓存用于高速数据交换
NPU 系统架构
NPU 的系统架构如下图所示:
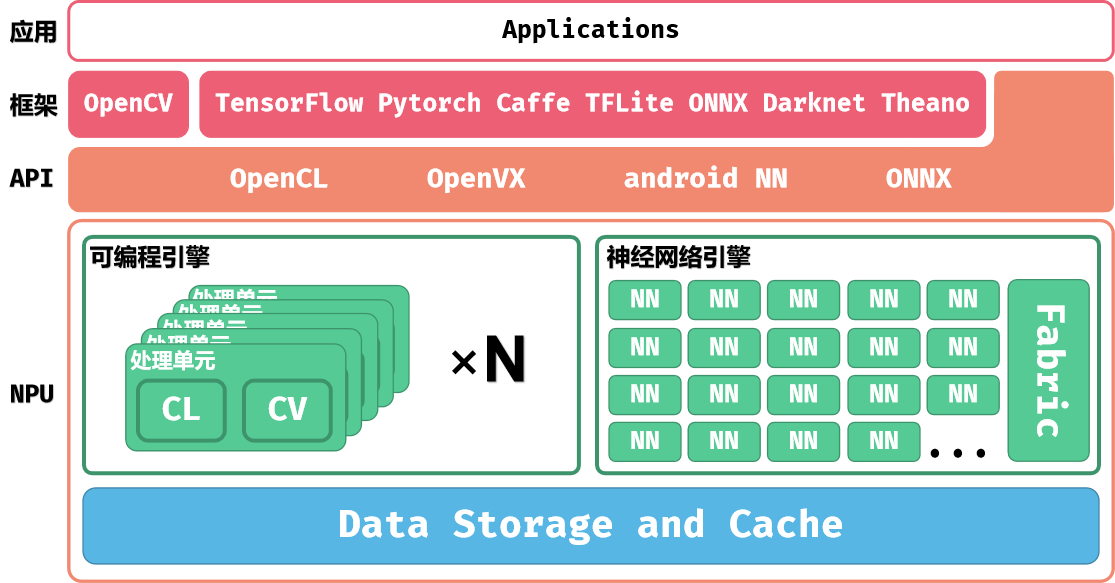
上层的应用程序可以通过加载模型与数据到 NPU 进行计算,也可以使用 NPU 提供的软件 API 操作 NPU 执行计算。
NPU包括三个部分:可编程引擎(Programmable Engines,PPU)、神经网络引擎(Neural Network Engine,NN)和各级缓存。
可编程引擎可以使用 EVIS 硬件加速指令与 Shader 语言进行编程,也可以实现激活函数等操作。
神经网络引擎包含 NN 核心与 Tensor Process Fabric(TPF,图中简写为 Fabric) 两个部分。NN核心一般计算卷积操作, Tensor Process Fabric 则是作为 NN 核心中的高速数据交换的通路。算子是由可编程引擎与神经网络引擎共同实现的。
NPU 支持 UINT8,INT8,INT16 三种数据格式。
NPU 模型转换
NPU 使用的模型是 NPU 自定义的一类模型结构,不能直接将网络训练出的模型直接导入 NPU 进行计算。这就需要将网络训练出的转换模型到 NPU 的模型上。
NPU 的模型转换步骤如下图所示:
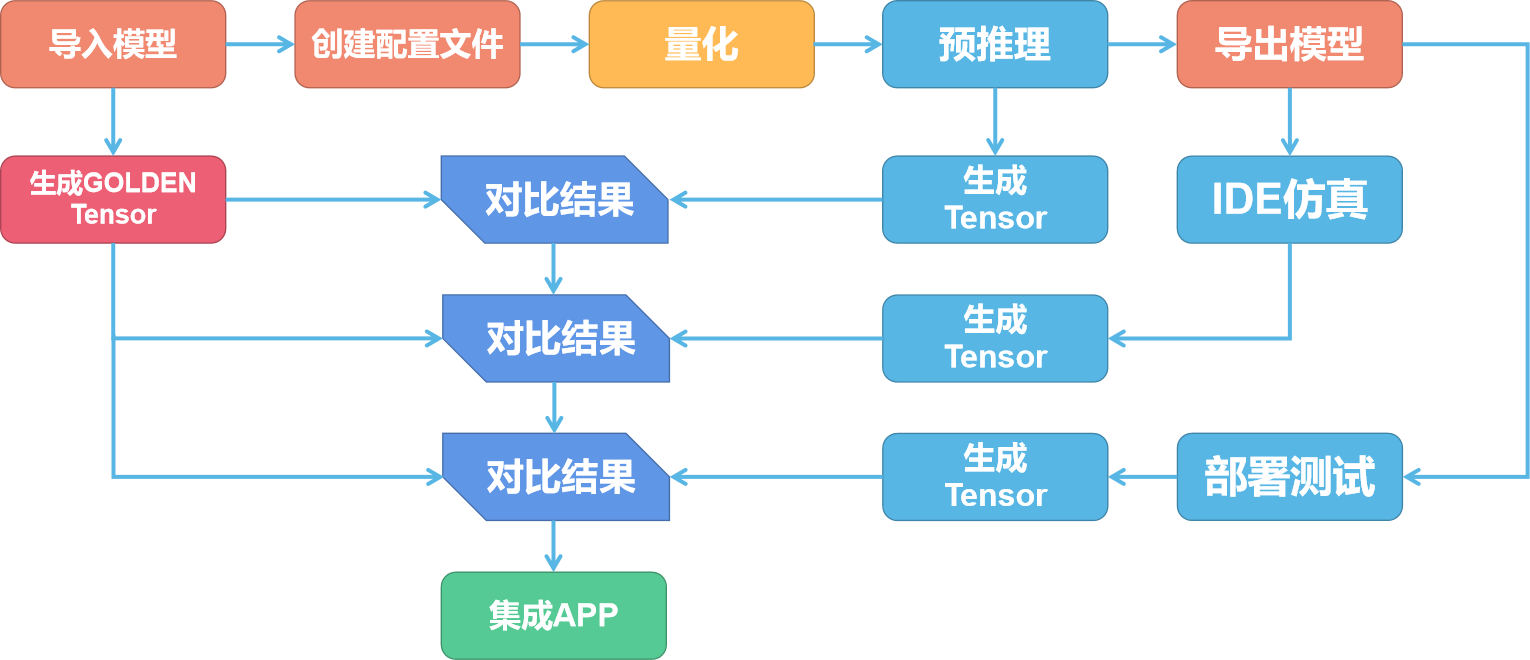
NPU 模型转换包括准备阶段、量化阶段与验证阶段。
准备阶段
首先我们把准备好模型使用工具导入,并创建配置文件。
这时候工具会把模型导入并转换为 NPU 所使用的网络模型、权重模型与配置文件。
配置文件用于对网络的输入和输出的参数进行描述以及配置。这些参数包括输入/输出 tensor 的形状、归一化系数 (均值/零点)、图像格式、tensor 的输出格式、后处理方式等等。
量化阶段
由于训练好的神经网络对数据精度以及噪声的不敏感,因此可以通过量化将参数从浮点数转换为定点数。这样做有两个优点:
(1)减少了数据量,进而可以使用容量更小的存储设备,节省了成本;
(2)由于数据量减少,浮点转化为定点数也大大降低了系统的计算量,也提高了计算的速度。
但是量化也有一个致命缺陷——会导致精度的丢失。
由于浮点数转换为定点数时会大大降低数据量,导致实际的权重参数准确度降低。在简单的网络里这不是什么大问题,但是如果是复杂的多层多模型的网络,每一层微小的误差都会导致最终数据的错误。
那么,可以不量化直接使用原来的数据吗?当然是可以的。
但是由于使用的是浮点数,无法将数据导入到只支持定点运算的 NN 核心进行计算,这就需要可编程引擎来代替 NN 核进行计算,这样可以大大降低运算效率。
另外,在进行量化过程时,不仅对参数进行了量化,也会对输入输出的数据进行量化。如果模型没有输入数据,就不知道输入输出的数据范围。这时候我们就需要准备一些具有代表性的输入来参与量化。这些输入数据一般从训练模型的数据集里获得,例如图片数据集里的图片。
另外选择的数据集不一定要把所有训练数据全部加入量化,通常我们选择几百张能够代表所有场景的输入数据就即可。理论上说,量化数据放入得越多,量化后精度可能更好,但是到达一定阈值后效果增长将会非常缓慢甚至不再增长。
验证阶段
由于上一阶段对模型进行了量化导致了精度的丢失,就需要对每个阶段的模型进行验证,对比结果是否一致。
首先我们需要使用非量化情况下的模型运行生成每一层的 tensor 作为 Golden tensor。输入的数据可以是数据集中的任意一个数据。然后量化后使用预推理相同的数据再次输出一次 tensor,对比这一次输出的每一层的 tensor 与 Golden tensor 的差别。
如果差别较大可以尝试更换量化模型和量化方式。差别不大即可使用 IDE 进行仿真。也可以直接部署到 V851s 上进行测试。
此时测试同样会输出 tensor 数据,对比这一次输出的每一层的 tensor 与 Golden tensor 的差别,差别不大即可集成到 APP 中了。
NPU 的开发流程
NPU 开发完整的流程如下图所示:
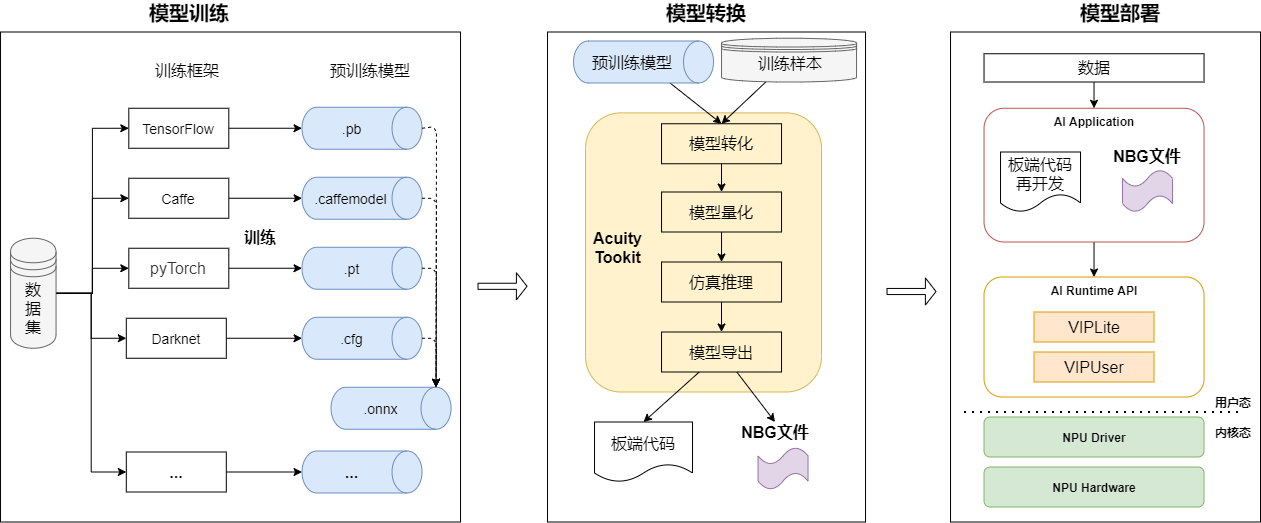
模型训练
在模型训练阶段,用户根据需求和实际情况选择合适的框架(如Caffe、TensorFlow 等)使用数据集进行训练得到符合需求的模型,此模型可称为预训练模型。也可直接使用已经训练好的模型。V851s 的 NPU 支持包括分类、检测、跟踪、人脸、姿态估计、分割、深度、语音、像素处理等各个场景90 多个公开模型。
模型转换
在模型转化阶段,通过Acuity Toolkit 把预训练模型和少量训练数据转换为NPU 可用的模型NBG文件。 一般步骤如下:
- 模型导入,生成网络结构文件、网络权重文件、输入描述文件和输出描述文件。
- 模型量化,生成量化描述文件和熵值文件,可改用不同的量化方式。
- 仿真推理,可逐一对比float 和其他量化精度的仿真结果的相似度,评估量化后的精度是否满足要求。
- 模型导出,生成端侧代码和*.nb 文件,可编辑输出描述文件的配置,配置是否添加后处理节点等。
模型部署及应用开发
在模型部署阶段,就是基于VIPLite API 开发应用程序实现业务逻辑。
OpenCV + NPU 源码解析
完整的代码已经上传Github开源,前往以下地址:https://github.com/YuzukiHD/TinyVision/tree/main/tina/openwrt/package/thirdparty/vision/opencv_camera_mobilenet_v2_ssd/src
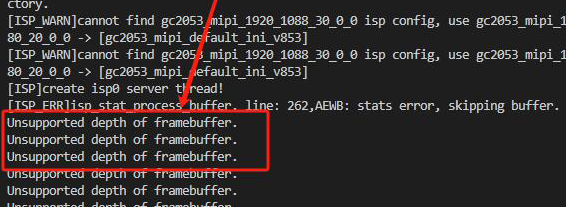
否则报错 Unsupported depth of framebuffer
Mobilenet v2 前处理
void get_input_data(const cv::Mat& sample, uint8_t* input_data, int input_h, int input_w, const float* mean, const float* scale){
cv::Mat img;
if (sample.channels() == 1)
cv::cvtColor(sample, img, cv::COLOR_GRAY2RGB);
else
cv::cvtColor(sample, img, cv::COLOR_BGR2RGB);
cv::resize(img, img, cv::Size(input_h, input_w));
uint8_t* img_data = img.data;
/* nhwc to nchw */
for (int h = 0; h < input_h; h++) {
for (int w = 0; w < input_w; w++) {
for (int c = 0; c < 3; c++) {
int in_index = h * input_w * 3 + w * 3 + c;
int out_index = c * input_h * input_w + h * input_w + w;
input_data[out_index]