2021-2022-1 20211424 《信息安全专业导论》第七周学习总结
2021-2022-1 20211424 《信息安全专业导论》第七周学习总结
作业所属课程:https://edu.cnblogs.com/campus/besti/2021-2022-1fois
作业要求:https://www.cnblogs.com/rocedu/p/9577842.html#WEEK07
作业目标:
- 数组与链表
- 基于数组和基于链表实现数据结构
- 无序表与有序表
- 树
- 图
- 子程序与参数
作业正文:https://www.cnblogs.com/weidaixdrx/p/15500477.html
教材学习内容总结
#抽象数据类型(Abstract Data Type,ADT)
是属性(数据和操作)明确的与特定现实分离的容器(container)。
也就是说,我们知道操作和它们所做的事情,但是不知道操作是怎么实现的。
#栈(Stack):
是一种抽象复合结构。
处理类型为先进后出(LIFO)。
#队列(Queue):
也是抽象结构。
处理类型为先进先出(FIFO)。
#列表(List):
不要把它误认为数组,数组是内嵌结构,列表是抽象结构。
它可以被形象化为
链式结构(linked structure)
它以节点概念为基础,一个节点由两部分构成:用户的数据和指向列表的下一个节点的链接或指针。
- 无序表,顺序不重要,项目随意放入其中。
- 有序表,除了第一个项目之外所有项目都存在某种排序关系;除了最后一个项目,所有的项目都有着相同的关系。
#树(tree):
可以表示更复杂的关系。
- 二叉树(binary tree)
是一种抽象结构。
每个节点可以有两个后继节点,叫做“子女”,头部叫“根”。
如果一个节点没有子女,那它叫“树叶”,即“叶节点(leaf node)”。
- 二叉检索树
数类似于无序列表,二叉检索树就像已排序的列表,节点之前存在语义排序。
1.在二叉检索树中搜索:
info(current)指的是节点中的数据,left/right(current)指的是左/右子树的根节点。
树的形状是由项目插入树的顺序决定的。
2.构造二叉检索树:
insert(tree,item)
3.输出二叉检索树中的数据
要输出根的值,必须先输出它的左子树中的所有值,然后输出它的右子树中的所有值。
二叉检索树是和列表具有同样功能的对象,他们的区别在于操作的有效性,而行为是相同的。
#图
图中一个节点至多只有一个指向它的节点(父母),去掉这种约束,就得到了图(graph)。
图由一组节点和连接节点的线段构成,节点叫顶点(vertex),线段叫边(弧)(edge(arc)。
无向图(undirected graph):边没有方向。
有向图(directed graph(digraph)):边从一个顶点指向另一个顶点。
- 创建图
与其他容器不同,图中定义的算法可以解决实际的问题。
- 图算法
三种经典图搜索算法。
1.深度优先搜索
喜爱的航线。
用栈来存储访问的顶点。
2.广度优先搜索
最少的停顿次数。
用队列来保存元素的顺序。、
3.单元最短路搜索
优先队列(priority queue):被检索的元素是在队列中拥有最高优先度的元素。
#子程序
信息的交流是通过参数列表的概念实现的。
- 参数传递
参数列表(parameter)是子程序要使用的标识符或值的列表,它放置在子程序名后面的括号中。
- 值参(value parameter)与引用参数(reference parameter)
传递参数的基本方式有两种,通过值传递或通过引用(或地址)传递。
要访问一个引用参数,子程序必须访问留言板上地址的内容;要访问值参,只需访问留言板内容。
教材学习过程中的问题和解决过程
问题一:数组与链表的区别与各自特点不太清晰。
解决过程:在CSDN网站搜索到以下比较明了的解释:
(1)数组在内存中开辟连续的一块区域,如果一个数据要两个内存单元,一组5个数据10个单元就够了,无需标记其地址,因为数组定义时候标顶了第一个原许的地址,其他四个都知道了。
链表可可以是连续的,也可以是不连续的,但一般都是不连续的,尽管在内存中是连续的,我们也不把他当作是连续的,而是把他当作是不连续的,因为如果把他当作是连续的,不如当作是数组了,在某些情况下。一链5个数据,如果每个数据本身用2个内存单元,那么10个单元是不够的,因为每个数据都要表示出下个数据在哪里,所以一个数据本身用2个单元,再用1个单元表示此链下一个数据在什么地址。
各有用处。
(2)
代码调试中的问题数组中的数据在内存中的按顺序存储的,而链表是随机存储的!
要访问数组中的元素可以按下标索引来访问,速度比较快,如果对他进行插入操作的话,就得移动很多元素,所以对数组进行插入操作效率很低!
由于连表是随机存储的,链表在插入,删除操作上有很高的效率(相对数组),如果要访问链表中的某个元素的话,那就得从链表的头逐个遍历,直到找到所需要的元素为止,所以链表的随机访问的效率就比数组要低和解决过程。
代码调试中的问题和解决过程
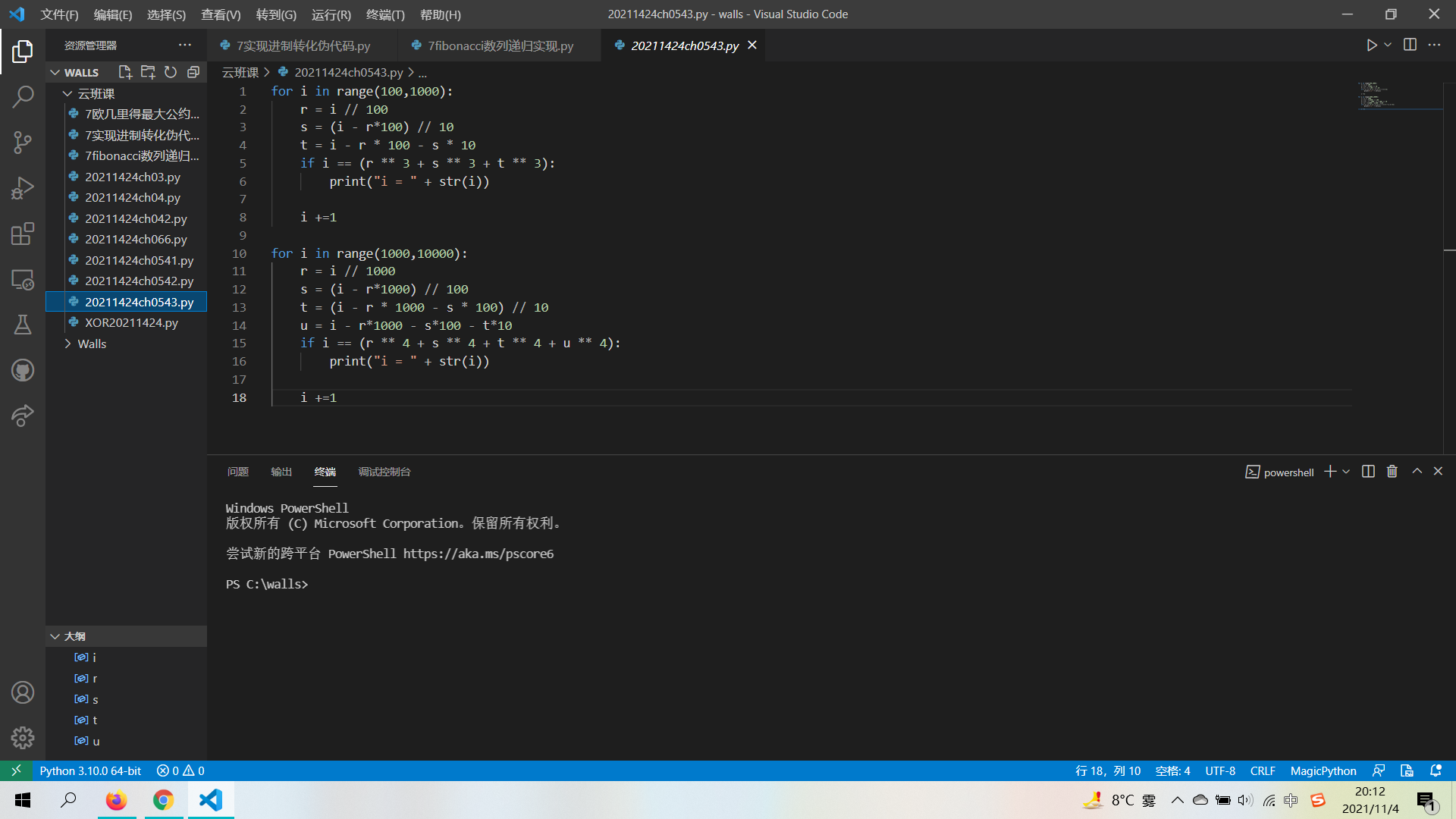
问题一:在计算三位自幂数与四位自幂数时无法直接用一串代码表示出。
解决过程:写两段代码分别进行运算
上周考试错题总结
无
学习进度条
| 代码 | 博客 | 学习时长 | 成长 | |
| 目标 | 5000 | 30 | 400 | |
| 一 | 0/0 | 2/2 | 5/5 | |
| 二 | 100/100 | 3/5 | 11/16 | |
| 三 | 200/300 | 1/6 | 8/24 | |
| 四 | 200/500 | 2/8 | 10/34 | |
| 五 | 300/800 | 4/12 | 15/49 | |
| 六 | 500/1300 | 3/15 | 13/62 | |
| 七 | 400/1700 | 4/19 | 13/75 |
计划学习时间:12
实际学习时间:13
改进情况:学习效率有所提高,要继续加油!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号