Python从Web抓取信息
1.介绍
本章节将学习如下几个模块,让在Python中抓取网页变得很容易。
- webbrowser:是Python自带的,打开浏览器获取指定网页;
- requests:从因特网上下载文件和网页
- Beautiful Soup:解析HTML,即网页编写的格式
- selenium:启动并控制一个Web浏览器。selenium能够填写表单,并模拟鼠标在这个浏览器中点击。
2. webbrowser项目-利用webbrowser模块批量访问谷歌地图
- 从命令行参数或剪贴板中取得街道地址
- 打开web浏览器,指向该地址的Google地图页面
代码需要进行如下工作:
- 从sys.argv读取命令行参数
- 或读取剪贴板内容
- 调用webbrowser.open()函数打开外部浏览器
代码如下:
import webbrowser, sys, pyperclip if len(sys.argv) > 1: # Get address from command line. address = ' '.join(sys.argv[1:]) else: # Get address from clipboard. address = pyperclip.paste() webbrowser.open('https://www.google.com/maps/place/' + address)
3. 用requests模块从web下载文件
3.1用requestes.get()函数下载一个网页
import requests res = requests.get("https://www.baidu.com/notfound.html") try: res.raise_for_status() except BaseException as exc: print('There was a problem: %s' % (exc))
- 通过requests.get()下载网页
- 通过raise_for_status()函数判断页面是否下载成功,如果下载成功,不会做任何反映,如果下载失败,则将返回报错信息。
3.2 将下载文件保存到文件
import requests res = requests.get("https://www.gutenberg.org/cache/epub/1112/pg1112.txt") try: res.raise_for_status() with open("luomiouandjuliy.txt",'ab') as ly: for i in res.iter_content(100000): ly.write(i) except BaseException as exc: print('There was a problem: %s' % (exc))
res.iter_content返回的是下载的网页内容的列表对象,通过for循环将内容读出来并写入到文件中。
4. 用BeautifulSoup模块解析HTML
BeautifulSoup是一个模块,用于从Html页面中提取信息,BeautifulSoup模块的名称是bs4(表示第4版)需要安装他,需要在命令行运行pip install beautifulsoup4。虽然安装时使用的名字是beautifulsoup4,但是导入他,就使用import bs4.
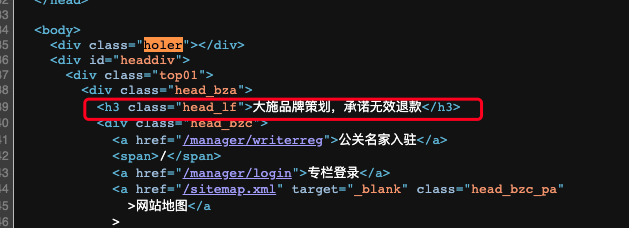
import bs4,requests res = requests.get("http://www.gongguanzhijia.com/article/5504.html") res.raise_for_status() beautful = bs4.BeautifulSoup(res.text,features="html.parser") elems = beautful.select("h3") print(str(elems[0])) print(elems[0].getText()) print(elems[0].attrs)
- requests.get()函数下载一个html网页
- 通过bs4.BeautifulSoup()函数获取html网页源码,如上截图所示
- 通过select()方法查找h3标签
- str()返回标签内容
- getText()获取标签里面数值
- attrs返回标签属性值,是一个字典
不积跬步,无以至千里;不积小流,无以成江海。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号